IPFS - block
IPFS block
ipfs 네트워크에 업로드 된 파일의 크기가 설정된 크기 (기본값은 256k)를 초과하면 시스템은 파일을 블록으로 분할하여 따로 저장합니다. 블록 명령은 이러한 블록을 조작하는 데 사용됩니다. 블록 명령 형식은 다음과 같습니다:
ipfs block <명령어>
다음과 같은 4 개의 하위 명령이 있습니다.
-
get <hash>: 블록 내용을 검색하고 표시 put <file>: 다음 세 가지 옵션을 사용하여 파일을 ipfs 데이터 블록에 저장- format: 새로 생성 된 블록의 cid 형식 지정
- mhtype: 여러 해시 함수 지정
- mhlen: 여러 해시 길이 지정
rm <hash>: 블록 삭제, 고정 된 블록을 삭제할 수 없으면 다음과 같은 두 가지 옵션- f: 삭제 시 존재하지 않는 블록 무시
- q: 출력 최소화 알림 메시지
stat <hash>: hash 값 및 블록 크기를 포함하여 블록에 대한 정보 표시
$ ipfs block put hello.txt
QmSoLV4Bbm51jM9C4gDYZQ9Cy3U6aXMJDAbzgu2fzaDs64
$ ipfs block stat QmSoLV4Bbm51jM9C4gDYZQ9Cy3U6aXMJDAbzgu2fzaDs64
Key: QmSoLV4Bbm51jM9C4gDYZQ9Cy3U6aXMJDAbzgu2fzaDs64
Size: 19
$ ipfs block get QmSoLV4Bbm51jM9C4gDYZQ9Cy3U6aXMJDAbzgu2fzaDs64
"hi, every"
$ ipfs block rm QmSoLV4Bbm51jM9C4gDYZQ9Cy3U6aXMJDAbzgu2fzaDs64
removed QmSoLV4Bbm51jM9C4gDYZQ9Cy3U6aXMJDAbzgu2fzaDs64
IPFS - add
IPFS add
add 명령은 ipfs에 파일이나 폴더를 추가하는 데 사용됩니다. 기본 사용법 :
ipfs add [options] 경로
주요 옵션은 다음과 같습니다:
- r: 가져오기 옵션, 폴더 추가에 사용
- q: 추가 후 출력 간소화
- w: 파일 또는 폴더를 한 폴더로 패키징
- H: 숨겨진 파일을 추가 (-r 과 함께 사용)
- s: 추가 할 파일 자르기 방법 지정
- t: trickle-dag 형식으로 dag 생성
- pin: 업로드 된 파일을 로컬에 보관하지 않으려면 -pin = false 사용
다음 예제에서 -q, -s 및 -w 를 보여줍니다.
- -q 옵션을 추가하면 파일의 해시 값만 출력
$ ipfs add wechat.jpg
added QmX76kWggpFKnzgP9i3wdpHcoC7Go8GLZ3Uhpjao9LaHkc wechat.jpg
$ ipfs add -q wechat.jpg
QmX76kWggpFKnzgP9i3wdpHcoC7Go8GLZ3Uhpjao9LaHkc
- -s 옵션을 추가하면 각 슬라이스의 최대 크기를 바이트 단위로 지정할 수 있으며 각 블록의 기본값은 256K
object links명령을 사용하여 나뉜 파일의 개별 블록 확인
$ ipfs add -s size-10240 wechat.jpg
added QmaWLzjB6Y5RdkThm6TCxoK5ZnFRypxTNdK52QLGdoTvAs wechat.jpg
$ ipfs add wechat.jpg
added QmX76kWggpFKnzgP9i3wdpHcoC7Go8GLZ3Uhpjao9LaHkc wechat.jpg
$ ipfs object links QmaWLzjB6Y5RdkThm6TCxoK5ZnFRypxTNdK52QLGdoTvAs
QmY6AWeX52Pemc54pv6jFUvwaA1VBH7yFqLZv6A64MSEWg 10251
QmSCKPtkEpffpKUasSxMqicDN7vbSxhw8k7BwGBFbjSDai 10251
QmQ2DZqTnHF3F9mqtSD66jvKDGUanBgEfUxRDTtMQJuQZp 10251
QmdejejQH5wP6fKrmkBHRqtevFvUrTeAEHpMcnEAGTmkDY 10251
QmWimAR2tjeJBcsBtJPkU3VxQRdieHcYyaK5fnAJCd4Byj 10251
QmUXSHDHLyz3kxsFGdEc29JjLoJoeGamTKvbu84FfZ2VXv 4534
- -w 옵션을 추가하면 폴더가 하나 더 추가되고 원래 jpg 파일이 새로 생성된 폴더 안에 위치
$ ipfs add -w wechat.jpg
added QmX76kWggpFKnzgP9i3wdpHcoC7Go8GLZ3Uhpjao9LaHkc wechat.jpg
added QmbuocMnx9ArAejokbRoJqfsJgffU879Fz1Pb6jnmbbVU7
IPFS 프로토콜 IPNS 계층 분석 - 인터페이스
IPFS Name Service-Interface
IPFS Naming 계층의 구체적인 구현에 대하여 설명하고자 합니다. 먼저 이 계층의 인터페이스를 보면 아래와 같습니다.
...
type NameSystem interface {
Resolver
Publisher
}
// Result is the return type for Resolver.ResolveAsync.
type Result struct {
Path path.Path
Err error
}
// Resolver is an object capable of resolving names.
type Resolver interface {
// Resolve performs a recursive lookup, returning the dereferenced
// path. For example, if ipfs.io has a DNS TXT record pointing to
// /ipns/QmatmE9msSfkKxoffpHwNLNKgwZG8eT9Bud6YoPab52vpy
// and there is a DHT IPNS entry for
// QmatmE9msSfkKxoffpHwNLNKgwZG8eT9Bud6YoPab52vpy
// -> /ipfs/Qmcqtw8FfrVSBaRmbWwHxt3AuySBhJLcvmFYi3Lbc4xnwj
// then
// Resolve(ctx, "/ipns/ipfs.io")
// will resolve both names, returning
// /ipfs/Qmcqtw8FfrVSBaRmbWwHxt3AuySBhJLcvmFYi3Lbc4xnwj
//
// There is a default depth-limit to avoid infinite recursion. Most
// users will be fine with this default limit, but if you need to
// adjust the limit you can specify it as an option.
Resolve(ctx context.Context, name string, options ...opts.ResolveOpt) (value path.Path, err error)
// ResolveAsync performs recursive name lookup, like Resolve, but it returns
// entries as they are discovered in the DHT. Each returned result is guaranteed
// to be "better" (which usually means newer) than the previous one.
ResolveAsync(ctx context.Context, name string, options ...opts.ResolveOpt) <-chan Result
}
// Publisher is an object capable of publishing particular names.
type Publisher interface {
// Publish establishes a name-value mapping.
// TODO make this not PrivKey specific.
Publish(ctx context.Context, name ci.PrivKey, value path.Path) error
// TODO: to be replaced by a more generic 'PublishWithValidity' type
// call once the records spec is implemented
PublishWithEOL(ctx context.Context, name ci.PrivKey, value path.Path, eol time.Time) error
}
인터페이스 정의는 비교적 간단하게 구성되어 있습니다. 하나의 구조 인터페이스와 2개의 배포 인터페이스 (Resolve, Publish) 가 있습니다. 해당 로직의 모습은 다음과 같습니다.
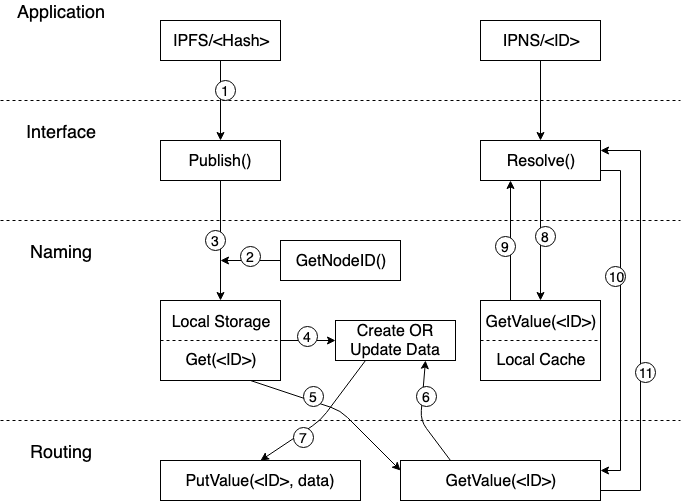
응용 계층에서 IPFS 프로토콜에 의한 Hash 값을 네트워크에 Publish 하면 IPFS 노드는 먼저 자신의 ID 를 읽고 ID 에 대한 IPNS 의 매핑 데이터를 Local Storage 에서 검색하고 검색에 성공하면 데이터가 업데이트 됩니다. 그런 다음 Routing 계층의 PutValue 인터페이스를 호출하여 ID 및 최신 IPNS 매핑 데이터를 전체 네트워크에 Publish 합니다. Local Storage 에서 검색하지 못하면 Routing 계층의 GetValue 가 호출되어 전체 네트워크에서 해당 ID에 대한 IPNS 매핑 데이터를 검색하고 검색에 성공하면 데이터의 번호가 업데이트 되어 전체 네트워크에 다시 Publish 합니다. 매핑 데이터를 찾지 못하면 ID와 IPNS 에 대한 새로운 매핑 데이터가 생성되어 전체 네트워크에 Publilsh 됩니다.
응용 계층이 IPNS 에서 ID 에 해당하는 IPFS Hash 데이터를 구문 분석할 때 Naming 계층은 먼저 로컬 Cache 에서 해당 매핑 데이터를 검색합니다. 상단의 Publish 링크에서 Routing 계층의 PutValue 가 성공하면 Naming 계층은 매핑된 데이터를 로컬 Cache 에 ‘Cache’ 하는 것으로 resolve 를 로컬에서 읽을 때 마다 네트워크 액세스 비용을 줄일 수 있습니다. 로컬 Cache 에서 검색에 실패하면 Naming 계층은 Routing 계층에 대한 GetValue 액세스 요청을 시작하고 액세스가 성공하면 응용 계층은 ID 에 대한 Hash 값을 받고 Hash 값을 통해 특정 데이터에 액세스할 수 있습니다.
MerkleDAG 및 Routing 계층을 기반으로 데이터 교환 계층의 API 인터페이스는 고정된 Name 과 가변 데이터 Hash 값 및 매핑 데이터 검색 간의 매핑을 할 수 있기 때문에 Naming 계층의 특정 구현은 비교적 간단합니다. 하지만 적용 시나리오는 부족합니다. 아래는 무선 확장 스토리지 마운트를 예로들어 사용 방법을 설명합니다. 분산화된 무한 네트워크 확장은 매우 흥미로울 것 입니다.
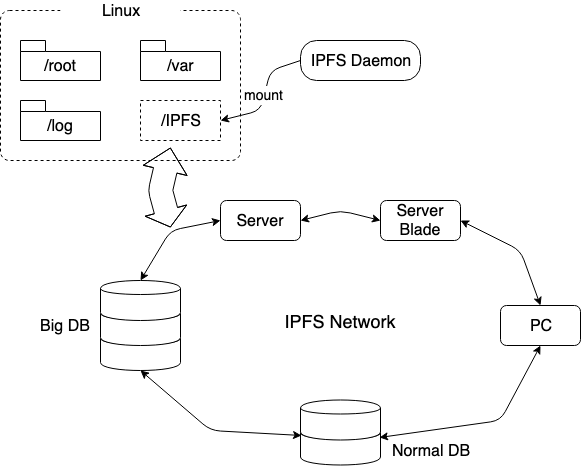
위 그림과 같이 Linux 디렉토리 구조를 예를들면 먼저 ‘IPFS Daemon’ 을 시작하고 ipfs mount 명령을 호출하여 전체 IPFS 네트워크를 “/” 디렉토리에 마운트 합니다 (해당 디렉토리에 마운트). “IPFS” 디렉토리가 나타나고 전체 IPFS 네트워크가 스토리지 서비스를 제공합니다. Naming 을 통해 이 디렉토리에 추가된 모든 파일과 디렉토리는 IPFS 에서 인식이 가능한 Hash 값으로 매핑됩니다. 이러한 방식으로 IPFS 네트워크에 추가되는 모든 종류의 저장 장치가 무제한 데이터 저장 서비스를 제공하게 됩니다.
블록체인 프로젝트의 경우 이 네트워크를 기반으로 인센티브 메커니즘을 높일 수 있다면 유휴 저장 리소스를 사용하여 토큰을 통한 거래가 가능할 수 있습니다. 데이터 저장 및 읽기 서비스를 사용할 수 있는 유연한 방법으로 활용될 수 있습니다. 즉, 중복 저장 공간을 구입할 필요가 없으며 지불 금액을 결정할 수 있습니다.
기업에서 사용하는 경우 이러한 스토리지 인트라넷을 구축하면 회사의 유휴 IT 장비의 리소스를 최대한 활용할 수 있습니다.
모든 데이터는 모든 노드에 배포되고 암호화되어 저장되기 때문에 데이터 보안을 충족할 수 있으므로 데이터 유출에 대한 걱정이 줄어들 것 입니다.
데이터 전송 프로세스에서 패킷 캡처 소프트웨어가 데이터를 캡처하지 못하도록 아래와 같이 데이터 재전송 프로세스를 활용하여 보안 문제를 해결할 수 있습니다.
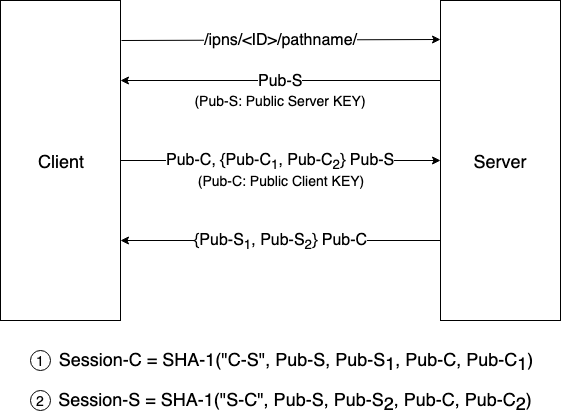
- 클라이언트인 IPFS 노드는 콘텐츠 액세스 요청을 시작
- 서버는 자신의 공개 키를 제공
- 공개 키를 수신한 클라이언트는 서버에 자신의 공개 키를 보내기 위해 두개의 공개 키 C1 과 C2 를 무작위로 생성하고 생성된 두개의 공개 키가 암호화되어 서버로 전송
- 서버는 데이터를 수신한 후 공개 키 C1 및 C2 를 자신의 개인 키로 해독하고 랜덤으로 두개의 공개 키 S1 및 S2 를 생성한 후 클라이언트 공개 키로 암호화하여 이를 클라이언트로 전송
- 암호화된 데이터를 수신한 클라이언트는 자체 개인 키로 해독
이후 데이터 전송은 다음과 같이 서명됩니다.
- 클라이언트-서버 데이터: 수식 1에서 사용된 데이터를 활용하여 서명
- 서버-클라이언트 데이터: 수식 2에서 사용된 데이터를 활용하여 서명 (위험 노드에 의한 데이터 수정 및 제거가 필요하지 않음)
IPFS 프로토콜 IPNS 계층 분석 - Overview
IPFS Name Service
IPFS에서 MerkleDAG 계층은 콘텐츠의 해시 값을 기반으로 데이터 및 콘텐츠를 정확하게 찾을 수 있으며 중복 데이터를 효과적으로 제거 할 수 있습니다. 각 블록의 링크는 다음 콘텐츠의 해시 값을 유지하기 때문에 콘텐츠가 수정되지 않는 한 링크가 유효하며 데이터 유효성을 확인할 필요가 없습니다. 그러나 아래의 그림과 같이 디렉토리 아래의 파일이 수정되면 전체 경로의 해시 값이 수정되어 트리의 루트가 변경됩니다.
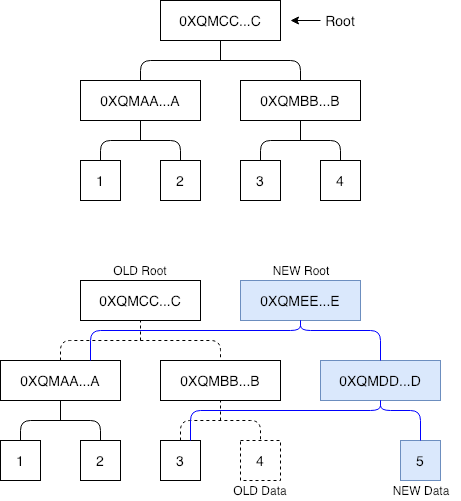
그림에서 데이터 블록 4를 데이터 블록 5로 수정했습니다. 즉, 오른쪽의 해시 트리가 수정이 로컬에서 발생하며 전체 네트워크에 동기화하는 비용은 매우 높기 때문에 변경을 할 때마다 해시 정보를 동기화해야 합니다. 따라서 IPFS의 Naming 계층에서 파일 시스템 자체 확인 (Self-verifying File System) 개념이 도입되고 로컬 NodeID가 특정 콘텐츠 해시 값에 바인딩되며 네트워크의 다른 사용자가 NodeId에 액세스하여 바인딩 된 콘텐츠에 액세스 할 수 있습니다. 이를 통해 중앙 집중화 된 웹 사이트가 가능합니다.
아래에서는 특정 시나리오에서 이 계층 프로토콜의 적용을 설명하기 위해 분산 된 웹 사이트의 구성을 예로 들어 설명합니다. 분산 된 웹 사이트를 만들고 우리 웹 사이트의 각 콘텐츠 수정이 IPFS 네트워크의 다른 노드에 투명하다는 가정하에 사용자는 콘텐츠 해시 값을 업데이트하지 않고 최신 콘텐츠에 액세스 할 수 있습니다.
위의 그림에서 우리는 먼저 html 파일과 그림으로 구성된 웹 사이트를 만듭니다.
위의 첫 번째 단계에서는 전체 웹 사이트 디렉토리를 IPFS 네트워크에 업로드합니다. 두 번째 단계에서는 루트 디렉토리의 해시 값이 Naming 프로토콜을 통해 NodeId에 매핑합니다. IPFS 노드의 NodeId는 상대적으로 고정되어 있으며 이는 로컬에서 실행중인 IPFS 노드를 나타냅니다. 세 번째 단계는 업로드가 성공한 후 명령을 구문 분석하여 노드를 특정 내용에 매핑 할 수 있습니다. 그림 4에 주목해야 할 필요가 있는데, 이것은 NodeId의 해시 값입니다.
위의 그림에서 두 가지 프로토콜을 통해 웹 사이트에 액세스합니다. 왼쪽은 ipfs/xxxx입니다. Merkle DAG 프로토콜에 따르면 웹 사이트 루트 디렉토리의 해시 값은 전체 네트워크에서 발견됩니다. 오른쪽에는 Naming 프로토콜을 통해 웹 사이트의 콘텐츠를 찾는 ipns/ 방법이 있습니다. 그림에서 볼 수 있듯이 두 가지 액세스 방법으로 얻은 결과는 완전히 일치합니다.
웹 사이트의 내용과 구조를 다음과 같이 수정하려고 합니다. cat.jpg를 NBS (Next Blockchain System) 로고로 교체했습니다.
웹 사이트의 내용은 IPFS 네트워크에 다시 게시됩니다. 그림에서 4는 NodeId 매핑을 구문 분석 할 때 얻은 최신 웹 사이트 루트 디렉토리의 해시 값이며 NodeId가 변경되지 않은 경우 최신 내용의 콘텐츠의 루트 디렉토리의 hash 값을 얻습니다.
최신 웹 콘텐츠에 액세스 할 수 있는 브라우저를 통해 왼쪽과 같이 MerkleDAG 프로토콜을 통해 최신 콘텐츠의 해시 값에 액세스하고 최신 콘텐츠를 얻을 수 있으며, 오른쪽과 같이 Naming 프로토콜을 통해 NodeId를 사용하여 액세스하고, 최신 웹 사이트 콘텐츠를 동일하게 얻을 수 있습니다. (고양이 그림을 얻은 웹페이지의 주소와 비교하면 IPNS의 경우 동일 주소를 사용함을 알 수 있음)
위의 예제를 통해 Naming 프로토콜을 통해 웹 사이트 콘텐츠를 유연하게 수정하고 최신 콘텐츠 해시를 브로드 캐스트하지 않고 분산 된 웹 사이트를 실현할 수 있음을 분명히 알 수 있습니다.
IPFS 프로토콜 교환 계층 분석 - Receive Blocks
IPFS 데이터 교환 계층-Receive Blocks
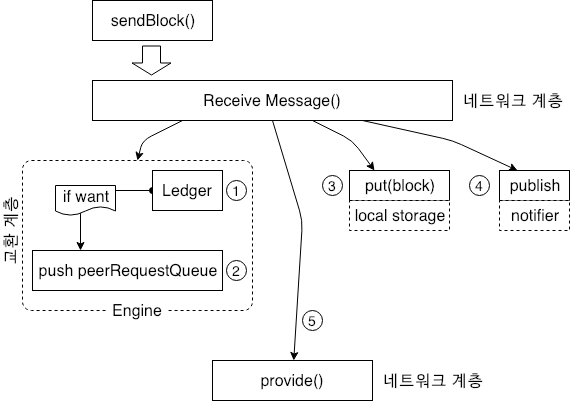
컨텐츠 공급자는 자체적으로 저장된 컨텐츠를 네트워크 계층으로 보냅니다. 데이터 수신 후 컨텐츠 수신단은 Engine 의 청구 시스템을 통해 노드와 송신 데이터 노드간의 데이터 상호 작용을 계산합니다. Statistics (통계) 를 검색한 다음 Engine 에 캐시된 WantList 정보를 조회합니다. 노드가 방금 수신한 데이터를 요청하는 다른 노드가 있는 경우 데이터를 peerRequestQueue 에 넣는 즉시 컨텐츠 공급자가 됩니다.
이후 노드는 방문자에 대한 데이터 캐시를 제공하고 데이터에 다시 액세스하며 다른 노드의 데이터 방문자에 대한 스토리지 서비스가 될 수 있는 로컬 스토리지 공간에 데이터를 저장합니다.
데이터 교환 계층의 첫번째 포스팅에서 데이터에 액세스하는 노드가 key 를 subscribe 한다고 하였는데 이러한 key 는 검색할 데이터에 해당하는 인덱스이기 때문에 데이터를 수신할 때 수신된 데이터를 최신 구독자에게 브로드캐스트 하여야 합니다. 위 그림의 4는 이와 같은 메시지를 publish 하는 것을 나타냅니다.
위 작업들이 완료되면 노드는 Want Manager 대기열의 데이터를 확인하고 수신된 데이터가 다른 노드에 의해 액세스되는 경우 데이터는 5와 같은 형식으로 프로세스의 다른 노드에 제공됩니다. 데이터를 수신한 후 Want Manager 의 Want List 에 있는 노드에 대한 요청을 Want List 에서 삭제하여야 합니다. 노드가 원본 데이터 요청 개시자인 경우 반복적으로 여러 노드가 동일한 데이터를 보내지 않도록 하여야 합니다. 즉 다른 노드에 해당 데이터에 대한 전체 네트워크 조회를 수행하지 않도록 알리기 위하여 cancel 명령을 사용합니다. cancel 은 GetBlock 과 유사하게 동작합니다.
아래의 코드를 활용하면 이에대한 메커니즘을 구현할 수 있습니다.
IPFS exchange interface (bitswap.go)
검색 로직외에 데이터 교환 레이어의 Engine 은 노드와 다른 노드간 얼마나 많은 데이터가 교환되는지에 따라 인접 노드에 서비스를 계속 제공할지 여부를 결정하는 기능을 사용할 수 있습니다. 노드가 많은 양의 데이터를 수신하면 데이터는 드물게 악의적인 노드로 간주될 가능성이 있기 때문에 Frozon 계정에 추가됩니다. 이는 이전 포스팅의 peerRequestQueue 에 대한 Map 구조에 대한 내용을 생각하면 되겠습니다. 데이터 선발의 논리적인 공식은 다음 수식에서 확인할 수 있습니다.
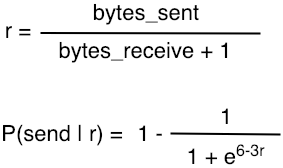
첫번째 수식에서 r 은 전송된 데이터와 수신된 데이터 간의 비례 관계를 나타냅니다.
두번째 수식에서 P 는 다른 노드로 데이터를 계속 보낼 확률을 나타냅니다.
다른 노드가 많은 양의 데이터를 보내지만 상대방으로 부터 받은 데이터가 매우 작으면 r 값이 매우 커지고 확률 P 는 작아집니다. 즉, 상대방에게 더 많은 데이터를 제공하고 데이터를 작게 받는다면 상대방이 공격 노드(악의적 노드) 일 수 있다고 생각할 수 있습니다. 반대로 더 높은 확률로 더 많은 서비스를 제공하는 노드에게는 그만큼의 서비스를 상대방에게 제공하여야 합니다. 이러한 내용은 ‘Filecoin’ 에 잘 설명이 되어 있습니다.
지금까지 데이터 교환 계층에 대하여 GetBlocks 라고 하는 대표 인터페이스에 대한 전체 데이터 동작에 대하여 알아보았습니다. 데이터 교환 계층은 현재에도 매우 많은 문제를 해결하기 위한 시도가 진행되고 있으며 매우 어려운 부분입니다. 분산 스토리지 시스템에서 데이터가 유효한지, 스토리지 장치의 위치가 변경되었는지 같은 내용을 다른 노드에 효과적으로 알리기 위한 IPFS의 주요 과제도 산적해 있습니다.
