IPFS 프로토콜 IPNS 계층 분석 - 인터페이스
IPFS Name Service-Interface
IPFS Naming 계층의 구체적인 구현에 대하여 설명하고자 합니다. 먼저 이 계층의 인터페이스를 보면 아래와 같습니다.
...
type NameSystem interface {
Resolver
Publisher
}
// Result is the return type for Resolver.ResolveAsync.
type Result struct {
Path path.Path
Err error
}
// Resolver is an object capable of resolving names.
type Resolver interface {
// Resolve performs a recursive lookup, returning the dereferenced
// path. For example, if ipfs.io has a DNS TXT record pointing to
// /ipns/QmatmE9msSfkKxoffpHwNLNKgwZG8eT9Bud6YoPab52vpy
// and there is a DHT IPNS entry for
// QmatmE9msSfkKxoffpHwNLNKgwZG8eT9Bud6YoPab52vpy
// -> /ipfs/Qmcqtw8FfrVSBaRmbWwHxt3AuySBhJLcvmFYi3Lbc4xnwj
// then
// Resolve(ctx, "/ipns/ipfs.io")
// will resolve both names, returning
// /ipfs/Qmcqtw8FfrVSBaRmbWwHxt3AuySBhJLcvmFYi3Lbc4xnwj
//
// There is a default depth-limit to avoid infinite recursion. Most
// users will be fine with this default limit, but if you need to
// adjust the limit you can specify it as an option.
Resolve(ctx context.Context, name string, options ...opts.ResolveOpt) (value path.Path, err error)
// ResolveAsync performs recursive name lookup, like Resolve, but it returns
// entries as they are discovered in the DHT. Each returned result is guaranteed
// to be "better" (which usually means newer) than the previous one.
ResolveAsync(ctx context.Context, name string, options ...opts.ResolveOpt) <-chan Result
}
// Publisher is an object capable of publishing particular names.
type Publisher interface {
// Publish establishes a name-value mapping.
// TODO make this not PrivKey specific.
Publish(ctx context.Context, name ci.PrivKey, value path.Path) error
// TODO: to be replaced by a more generic 'PublishWithValidity' type
// call once the records spec is implemented
PublishWithEOL(ctx context.Context, name ci.PrivKey, value path.Path, eol time.Time) error
}
인터페이스 정의는 비교적 간단하게 구성되어 있습니다. 하나의 구조 인터페이스와 2개의 배포 인터페이스 (Resolve, Publish) 가 있습니다. 해당 로직의 모습은 다음과 같습니다.
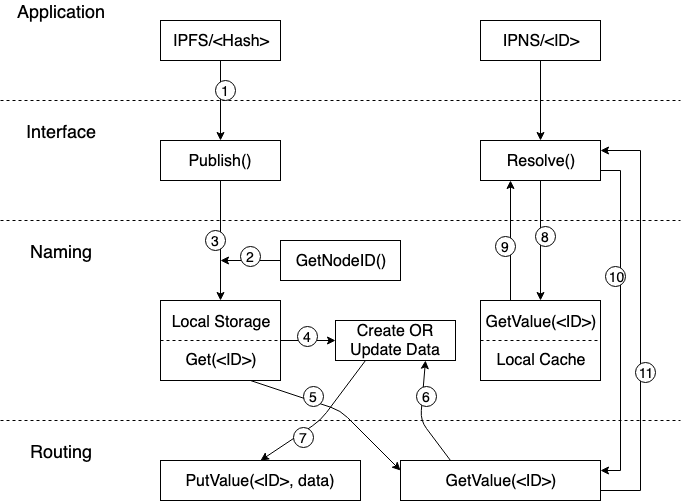
응용 계층에서 IPFS 프로토콜에 의한 Hash 값을 네트워크에 Publish 하면 IPFS 노드는 먼저 자신의 ID 를 읽고 ID 에 대한 IPNS 의 매핑 데이터를 Local Storage 에서 검색하고 검색에 성공하면 데이터가 업데이트 됩니다. 그런 다음 Routing 계층의 PutValue 인터페이스를 호출하여 ID 및 최신 IPNS 매핑 데이터를 전체 네트워크에 Publish 합니다. Local Storage 에서 검색하지 못하면 Routing 계층의 GetValue 가 호출되어 전체 네트워크에서 해당 ID에 대한 IPNS 매핑 데이터를 검색하고 검색에 성공하면 데이터의 번호가 업데이트 되어 전체 네트워크에 다시 Publish 합니다. 매핑 데이터를 찾지 못하면 ID와 IPNS 에 대한 새로운 매핑 데이터가 생성되어 전체 네트워크에 Publilsh 됩니다.
응용 계층이 IPNS 에서 ID 에 해당하는 IPFS Hash 데이터를 구문 분석할 때 Naming 계층은 먼저 로컬 Cache 에서 해당 매핑 데이터를 검색합니다. 상단의 Publish 링크에서 Routing 계층의 PutValue 가 성공하면 Naming 계층은 매핑된 데이터를 로컬 Cache 에 ‘Cache’ 하는 것으로 resolve 를 로컬에서 읽을 때 마다 네트워크 액세스 비용을 줄일 수 있습니다. 로컬 Cache 에서 검색에 실패하면 Naming 계층은 Routing 계층에 대한 GetValue 액세스 요청을 시작하고 액세스가 성공하면 응용 계층은 ID 에 대한 Hash 값을 받고 Hash 값을 통해 특정 데이터에 액세스할 수 있습니다.
MerkleDAG 및 Routing 계층을 기반으로 데이터 교환 계층의 API 인터페이스는 고정된 Name 과 가변 데이터 Hash 값 및 매핑 데이터 검색 간의 매핑을 할 수 있기 때문에 Naming 계층의 특정 구현은 비교적 간단합니다. 하지만 적용 시나리오는 부족합니다. 아래는 무선 확장 스토리지 마운트를 예로들어 사용 방법을 설명합니다. 분산화된 무한 네트워크 확장은 매우 흥미로울 것 입니다.
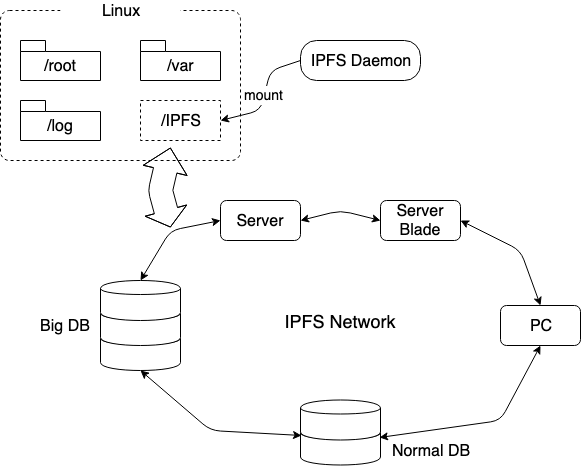
위 그림과 같이 Linux 디렉토리 구조를 예를들면 먼저 ‘IPFS Daemon’ 을 시작하고 ipfs mount 명령을 호출하여 전체 IPFS 네트워크를 “/” 디렉토리에 마운트 합니다 (해당 디렉토리에 마운트). “IPFS” 디렉토리가 나타나고 전체 IPFS 네트워크가 스토리지 서비스를 제공합니다. Naming 을 통해 이 디렉토리에 추가된 모든 파일과 디렉토리는 IPFS 에서 인식이 가능한 Hash 값으로 매핑됩니다. 이러한 방식으로 IPFS 네트워크에 추가되는 모든 종류의 저장 장치가 무제한 데이터 저장 서비스를 제공하게 됩니다.
블록체인 프로젝트의 경우 이 네트워크를 기반으로 인센티브 메커니즘을 높일 수 있다면 유휴 저장 리소스를 사용하여 토큰을 통한 거래가 가능할 수 있습니다. 데이터 저장 및 읽기 서비스를 사용할 수 있는 유연한 방법으로 활용될 수 있습니다. 즉, 중복 저장 공간을 구입할 필요가 없으며 지불 금액을 결정할 수 있습니다.
기업에서 사용하는 경우 이러한 스토리지 인트라넷을 구축하면 회사의 유휴 IT 장비의 리소스를 최대한 활용할 수 있습니다.
모든 데이터는 모든 노드에 배포되고 암호화되어 저장되기 때문에 데이터 보안을 충족할 수 있으므로 데이터 유출에 대한 걱정이 줄어들 것 입니다.
데이터 전송 프로세스에서 패킷 캡처 소프트웨어가 데이터를 캡처하지 못하도록 아래와 같이 데이터 재전송 프로세스를 활용하여 보안 문제를 해결할 수 있습니다.
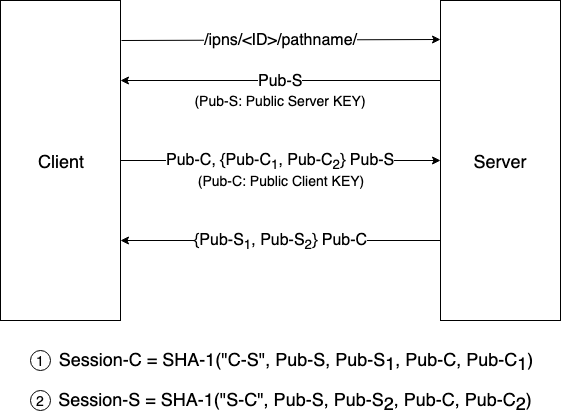
- 클라이언트인 IPFS 노드는 콘텐츠 액세스 요청을 시작
- 서버는 자신의 공개 키를 제공
- 공개 키를 수신한 클라이언트는 서버에 자신의 공개 키를 보내기 위해 두개의 공개 키 C1 과 C2 를 무작위로 생성하고 생성된 두개의 공개 키가 암호화되어 서버로 전송
- 서버는 데이터를 수신한 후 공개 키 C1 및 C2 를 자신의 개인 키로 해독하고 랜덤으로 두개의 공개 키 S1 및 S2 를 생성한 후 클라이언트 공개 키로 암호화하여 이를 클라이언트로 전송
- 암호화된 데이터를 수신한 클라이언트는 자체 개인 키로 해독
이후 데이터 전송은 다음과 같이 서명됩니다.
- 클라이언트-서버 데이터: 수식 1에서 사용된 데이터를 활용하여 서명
- 서버-클라이언트 데이터: 수식 2에서 사용된 데이터를 활용하여 서명 (위험 노드에 의한 데이터 수정 및 제거가 필요하지 않음)
