IPFS 프로토콜 IPNS 계층 분석 - Overview
IPFS Name Service
IPFS에서 MerkleDAG 계층은 콘텐츠의 해시 값을 기반으로 데이터 및 콘텐츠를 정확하게 찾을 수 있으며 중복 데이터를 효과적으로 제거 할 수 있습니다. 각 블록의 링크는 다음 콘텐츠의 해시 값을 유지하기 때문에 콘텐츠가 수정되지 않는 한 링크가 유효하며 데이터 유효성을 확인할 필요가 없습니다. 그러나 아래의 그림과 같이 디렉토리 아래의 파일이 수정되면 전체 경로의 해시 값이 수정되어 트리의 루트가 변경됩니다.
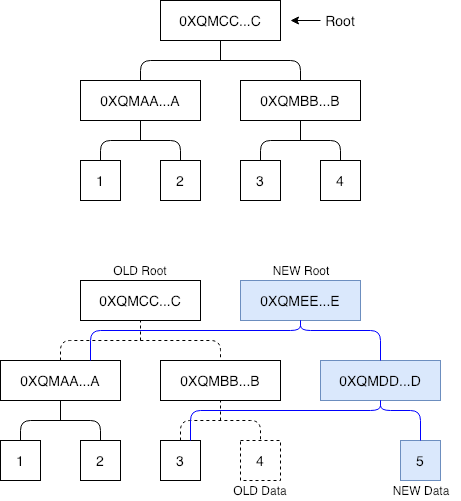
그림에서 데이터 블록 4를 데이터 블록 5로 수정했습니다. 즉, 오른쪽의 해시 트리가 수정이 로컬에서 발생하며 전체 네트워크에 동기화하는 비용은 매우 높기 때문에 변경을 할 때마다 해시 정보를 동기화해야 합니다. 따라서 IPFS의 Naming 계층에서 파일 시스템 자체 확인 (Self-verifying File System) 개념이 도입되고 로컬 NodeID가 특정 콘텐츠 해시 값에 바인딩되며 네트워크의 다른 사용자가 NodeId에 액세스하여 바인딩 된 콘텐츠에 액세스 할 수 있습니다. 이를 통해 중앙 집중화 된 웹 사이트가 가능합니다.
아래에서는 특정 시나리오에서 이 계층 프로토콜의 적용을 설명하기 위해 분산 된 웹 사이트의 구성을 예로 들어 설명합니다. 분산 된 웹 사이트를 만들고 우리 웹 사이트의 각 콘텐츠 수정이 IPFS 네트워크의 다른 노드에 투명하다는 가정하에 사용자는 콘텐츠 해시 값을 업데이트하지 않고 최신 콘텐츠에 액세스 할 수 있습니다.
위의 그림에서 우리는 먼저 html 파일과 그림으로 구성된 웹 사이트를 만듭니다.
위의 첫 번째 단계에서는 전체 웹 사이트 디렉토리를 IPFS 네트워크에 업로드합니다. 두 번째 단계에서는 루트 디렉토리의 해시 값이 Naming 프로토콜을 통해 NodeId에 매핑합니다. IPFS 노드의 NodeId는 상대적으로 고정되어 있으며 이는 로컬에서 실행중인 IPFS 노드를 나타냅니다. 세 번째 단계는 업로드가 성공한 후 명령을 구문 분석하여 노드를 특정 내용에 매핑 할 수 있습니다. 그림 4에 주목해야 할 필요가 있는데, 이것은 NodeId의 해시 값입니다.
위의 그림에서 두 가지 프로토콜을 통해 웹 사이트에 액세스합니다. 왼쪽은 ipfs/xxxx입니다. Merkle DAG 프로토콜에 따르면 웹 사이트 루트 디렉토리의 해시 값은 전체 네트워크에서 발견됩니다. 오른쪽에는 Naming 프로토콜을 통해 웹 사이트의 콘텐츠를 찾는 ipns/ 방법이 있습니다. 그림에서 볼 수 있듯이 두 가지 액세스 방법으로 얻은 결과는 완전히 일치합니다.
웹 사이트의 내용과 구조를 다음과 같이 수정하려고 합니다. cat.jpg를 NBS (Next Blockchain System) 로고로 교체했습니다.
웹 사이트의 내용은 IPFS 네트워크에 다시 게시됩니다. 그림에서 4는 NodeId 매핑을 구문 분석 할 때 얻은 최신 웹 사이트 루트 디렉토리의 해시 값이며 NodeId가 변경되지 않은 경우 최신 내용의 콘텐츠의 루트 디렉토리의 hash 값을 얻습니다.
최신 웹 콘텐츠에 액세스 할 수 있는 브라우저를 통해 왼쪽과 같이 MerkleDAG 프로토콜을 통해 최신 콘텐츠의 해시 값에 액세스하고 최신 콘텐츠를 얻을 수 있으며, 오른쪽과 같이 Naming 프로토콜을 통해 NodeId를 사용하여 액세스하고, 최신 웹 사이트 콘텐츠를 동일하게 얻을 수 있습니다. (고양이 그림을 얻은 웹페이지의 주소와 비교하면 IPNS의 경우 동일 주소를 사용함을 알 수 있음)
위의 예제를 통해 Naming 프로토콜을 통해 웹 사이트 콘텐츠를 유연하게 수정하고 최신 콘텐츠 해시를 브로드 캐스트하지 않고 분산 된 웹 사이트를 실현할 수 있음을 분명히 알 수 있습니다.
