IPFS 프로토콜 교환 계층 분석 - Receive Blocks
IPFS 데이터 교환 계층-Receive Blocks
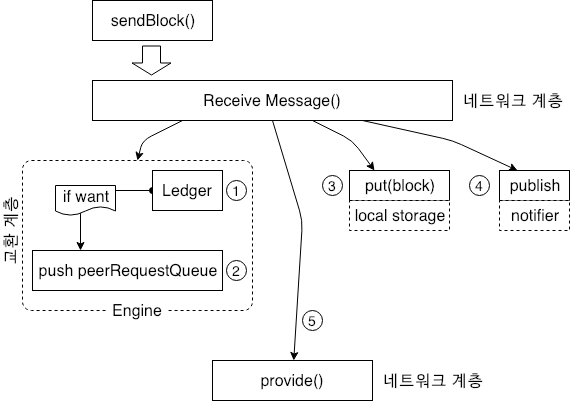
컨텐츠 공급자는 자체적으로 저장된 컨텐츠를 네트워크 계층으로 보냅니다. 데이터 수신 후 컨텐츠 수신단은 Engine 의 청구 시스템을 통해 노드와 송신 데이터 노드간의 데이터 상호 작용을 계산합니다. Statistics (통계) 를 검색한 다음 Engine 에 캐시된 WantList 정보를 조회합니다. 노드가 방금 수신한 데이터를 요청하는 다른 노드가 있는 경우 데이터를 peerRequestQueue 에 넣는 즉시 컨텐츠 공급자가 됩니다.
이후 노드는 방문자에 대한 데이터 캐시를 제공하고 데이터에 다시 액세스하며 다른 노드의 데이터 방문자에 대한 스토리지 서비스가 될 수 있는 로컬 스토리지 공간에 데이터를 저장합니다.
데이터 교환 계층의 첫번째 포스팅에서 데이터에 액세스하는 노드가 key 를 subscribe 한다고 하였는데 이러한 key 는 검색할 데이터에 해당하는 인덱스이기 때문에 데이터를 수신할 때 수신된 데이터를 최신 구독자에게 브로드캐스트 하여야 합니다. 위 그림의 4는 이와 같은 메시지를 publish 하는 것을 나타냅니다.
위 작업들이 완료되면 노드는 Want Manager 대기열의 데이터를 확인하고 수신된 데이터가 다른 노드에 의해 액세스되는 경우 데이터는 5와 같은 형식으로 프로세스의 다른 노드에 제공됩니다. 데이터를 수신한 후 Want Manager 의 Want List 에 있는 노드에 대한 요청을 Want List 에서 삭제하여야 합니다. 노드가 원본 데이터 요청 개시자인 경우 반복적으로 여러 노드가 동일한 데이터를 보내지 않도록 하여야 합니다. 즉 다른 노드에 해당 데이터에 대한 전체 네트워크 조회를 수행하지 않도록 알리기 위하여 cancel 명령을 사용합니다. cancel 은 GetBlock 과 유사하게 동작합니다.
아래의 코드를 활용하면 이에대한 메커니즘을 구현할 수 있습니다.
IPFS exchange interface (bitswap.go)
검색 로직외에 데이터 교환 레이어의 Engine 은 노드와 다른 노드간 얼마나 많은 데이터가 교환되는지에 따라 인접 노드에 서비스를 계속 제공할지 여부를 결정하는 기능을 사용할 수 있습니다. 노드가 많은 양의 데이터를 수신하면 데이터는 드물게 악의적인 노드로 간주될 가능성이 있기 때문에 Frozon 계정에 추가됩니다. 이는 이전 포스팅의 peerRequestQueue 에 대한 Map 구조에 대한 내용을 생각하면 되겠습니다. 데이터 선발의 논리적인 공식은 다음 수식에서 확인할 수 있습니다.
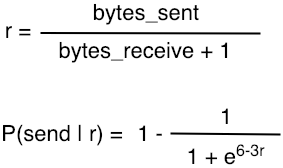
첫번째 수식에서 r 은 전송된 데이터와 수신된 데이터 간의 비례 관계를 나타냅니다.
두번째 수식에서 P 는 다른 노드로 데이터를 계속 보낼 확률을 나타냅니다.
다른 노드가 많은 양의 데이터를 보내지만 상대방으로 부터 받은 데이터가 매우 작으면 r 값이 매우 커지고 확률 P 는 작아집니다. 즉, 상대방에게 더 많은 데이터를 제공하고 데이터를 작게 받는다면 상대방이 공격 노드(악의적 노드) 일 수 있다고 생각할 수 있습니다. 반대로 더 높은 확률로 더 많은 서비스를 제공하는 노드에게는 그만큼의 서비스를 상대방에게 제공하여야 합니다. 이러한 내용은 ‘Filecoin’ 에 잘 설명이 되어 있습니다.
지금까지 데이터 교환 계층에 대하여 GetBlocks 라고 하는 대표 인터페이스에 대한 전체 데이터 동작에 대하여 알아보았습니다. 데이터 교환 계층은 현재에도 매우 많은 문제를 해결하기 위한 시도가 진행되고 있으며 매우 어려운 부분입니다. 분산 스토리지 시스템에서 데이터가 유효한지, 스토리지 장치의 위치가 변경되었는지 같은 내용을 다른 노드에 효과적으로 알리기 위한 IPFS의 주요 과제도 산적해 있습니다.
