Version Control Systems in IPFS
Merkle DAG
가장자리가 merkle-link 인 방향성 비순환 그래프입니다. 즉, 객체에 대한 링크는 객체 자체를 인증 할 수 있으며 모든 객체에는 해당 객체의 보안 표현이 포함되어 있음을 의미합니다.
이것은 분산 시스템을 위한 기본 요소입니다. merkledag는 추가 전용 인증 데이터 구조를 제공하여 분산 프로토콜을 단순화합니다. 당사자는 보안 참조 (merkle-links)를 객체와 교환하고 교환 할 수 있습니다. 참조는 나중에 객체의 정확성을 검증하기에 충분하므로 객체 자체가 신뢰할 수없는 채널을 통해 제공 될 수 있습니다. Merkledags는 또한 버전 제어 시스템 git에서와 같이 데이터 구조의 분기와 후속 병합을 허용합니다. 보다 일반적으로 merkledags는 인증 된 안전한 방법으로 분산, 수렴, 교환 가능하게하는 Secure CRDT의 구성을 단순화합니다.
Merkle Tree
머클트리는 이진 해시 트리 (Binary Hash Tree) 라고도 하며 해시 함수로 암호화된 해시값을 이진 트리로 구성된 데이터 구조로 분산 데이터 구조에 주로 쓰입니다.
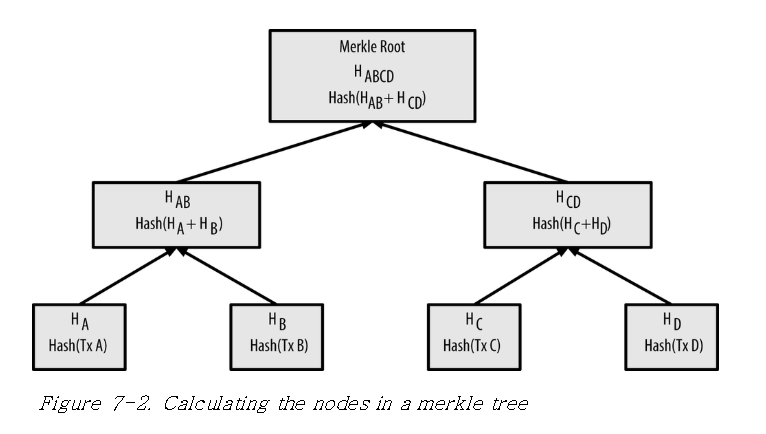
그림에서 보면 각 데이터 A, B, C, D의 해시값이 환산되고 A 해시와 B 해시의 합을 해시하여 AB 해시를 만들고 C 해시와 D 해시의 합을 또 해시하여 CD 해시를 만들어 AB 해시와 CD 해시의 합을 해시한 값을 머클 루트 혹은 탑 해시라고 합니다. 이 값은 매우 중요한데 데이터가 하나라도 바뀌면 이 값이 변하기 때문에 데이터가 위변조 되거나 데이터가 변환 되었는지 이 값을 비교하여 효울적으로 검증이 가능합니다. 머클트리는 비트코인 , 이더리움과 같은 블록체인에도 쓰이는데 이 머클 루트 값은 블록 헤더에 포함되는 중요한 값입니다.
데이터가 증가하면 다음과 같이 확대됩니다.
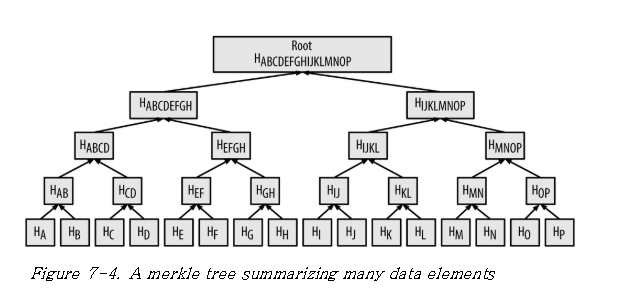
머클 루트는 이 수많은 데이터를 하나의 해시 값으로 나타낼 수 있습니다. 이러한 데이터 구조(Data Structure)는 다른 데이터 구조에 비해 많은 장점들을 가집니다. 우선 데이터를 찾고 처리하는 Look up time 을 낮출 수 있어 효율적입니다. 또한, 머클 루트 해시 값으로 데이터 무결성을 효율적으로 검증할 수 있으며 데이터 저장 용량이 중앙 데이터 베이스 구조보다 작기 때문에 확장성 문제 (Scalability)를 해결하는 좋은 방안입니다. IPFS는 이 머클 트리를 변형하여 머클 DAG로 데이터 구조를 설계하여 사용중 입니다.
Git (Merkle DAG)
버전 관리 시스템은 시간 경과에 따라 변하는 파일을 모델링하고 여러 버전을 효율적으로 배포 할 수 있는 기능을 제공합니다. 대중적인 버전 관리 시스템인 Git 은 분산된 방식으로 파일 시스템 트리에 대한 변경 사항을 캡쳐하는 강력한 Merkle DAG 객체 모델을 제공합니다.

- 불변한 객체는 파일(blob), 디렉토리(tree) 및 변경(commit)을 나타냅니다.
- 객체는 내용의 암호화 해시에 의해 내용이 처리됩니다.
- 다른 객체에 대한 링크가 내장되어 Merkle DAG를 형성합니다. 이것은 많은 유용한 무결성 및 작업 흐름 속성을 제공합니다.
- 대부분의 버전 관리 메타 데이터(분기, 태그 등)는 포인터 참조 일 뿐이므로 생성 및 업데이트 비용이 저렴합니다.
- 버전 변경은 참조를 업데이트 하거나 객체를 추가하면 됩니다.
- 다른 사용자에게 버전 변경 사항을 배포하는 것은, 단순히 객체를 전송하고 원격 참조를 업데이트 하는 것 입니다.
Merkle DAG는 Merkle Tree와 약간 다릅니다. Merkle DAG가 더 일반적인 개념인 것이, Binary Tree는 아니지만 그래프이며, 아무 노드나 데이터를 보유할 수 있다는 점입니다. - Merkle Tree에서는 leaf node(가장 아래 세대의 노드만 데이터 보유 가능)
Merkle DAG 구조를 통해, IPFS는 다음과 같은 세가지 중요한 특성을 갖습니다.
- Content Addressing : 모든 컨텐츠는 그 자체가 링크이며, multihash checksum으로 그 무결성을 확인할 수 있습니다.
- Tamper resistance : 모든 컨텐츠는 자체적으로 checksum으로 무결성을 확인할 수 있고, 위변조시 merkle root의 hash값이 변경되기 때문에 IPFS 자체적으로 감지할 수 있습니다.
- Deduplication : 같은 컨텐츠는 같은 해시값을 갖기 때문에, Merkle DAG 상에서 컨텐츠가 중복되지 않습니다.
정의
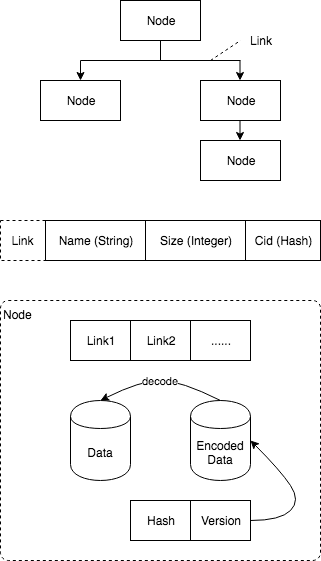
그림의 상단에 표기된 노드는 데이터와 데이터의 종속 링크 관계를 저장하고 링크는 데이터를 저장합니다. 해시 값은 링크가 데이터의 해시 값이므로이 데이터 구조를 Merkle DAG라고합니다.
그림의 가운데 세 부분으로 구성된 링크의 데이터 구조는 다음과 같습니다.
- Name: 하위 데이터의 이름
- Size: 하위 데이터의 크기
- Cid: IPFS 네트워크에서 데이터를 찾을 수 있는 하위 데이터의 해시 인덱스.
그림의 가장 아래부분은 하위 계층의 모든 링크 데이터, 하나의 노드 자체의 데이터, 하나의 노드 데이터의 캡슐화 후 데이터 및 캡슐화 된 데이터를 저장하는 노드의 데이터 구조를 나타냅니다.
포멧
IPFS merkledag 형식은 매우 간단합니다. 보다 복잡한 애플리케이션 및 데이터 구조 전송을 위한 허리 역할을 합니다. 그러므로 가능한 간단하고 작게하는 것을 목표로 합니다.
형식은 논리적 형식과 직렬화 된 형식의 두 부분으로 구성됩니다.
Logical 포멧
merkledag 형식은 Nodes와 노드 사이의 Links 두 부분을 정의합니다. Nodes는 Link Segement (또는 링크 테이블)에 Links를 포함합니다.
노드는 두 부분으로 나뉩니다:
-
Link Segment: 모든 링크 포함 -
Data Segment: 오브젝트 데이터 포함
IPFS merkledag는 데이터를 대부분 가장자리에 배치하는 merkledags에 대한 이전 접근 방식 대신 HTTP 웹 형식을 채택합니다. 모든 경로 끝점은 링크와 데이터가 모두 포함 된 객체입니다. (이는 오브젝트가 링크 (디렉토리) 또는 데이터 (파일)를 갖는 UNIX 파일과 근본적으로 다릅니다.)
Logical 포멧 (protobuf)은 다음과 같습니다.
// An IPFS MerkleDAG Link
message MerkleLink {
bytes Hash = 1; // multihash of the target object
string Name = 2; // utf string name
uint64 Tsize = 3; // cumulative size of target object
// user extensions start at 50
}
// An IPFS MerkleDAG Node
message MerkleNode {
repeated MerkleLink Links = 2; // refs to other objects
bytes Data = 1; // opaque user data
// user extensions start at 50
}
Serialized 포멧
Logical 포멧은 직렬화 형식인 프로토콜 버퍼를 사용하여 raw 바이트로 직렬화 됩니다.
동작 구성
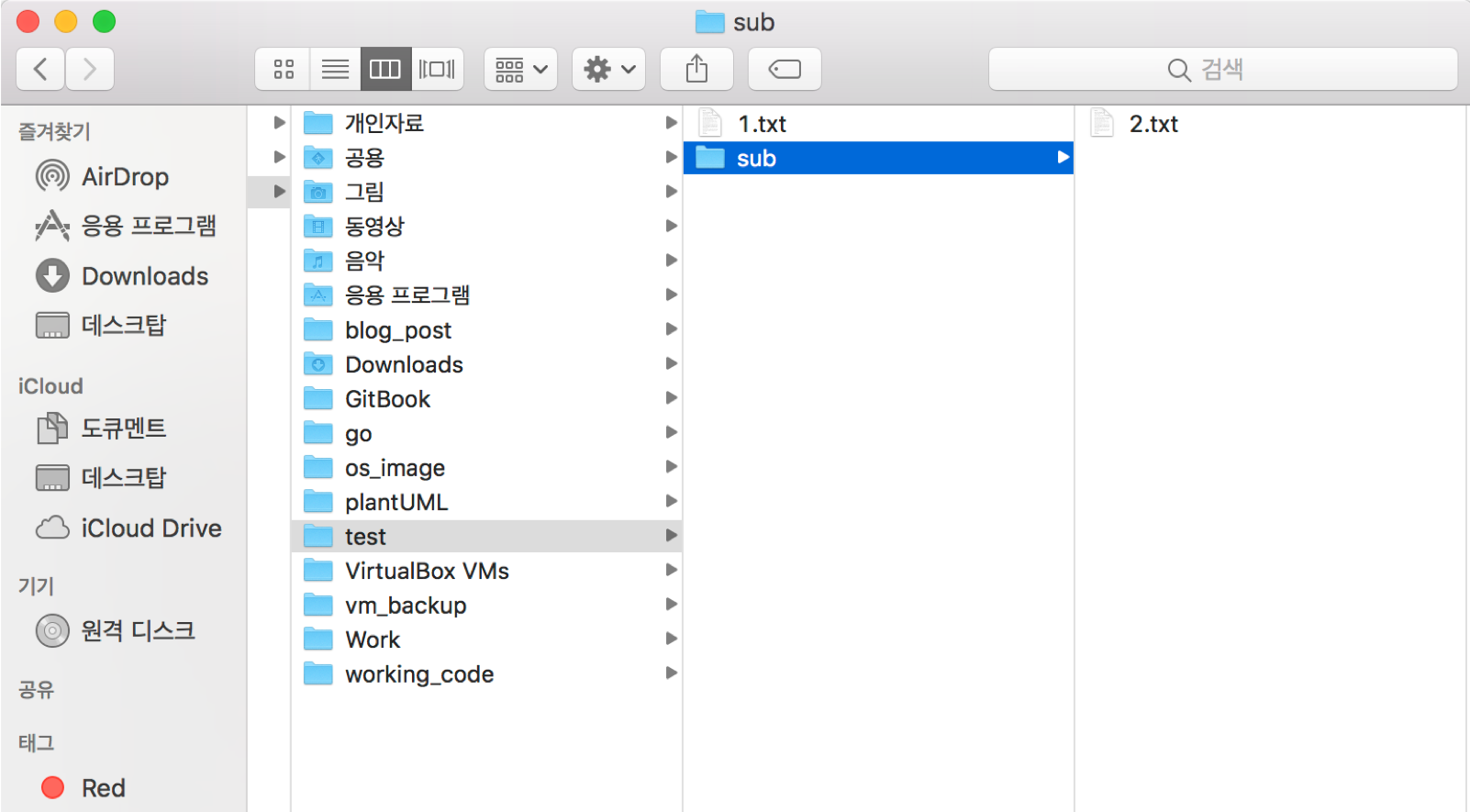
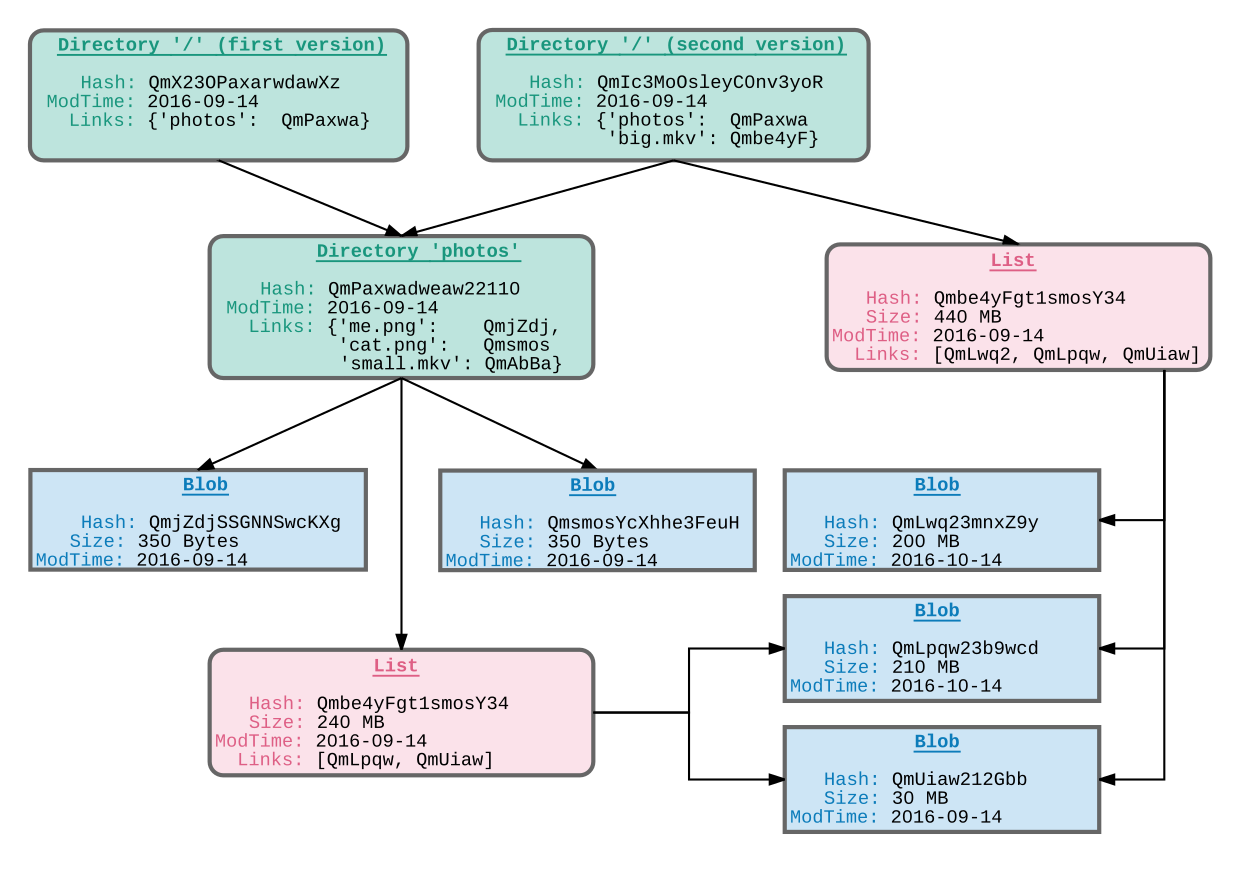
위 그림과 같이 test 디렉토리를 만들고 텍스트 파일과 디렉토리 아래에 다른 디렉토리가 만들고 텍스트 파일을 추가합니다. 이 디렉토리 구조는 비교적 간단합니다. 그런 다음 다음 IPFS 명령을 통해 IPFS 네트워크에 업로드 합니다.
uni2u@uni2u-imac$ ipfs add -r test/
[added QmZ6LH8CHpfhf6f9cnu1XMieT4wSUPXHePAs97NzVjEStE test/1.txt
added QmcA9f6fHP75U6VMVFcVr2wrNVGxtJa2hy92jXVfsSexuN test/sub/2.txt
added QmXEu5pU8t2NZUqLz22Mz9jLrVff5jAPF2jzXsncuTJagf test/sub
added QmTxemKoT9m1vRqrG3zdaEv51yFCQw2frgf4vi1gsA4FhD test
20 B / 244 B [====>-----------------------------------------] 8.20%uni2u@uni2u-mac$
업로드가 성공적으로 완료되면 인터페이스는 위와 동일합니다.이 인터페이스는 test 디렉토리의 업로드 정보를 명확하게 보여줍니다.
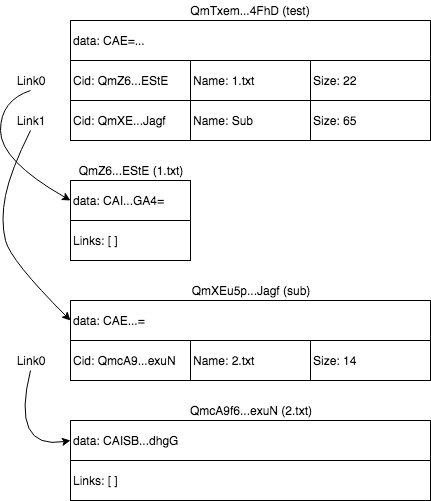
데이터 구조에 따르면, test 디렉토리는 위와 같이 저장됩니다. 첫째, 이 디렉토리에 디렉토리와 파일이 있기 때문에 test 전체 디렉토리 해시 값이 있습니다. 두 개의 링크가 있는데 이 두 링크는 각각 데이터 노드 이름, 크기 및 해시 값을 설명합니다. 이 노드의 데이터는 디렉토리 (CAE =)를 나타냅니다.
다음은 1.txt 파일에 해당하는 노드 데이터 입니다. 이 노드 데이터에는 다음 수준의 데이터 구조가 없으므로 해당 링크가 빈 배열이고 해당 데이터는 1.txt 텍스트 내용의 인코딩 된 데이터 종류입니다.
유추는 디렉토리 sub와 2.txt의 노드 데이터와 링크 데이터를 얻을 수 있습니다. 다음으로 IPFS 관련 명령을 사용하여 데이터를 확인합니다.
uni2u@uni2u-imac$ ipfs dag get QmTxemKoT9m1vRqrG3zdaEv51yFCQw2frgf4vi1gsA4FhD
{"data":"CAE=","links":[{"Cid":{"/":"QmZ6LH8CHpfhf6f9cnu1XMieT4wSUPXHePAs97NzVjEStE"},"Name":"1.txt","Size":22},{"Cid":{"/":"QmXEu5pU8t2NZUqLz22Mz9jLrVff5jAPF2jzXsncuTJagf"},"Name":"sub","Size":65}]}
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs dag get QmZ6LH8CHpfhf6f9cnu1XMieT4wSUPXHePAs97NzVjEStE
{"data":"CAISDnRoaXMgaXMgMS5OeHQKGA4=","links":[]}
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs dag get QmXEu5pU8t2NZUqLz22Mz9jLrVff5jAPF2jzXsncuTJagf
{"data":"CAE=","links":[{"Cid":{"/":"QmcA9f6fHP75U6VMVFcVr2wrNVGxtJa2hy92jXVfsSexuN"},"Name":"2.txt","Size":14}]}
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs dag get QmcA9f6fHP75U6VMVFcVr2wrNVGxtJa2hy92jXVfsSexuN
{"data":"CAISBjIudHh0ChgG","links":[]}
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs get QmTxemKoT9m1vRqrG3zdaEv51yFCQw2frgf4vi1gsA4FhD/1.txt
Saving file(s) to 1.txt
22 B / 22 B [===========================================================] 100.00% 0s
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs dag get QmTxemKoT9m1vRqrG3zdaEv51yFCQw2frgf4vi1gsA4FhD/1.txt
{"data":"CAISDnRoaXMgaXMfMS50eHQKGA4=","links":[]}
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs dag get QmTxemKoT9m1vRqrG3zdaEv51yFCQw2frgf4vi1gsA4FhD/sub
{"data":"CAE=","links":[{"Cid":{"/":"QmcA9f6fHP75U6VMVFcVr2wrNVGxtJa2hy92jXVfsSexuN"},"Name":"2.txt","Size":14}]}
uni2u@uni2u-imac$
uni2u@uni2u-imac$ ipfs dag get QmTxemKoT9m1vRqrG3zdaEv51yFCQw2frgf4vi1gsA4FhD/sub/2.txt
{"data":"CAISBjIudHh0ChgG","links":[]}
위 내용은 IPFS의 DFS 명령을 통해 데이터 및 링크 정보를 쿼리하는 것입니다. 해시 값과 파일 또는 디렉토리 이름을 사용하여 노드의 관련 정보를 올바르게 쿼리 할 수 있습니다. 즉 링크의 해시 또는 링크의 이름 필드를 통해 관련 노드 데이터를 직접 쿼리 할 수 있습니다. 이 방법은 웹 사이트를 방문하거나 IP 주소를 통해 웹 사이트에 액세스하거나 도메인 이름을 통해 웹 사이트에 액세스 할 때와 비슷합니다. 이것이 Merkle DAG 레이어가 IPFS 네트워크 프로토콜 아키텍처의 IP 레이어라고 불리는 이유입니다.
인터페이스
Merkle DAG의 관련 인터페이스를 살펴 보면 다음과 같습니다. Get 인터페이스의 일부는 다음과 같습니다.
type NodeGetter interface {
// Get retrieves nodes by CID. Depending on the NodeGetter
// implementation, this may involve fetching the Node from a remote
// maching; consider setting a deadline in the context.
Get(context.Context, *cid.Cid) (Node, error)
// GetMany returns a channel of NodeOptions given a set of CIDs.
GetMany(context.Context, []*cid.Cid) <-chan *NodeOption
}
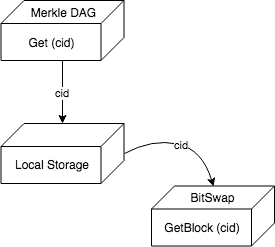
위의 그림에서 Merkle DAG 계층은 Get 명령어를 수신하면 인터페이스에서 Get (cid) 메소드를 호출합니다.이 메소드는 먼저 Cid 정보에 따라 로컬로 저장된 데이터를 찾아 관련 데이터 블록을 검색하고, 데이터 교환의 GetBlock (Cid) 메서드는 네트워크를 통해 데이터를 가져 오는 데 사용됩니다.
Merkle DAG의 데이터 구조를 구현하는 데 사용 된 인터페이스 객체는 아래와 같이 데이터 교환 레이어를 정의합니다.
type BlockService interface {
io.Closer
BlockGetter
// Blockstore returns a reference to the underlying blockstore
Blockstore() blockstore.Blockstore
// Exchange returns a reference to the underlying exchange (usually bitswap)
Exchange() exchange.Interface
// AddBlock puts a given block to the underlying datastore
AddBlock(o blocks.Block) error
// AddBlocks adds a slice of blocks at the same time using batching
// capabilities of the underlying datastore whenever possible.
AddBlocks(bs []blocks.Block) error
// DeleteBlock deletes the given block from the blockservice.
DeleteBlock(o *cid.Cid) error
}
type blockService struct {
blockstore blockstore.Blockstore
exchange exchange.Interface
// If checkFirst is true then first check that a block doesn't
// already exist to avoid republishing the block on the exchange.
checkFirst bool
}
Discussion
Real World Examples
많은 성공적인 분산 시스템은 전문 merkledags를 핵심으로 사용:
- merkle trees (merkle dag의 special case) 대량의 데이터를 인증하는데 사용되는 잘 알려진 암호화 기술입니다. 원래의 유스 케이스에는 일회성 lamport 서명이 포함되었습니다.
- SFS-RO는 유닉스 파일 시스템을 merkledag로 바꾸어 안전한 분산 파일 시스템을 제공합니다.
- git은 merkledag를 사용하여 분산 버전 제어 및 소스 코드 관리를 가능하게 합니다. 다양한 변경(mercurial), 단조로움(monotone)과 같은 다른 DVCSes도 merkledag를 특징으로 합니다.
- plan9는 merkledag를 사용하여 스냅 샷 파일 시스템 (Fossil 및 Venti)을 구성합니다.
- bittorrent는 다운로드 가능한 torrent에 안전하고 짧은 intohash 링크를 제공하기 위해 merkledag를 사용합니다.
- Google Wave (분산 커뮤니케이션 플랫폼)는 merkledag를 사용하여 교환 가능한 운영 변환을 구성하고 융통성있는 분산 공동작업을 지원합니다. 이 기능은 이후 Google 문서도구로 통합되었습니다.
- bitcoin은 merkledag를 사용하여 집중 분산 컨센서스가 있는 공유 추가 전용 원장 인 블록 체인을 구성합니다.
- Tahoe-LAFS는 merkledag를 사용하여 최소 권한 원칙에 기반한 안전하고 분산된 기능 파일 시스템을 구축합니다.
Thin Waist of Data Structures
IPFS는 merkledag를 기본(또는 “Internet layer”)으로 제공하여 정교한 응용 프로그램을 쉽게 구축 할 수 있습니다. 이는 모든 복제, 라우팅 및 전송 프로토콜에 걸쳐 (공통 형식을 따르기로 합의함으로써) 실행될 수 있는 안전한 분산형 애플리케이션에 대한 “Thin-Waist” 입니다. 유추를 이끌어 내기 위해 이것은 특정 네트워크를 통해 호스트를 연결하기 위해 제공되는 “Thin-Waist” IP와 같습니다.


이러한 종류의 모듈화는 공통 기반을 통해 쉽게 복잡하고 강력한 애플리케이션을 작성할 수 있습니다. 인증, 배포, 복제, 라우팅 및 전송의 모든 복잡성은 다른 프로토콜과 도구에서 가져올 수 있습니다. 이러한 종류의 모듈화는 계층화된 인터넷(TCP/IP 스택)을 엄청나게 강력하게 만들었습니다.
Web of Data Structures
어떤 점에서 IPFS는 merkledag를 공통 분모로 갖는 “데이터 구조의 웹”입니다. 형식에 동의하면 서로 다른 인증 된 데이터 구조를 서로 연결할 수 있어 정교한 분산 응용 프로그램이 데이터를 쉽게 작성, 배포 및 연결할 수 있습니다.
Linked Data
merkledag는 일종의 Linked-Data입니다. 링크는 표준 URI 형식을 따르지 않고 보다 일반적이고 유연한 UNIX 파일 시스템 경로 형식을 선택하지만 주요 내용은 모두 여기에 있습니다. JSON-LD와 같은 형식을 IPFS-LD(IPFS-LD)에 직접 매핑해 시멘틱 웹의 성능을 최대한 활용할 수 있습니다.
콘텐츠 (및 ID) 주소 지정의 강력한 결과는 링크된 데이터 정의를 콘텐츠 자체와 함께 직접 배포 할 수 있으며 원래 위치에서 제공 할 필요가 없다는 것입니다. 이를 통해 링크 된 데이터 정의, 사양 및 네트워크에서 가져올 필요가 없거나 연결이 끊어 지거나 완전히 오프라인이 될 수 있는 응용 프로그램을 만들 수 있습니다.
Merkledag Notation
다른 데이터 구조 및 프로토콜의 정의를 용이하게하기 위해 Merkledag 데이터 구조를 표현하는 표기법을 정의합니다. 이는 논리적 표현을 정의하고 형식 스펙 (ipfs merkledag 형식을 사용할 때)을 정의합니다.
tree node {
links {
}
data {
}
}
commit node {
"parent" repeated link; // links to the parent commit
"author" link; // link to the author of commit
""
}
아직 끝난것이 아니고 계속 진행중
Reference
File Exchange in IPFS
File Exchange (IPFS BitSwap Protocol)
BitSwap은 BitTorrent에서 영감을 얻은 프로토콜입니다. BitTorrent에서처럼, Peer들은 본인이 얻고 싶은 파일블록(want_list)와 본인이 갖고 있는 파일블록(have_list)가 있습니다. 그러나, BitTorrent는 하나의 파일을 받고자할 때 그 파일의 블록들만 한정적으로 받아올 수 있는 반면, BitSwap에서는 일치하는 파일블록이라면 어떤 파일에 속해 있든지 받아올 수 있다는 장점이 있습니다.
만약 노드들이 받기만 하려고하고 줄 생각이 없다면 문제가 발생합니다. 이를 해결하기 위해 BitSwap는 기본적으로 물물교환 시스템(barter system)을 표방합니다. 무언가 받기 위해서는 무언가 주어야합니다. 상대방에게 내가 원하는게 있지만, 내가 대가로 줄게 없으면 (filecoin 구상이 시작된 배경이기도 합니다.) 그 노드는 열심히 일해서 굉장히 희귀한 파일블록이라도 얻어서 보유해놓아야 합니다. (이는 희귀한 파일블록들이 더욱 배포, 확산되는 효과를 낳습니다.)
또한 BitSwap Credit 시스템을 통하여, 노드들이 peer에게 파일블록을 보내주면, 보낸 노드는 자산이 증가하며, 받은 노드는 부채가 증가하게 됩니다. 결국 평판이 쌓이는 구조이므로 받기만 하려는 어뷰징을 막을 수 있고, 파일블록을 보유하고 보내주는 것에 인센티브가 생기게 됩니다.
BitTorrent에서는 Tit-for-tat(눈에는 눈, 이에는 이) 전략이 표준으로 되어있지만, BitSwap의 노드들은 각자 자신의 전략을 설정할 수 있습니다. 이러한 전략들의 총체는 곧 BitSwap 생태계의 성능을 좌우하게 될 것 입니다.
IPFS의 File Exchange 특성인 IPFS BitSwap Protocol을 알아보기 위하여 우선 그 기본인 BitTorrent를 짚고 넘어가겠습니다.
BitTorrent
BitTorrent는 오늘날 개별 파일 공유에 가장 많이 사용하는 대표적인 프로토콜입니다. 또한 저작권 측면에서 보면 2010년 이래에 20만명 이상이 저작권으로 고소당하기도 했던 장본인이기도 합니다. 2001년 Bram이 처음 만든 이 프로토콜은 BitTorrent-Protocol을 참고하기 바랍니다.
IPFS는 BitSwap Protocol의 기본을 위한 BitTorrent
BitTorrent는 트래픽을 어지럽히는 주범이라고 하지만 오늘날 트래픽의 가장 큰 부분을 차지하고 있는 프로토콜입니다. 기존의 서버-클라이언트 방식이 아닌, 클라이언트-클라이언트 방식의 P2P를 사용합니다. P2P 방식을 이용하여 자료를 공유하면 공유하는 사용자가 많을수록 다운로드 속도가 빨라지는 특징을 보입니다.
특징
P2P(Peer-to-Peer) 방식을 사용하는 프로토콜로 서버-클라이언트 구조의 일대일 공유 방식이 아닌 클라이언트-클라이언트 구조의 일대다 파일 공유 방식을 사용합니다.
일대일 파일 공유 방식은 서버가 원본 파일을 가지고 있고 클라이언트가 서버로부터 원본 파일을 받아가는 방식(그림의 a)입니다. 일대일 파일 공유 방식은 인터넷 환경과 서버의 성능/정책에 따라 파일 전송 속도가 결정되며 전송이 완료될 때까지 유지됩니다.
일대다 파일 공유 방식(그림의 b)은 원본 파일을 조각(piece)으로 나누어 각 클라이언트간 조각을 교환하는 방식입니다. 각 클라이언트들은 파일을 공유하는 새로운 클라이언트를 발견하면 자신의 조각 정보를 알려주고 새로운 클라이언트에게 자신이 필요한 조각을 요청합니다. 이러한 방식은 하나의 클라이언트에 여러 클라이언트가 세션을 생성하게되고 세션이 늘어나면 사용자의 다운로드 속도가 늘어나 클라이언트가 사용하는 인터넷 환경의 최대 대역폭까지 다운로드 속도를 증가시킵니다.
동작원리
BitTorrent는 P2P 방식을 사용하는 대표적인 프로토콜입니다. P2P 방식은 클라이언트와 클라이언트 간에 세션이 직접 생성되어 공유하고자 하는 파일을 여러 개의 조각(Piece)으로 나누어 주고받는 것이 특징입니다.
대표적인 공유 정책으로 ”optimistic unchoking” 메커니즘이 있습니다. 해당 메커니즘은 클라이언트의 대역폭을 일부 강제적으로 할당하여 무작위로 피어들에게 조각을 보내어 모든 피어들이 일정한 조각을 가지도록 하며, 이와 같은 원리를 통해 공유 속도와 효율성을 증대하였습니다.
- Piece(조각): 공유 파일을 작게 조각 낸 파일
- Seeder(시더): 공유 파일 완전체를 가지고 있는 클라이언트 (파일의 모든 조각을 소유)
- Leecher(리처): 공유 파일 불완전체를 가지고 있는 클라이언트 (파일의 일부 조각만을 소유)
- Peer(피어): 시더와 리처를 합한 의미
- Tracker(트래커): 피어들의 정보를 관리하는 서버
- Swarm(스웜): 각 공유 파일마다 존재하며, 공유 파일에 대한 고유 식별자(Hash)와 공유 파일을 소유하고 있는 피어 리스트 정보를 가짐
.torrent file
요청파일 고유의 Hash 값이 포함되어 있으며 트래커의 URL 주소가 포함되어 있습니다. Hash 값은 파일 식별자로써 동일한 파일 이름을 가진 다른 컨텐츠와 구분을 위하여 생성되는 고유의 값이며 트래커의 URL은 파일을 공유하는 피어들의 정보를 관리하는 서버(트래커)를 지정하는 것 입니다.
Tracker Request
다운로드 받고자 하는 사용자가 토렌트 파일을 실행하면 BitTorrent 클라이언트는 토렌트 파일에 포함된 요청파일의 고유 Hash 값을 트래커(토렌트 파일에 포함되어 있는 URL)로 전송하는데 이 메시지를 의미(HTTP Get과 비슷한 의미)합니다. 동일한 토렌트 파일을 사용하여 요청파일을 공유하고 있는 모든 피어들은, 트래커에게 해당 파일의 Hash 값을 보내게 되며 피어들로부터 Tracker Request를 받은 트래커는 해당 파일의 Hash값에 해당하는 스웜(Swarm)을 생성하고 해당 파일의 Hash 값을 보낸 피어 IP 주소를 스웜을 통해 관리합니다.
Tracker Response
Tracker Request 패킷을 전송 받은 트래커는 피어들에게 Tracker Response 패킷을 전송합니다. 이 때 트래커는 피어들이 보낸 식별자에 대한 스웜이 존재하는지 파악하고, 존재하지 않는다면 다른 피어가 Tracker Request 패킷을 보낼 때까지 대기합니다. 스웜이 생성되면 Tracker Request 동작을 수행하고 있던 피어 리스트를 피어들에게 전송하는데 이 때의 메시지 또는 패킷을 Tracker Response 라고 합니다. 피어 리스트는 기본으로 50개의 피어 IP 주소로 구성되며, 만약 스웜에 저장되어 있는 피어들의 주소가 50 이상이라면 무작위로 피어 주소들을 리스트로 구성하여 전송하게 되고, 50 개 미만이면 모든 피어 리스트를 전송합니다.
File Download
트래커로부터 Peer 리스트를 받은 피어들은 서로에게 공유 파일의 식별자를 전송합니다. 식별자를 전송 받은 피어들 중 파일 조각을 보유하고 있어, 해당 공유파일에 대한 공유가 가능한 피어라면, 동일한 식별자를 공유를 요청한 피어에게 전송하여 서로 간의 공유 세션을 형성합니다. 이 때 피어들은 피어 리스트에 의해 최대 50 개의 세션을 동시에 형성하게 되고, 공유 파일은 일정 크기의 조각으로 나뉘어 공유합니다. 그 후, 피어들은 자신이 가지고 있는 조각을 파악하고 자신이 가지고 있지 않은 조각을 다른 피어에게 요청하며, 자신이 가지고 있는 조각을 다른 피어가 필요로 하면 조각을 해당 피어에게 전송합니다. 이와 같은 과정을 통해 다운로드와 업로드가 동시에 일어나게 됩니다.
.torrent 구조 (시드 파일 구조)
시드 파일은 일반적으로 토렌트 파일이라고도 불리며, 파일 공유를 위한 여러 메타데이터를 담고 있는 메타파일 입니다. 공유파일이 하나인 싱글 시드 파일과 공유파일이 여러 개인 멀티 시드 파일로 구분할 수 있습니다.
| Name | Parameter | 설명 |
|---|---|---|
| Torrent | Filename | 토렌트 파일명 (파일명.torrent) |
| Info Hash | 공유 파일의 Hash 값 | |
| Tracker | Tracker URL | 트래커 URL 주소 / 여러 트래커 주소 포함 가능 |
| Metadata | Directory | 토렌트 파일이 저장되는 디렉토리 이름 (싱글 시드 파일과 멀티 시드 파일 구분) |
| Created On | 토렌트 파일 생성 일시 | |
| Created By | 토렌트 파일 생성자 정보 | |
| Comment | 생성자의 코멘트 | |
| Piece Length | 피어간 주고받을 조각 크기 / 최소 128KByte | |
| Private | 개인 파일 여부 On/Off | |
| Files | Filename | 공유 파일 실제 파일명 |
Directory, Piece Length, Private, Filename이 Hash 값을 생성하기 위해 사용되는 파라미터입니다. 기존 P2P는 하나의 파일만 주고받을 수 있었지만 BitTorrent는 하나의 토렌트 파일 안네 여러 파일을 포함시킬 수 있습니다. (토렌트 파일의 “Directory” 를 지정하여 “Files” 내 여러 개의 파일을 포함 시켜서 배포 가능)
Peer to Tracker 통신
Peer와 Tracker 통신은 HTTP를 사용하며 클라이언트가 실행한 토렌트 파일(.torrent)에 포함된 정보를 통해 트래커에게 피어 리스트를 요청합니다. 요청을 받은 트래커는 클라이언트의 Hash 정보를 기반으로 스웜에 속한 피어들의 리스트를 요청한 후 클라이언트에 전송합니다.
Tracker Request 및 Tracker Response 에서 전달되는 정보들은 다음 표와 같습니다.
| Message | Parameter | 설명 |
|---|---|---|
| Tracker Request | info_hash | 토렌트 파일에 포함된 공유 파일의 Hash 정보 |
| peer_id | 클라이언트 식별 ID | |
| port | Tracker Response 메시지용 클라이언트 port | |
| upload | 업로드 파일 합 (바이트) | |
| download | 다운로드 파일 합 (바이트) | |
| left | 다운로드 받을 남은 파일 크기 합 (바이트) | |
| key (option) | 클라이언트 IP 변경에 무관하게 클라이언트 인식을 위한 값 (피어간 공유하지 않음) | |
| event | Started: 파일전송 시작 / Stopped: 파일전송 중지 / Completed: 파일전송 완료 | |
| numwant (option) | 몇개의 피어 정보를 받을것인지 요청 (기본: 50) | |
| compact | Set1: 피어들의 IP 주소와 Port 정보만 받음 / Set0: IP 주소와 Port 외에 Peer-ID 등의 정보를 받음 | |
| no_peer_id | Peer-ID는 생략하고 정보 요청 (Compact=1의 경우 무시) | |
| ip (option) | 클라이언트 IP 주소 | |
| Tracker Response | complete | 현재 파일 공유 시더 수 |
| downloaded | 공유 파일 다운로드 완료 횟수 | |
| incomplete | 현재 파일을 다운로드 하고 있는 리처 수 | |
| interval | Tracker Request 전송 Interval (단위: 초) | |
| min interval (option) | Tracker Request 전송 최소 Interval (단위: 초) | |
| peers | 피어 IP 리스트 |
Peer to Peer 통신
트래커를 통해 피어 리스트를 받은 BitTorrent 클라이언트는 리스트에 있는 피어들과 BitTorrent 프로토콜을 이용하여 통신을 시작합니다. 클라이언트는 파일을 교환하기 위하여 피어들과 서로의 정보를 주고 (Handshake) 받습니다.
이후 피어들은 자신이 가지고 있는 조각의 정보를 피어들에게 주기적으로 알려주며 자신이 필요한 조각은 대상 클라이언트에게 요청하여 조각을 받습니다.
클라이언트는 Handshake(1~4) 이후 피어 1과 피어 2에서 Have 메시지(5~6)를 받았습니다. 해당 Have 메시지에는 피어 1과 피어 2가 가지고 있는 조각의 정보가 포함되어 있습니다. 이러한 Have 메시지를 통해 사용자는 피어 1이 가지고 있는 조각을 알게 됩니다. 0x000001ed라는 조각을 피어 1에게 요청(Request 메시지)하여 피어 1로부터 해당 조각을 Piece 메시지를 통해 전송 (7~8) 받게 됩니다.
이후 사용자는 자신이 새로운 조각을 가지게 되었으므로 Have 메시지를 통해 0x000001ed인 조각을 자신이 가지고 있다고 피어 1과 피어 2에게 (9~10) 알립니다. 피어 2에서 0x000001ed인 조각을 사용자에게 요청하는 경우(11), 사용자는 자신이 가지고 있는 조각이므로 피어 2에게 해당 조각을 전송(12) 합니다. 이러한 방식으로 피어와 피어 간에 조각 교환이 계속하여 발생하게 됩니다.
피어간 통신에 사용되는 메시지는 다음표와 같습니다.
| Message | 설명 |
|---|---|
| Keep-alive | 대상 피어가 온라인 상태인지 체크하는 메시지 |
| Choke | Request 에 대한 응답을 할 수 없음을 알리는 메시지 |
| Unchoke | Choke 상태를 해지하여 Request 에 대한 응답이 가능함을 알리는 메시지 |
| Have | 자신이 가지고 있는 조각의 정보를 피어들에게 알리는 메시지 |
| Request | 받고자 하는 조각의 Index와 Offset 정보를 대상 피어에게 알리는 메시지 |
| Piece | 실제 파일 조각, Index 및 Offset 정보가 보함된 메시지 |
Reference
Distributed Hash Tables in IPFS
DHT (Distributed Hash Tables)
분산 해시 테이블을 의미하는 것으로 말 그대로 해시 테이블을 분산하여 관리하는 기술 입니다.
어떤 항목을 찾아갈 때 해시 테이블을 이용하는데, 중앙 시스템이 아닌 각 노드들이 이름을 값으로 맵핑하는 기능을 하는 방식으로 부하가 집중되지 않고 분산된다는 큰 장점이 있어, 극단적으로 큰 규모의 노드들도 관리할 수 있습니다.

살짝 감이 오지 않습니까? IPFS 의 주요 기능말입니다.
분산 해시 테이블에 대한 기본 이해
해시 테이블은 Key/Value 데이터 구조로 구성되어 있습니다. DHT는 해싱으로 생성된 데이터 Key 값과 서버 ID 의 짝을 시스템을 구성하고 있는 모든 노드에 균일하게 분산하기 위하여 고안된 lookup 방법입니다. 데이터 Key 값과 서버 ID 를 통하여 모든 노드와 데이터들을 동일 주소 공간에 할당함으로써 데이터와 노드 정보들을 한꺼번에 관리하기가 용이하기 때문에 P2P 시스템에서 많이 사용합니다. (데이터의 Key 값과 분산 서버 ID는 동일한 해시 함수로 동일한 주소 공간에 데이터와 노드를 배치)
한마디로 중앙 서버 없이 데이터를 관리하는 분산된 서버를 찾을 수 있으며 클러스터에 참여하는 서버의 추가/제거가 자동으로 이루어질 수 있도록 구성할 수 있기 때문입니다.
부하가 집중되지 않고 분산된다는 큰 장점이 있어, 극단적으로 큰 규모의 노드들도 관리할 수 있습니다. 종래의 순수 P2P에서 채용되었던 방식에서는 수십만 노드 정도가 한계였으나, DHT의 사용으로 수십억개의 노드를 검색범위로 할 수 있게 되었습니다.
IPFS 에서는 Kademlia DHT 와 BitTorrent 그리고 Git, Self-certifying File System 에 대한 이해를 필요로 합니다.
각각은 차차 알아보기로 하고 조금 더 DHT 에 대한 이야기를 해보겠습니다.
IPFS 에서 DHT
네트워크에 참여한 노드가 해시 테이블을 사용하여 서버없이 P2P 네트워크를 실현하는 기술로 파일(데이터, 컨텐츠)을 검색하는데 사용됩니다.
HTTP는 IP를 기반으로 검색이 되었으나 IPFS는 Content-Addressed를 사용합니다. 즉, 컨텐츠 자체가 주소역할을 대신 합니다.
| Content Name | Node Location |
|---|---|
| Content01 | Node01 |
| Content02 | Node03, Node05 |
| Content03 | Node02, Node08 |
해시테이블에서 컨텐츠 이름을 찾으면 컨텐츠를 보유하고 있는 노드를 알 수 있습니다.
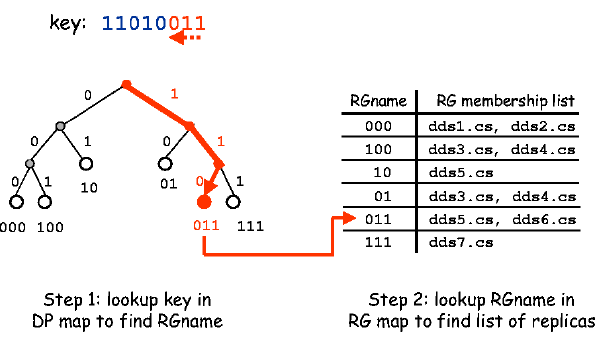
Kademlia DHT
Kademlia는 현재 가장 대중적으로 사용되는 P2P DHT 입니다. Kademlia는 다음과 같은 용어에 대한 이해가 필요합니다.
- Node: node는 Kademlia DHT 네트워크에 참여하는 컴퓨터
- pair (Key/Value): KV(Key/Value) 형태로 데이터를 저장, Kademlia 네트워크에서 값을 찾기 위한 고유 키이며 값은 DHT에 저장되는 데이터
- LookUP: Kademlia 네트워크에서 주어진 키에 대한 실제 값을 찾는 과정
- Data/Content: Kademlia DHT에 pair(KV) 형태로 저장되어 있는 실제 데이터
Kademlia를 사용하는 이유
- Node간 주고받는 데이터를 최소화
- 네트워크에 속한 node, 인접 node 등에 대한 설정 정보가 자동적으로 Kademlia 네트워크에 확산
- Kademlia 네트워크의 node들은 다른 node를 통해 파악 (적은 비용으로 node간 경로 탐색)
- Kademlia는 작동하지 않는 node의 timeout을 피할 수 있는 병렬적이고, 비동기적 쿼리 제공
- DOS 공격 방지
Key
Kademila는 Node와 데이터를 식별하기 위해 160 비트 key를 이용합니다. 네트워크에 참여하는 컴퓨터는 각각 160 비트 NodeId 키를 가집니다. Kademila는 pair(KV)로 데이터를 저장하기 때문에 160 비트 key를 사용해서 데이터를 식별합니다.
Distance
두 Node 간의 ‘거리’를 계산하는 것으로 두 NodeId의 XOR로 계산되고 정수형 값을 가집니다. Key와 NodeId는 같은 형태, 길이의 정수형 값을 가지고 있기 때문에 XOR연산이 가능합니다. NodeId는 Node를 식별할 수 있는 무작위의 정수형 값(UUID)을 가집니다. 즉, 물리적 거리가 먼 Node라도 NodeId 값이 비슷하다면 논리적으로 이웃에 위치할 수 있습니다.
- 임의의 Node와 그 Node 자신에 대한 거리는 0
- XOR 연산은 대칭성을 가짐: A에서 B 거리의 계산 결과는 B에서 A 거리와 동일
- 삼각 부등식 성립: A, B, C Node가 주어질 경우, A와 B 사이 거리는 A와 C 또는 C와 B의 거리합과 같거나 작음
위와 같은 특징은 간단하면서 빠른 XOR 연산의 특징을 보여줍니다.
Kademlia 탐색 작업이 반복될 때마다 한 비트씩 탐색 대상에 가까워집니다. 2^n 개의 Node를 가지고 있는 Kademlia 네트워크에서는 최대 n번 탐색을 반복하면 임의의 Node를 찾을 수 있습니다.
라우팅 테이블
각 NodeId들의 각 비트를 저장한 리스트를 포함하고 있습니다. 리스트의 모든 항목은 다른 Node들의 위치에 대한 주요 정보를 저장합니다. 리스트의 각 항목은 일반적으로 다른 Node의 IP 주소, 포트, NodeId를 저장합니다. 후보 id의 n-1번째 비트는 NodeId와 일치하여야 합니다. (모든 리스트는 특정 node의 거리와 대응됩니다. n번째 리스트에 갈 수 있는 Node는 반드시 NodeId의 n번째 비트가 달라야 합니다.)
128 비트의 id가 있는 네트워크에서는, 128개의 다른 거리로 다른 Node들을 식별하게 됩니다. Node가 네트워크에 참가하게 되면, 리스트에 추가됩니다. 이러한 과정은 통해 다른 Node들이 Key를 찾는 것을 돕습니다.
프로토콜 메시지
- PING: Node 작동상태 확인
- Sotre: 한 Node에 pair(KV) 데이터를 저장
- FIND_NODE: 요청한 Key에 제일 가깝게 위치한 k Node들을 반환
- FIND_VALUE: FIND_NODE와 같은 역할을 하며 요청한 Key에 대한 해당 데이터가 있으면 데이터 반환
요청에 의해 반환되는 RPC 메시지는 발신자가 지정한 랜덤한 값을 포함합니다. 랜덤으로 정해진 값은 요청 메시지와 응답 결과를 대응시키기 위해 사용됩니다.
Location Nodes
Node 탐색은 동기적으로 동작합니다. 동시에 일어나는 탐색 요청은 α로 나타내며, 일반적인 α 값은 3입니다. Node은 원하는 Key 값에 가장 가까운 α개의 Node에 FIND_NODE 요청을 전송합니다. FIND_NODE 요청을 받은 Node들은 자신의 k-buckets을 탐색하여 Key 값에 가장 가까운 k개의 Node들을 반환합니다. 탐색 요청자는 요청 결과를 저장하며, k개의 가장 가까운 NodeId를 저장합니다.
탐색 요청자는 저장하고 있는 NodeId들을 선택하여 각 Node들이 위와 같은 요청을 하도록 하는 작업이 반복됩니다. 각 Node들은 자신 주위에 있는 Node들에 가장 잘 알고 있기 때문에 이러한 작업이 반복될 수록 Key 값에 더 가까운 Node를 찾게 됩니다.
탐색 작업은 전 탐색 결과보다 Key에 더 가까운 Node들이 없을때까지 반복됩니다. 탐색이 중지되었을때 저장되어 있는 k Node들이 원하는 Key에 가장 가까운 Node가 됩니다.
Reference
IPFS (InterPlanetary File System) 첫번째
IPFS
IPFS (InterPlanetary File System) 의 영문만 해석을 하면 ‘행성간 파일 시스템’ 입니다. 제목만 보았을때 ‘무슨 이런 황당한’ 이라는 생각이 들었습니다.
일단 주요 링크는 다음과 같습니다.
- IPFS 공식 사이트: https://ipfs.io/
- IPFS 공식 도큐먼트: https://docs.ipfs.io/
- IPFS 논문: https://github.com/ipfs/papers/raw/master/ipfs-cap2pfs/ipfs-p2p-file-system.pdf
- IPFS Demo Youtube: https://youtu.be/8CMxDNuuAiQ
앞으로 수많은 어려움이 있을 듯 싶지만 하나씩 알아보고자 합니다.
IPFS 는 무엇일까?
IPFS 를 최초로 소개한 논문의 Abstract를 살펴보면 다음과 같습니다.
IPFS는 ‘InterPlanetary File System’ 의 약자로 모든 컴퓨팅 장치를 동일한 파일 시스템과 연결하려는 P2P 분산 파일 시스템입니다. 어떤면에서 IPFS는 웹과 비슷하지만 IPFS는 하나의 Git 저장소 내에서 오브젝트를 교환하는 단일 BitTorrent swarm 으로 볼 수 있습니다. 즉, IPFS는 content addressed 하이퍼 링크를 사용하여 높은 처리량의 content addressed 블록 스토리지 모델을 제공합니다. 이는 버전화 된 파일 시스템, 블록 체인 및 심지어 영구 웹을 구축 할 수 있는 데이터 구조인 일반화 된 Merkle DAG 를 형성합니다. IPFS 는 분산 해시 테이블, 인센티브화 된 블록 교환 및 자체 인증 네임 스페이스를 결합합니다. IPFS는 단일 장애 지점 (SOF) 이 없으며 노드는 서로를 신뢰 할 필요가 없습니다.
IPFS 를 최초로 설계한 Juan Benet 은 다음과 같이 이야기 했습니다.
When you have IPFS, you can start looking at everything else in one specific way and you realize that you can replace it all – Juan Benet
나에게는 ‘모든 것을 다르게 보고 모든 것을 바꾸어보자!’ 는 하나의 슬로건 처럼 보였습니다.
IPFS는 파일을 가져 와서 관리하고 버전을 저장하고 버전을 추적 할 수 있는 버전으로 관리하는 파일 시스템입니다. 또한 이러한 파일이 네트워크를 통해 이동하는 방식을 설명하므로 분산 파일 시스템이기도 합니다.
IPFS는 본질적으로 BitTorrent 와 유사한 네트워크에서 데이터와 컨텐트가 어떻게 이동하는지에 대한 규칙을 가지고 있습니다. 이 파일 시스템 계층은 다음과 같은 매우 흥미로운 속성을 제공합니다:
- 완전히 배포 된 웹 사이트
- 원본 서버가없는 웹 사이트
- 클라이언트 측 브라우저에서 완전히 실행할 수있는 웹 사이트
- 대화 할 서버가 없는 웹 사이트
Content Addressing
IPFS는 서버에 저장되는 객체(사진, 기사, 비디오)를 참조하는 대신 파일의 해시를 기준으로 모든 것을 참조합니다. 브라우저에서 특정 페이지에 액세스하려는 경우 IPFS는 전체 네트워크에 “이 해시에 해당하는 파일을 가지고 있습니까?” 라는 질문을 하고 IPFS에 있는 노드는 해당 파일을 반환할 수 있습니다.
IPFS는 HTTP 계층에서 content addressing 을 사용합니다. 위치별로 문제를 해결하는 식별자를 만드는 대신 콘텐츠 자체를 표현하여 문제를 해결하려고 합니다. 즉, 콘텐츠가 주소를 결정합니다. 이 메커니즘은 파일을 가져와서 암호화된 방식으로 해시하여 매우 작고 안전한 파일 표현으로 끝나도록 하는 것입니다. 따라서 다른 사람이 단순히 같은 해시를 가지고 있는 다른 파일을 만들어서 주소로 사용할 수 없습니다. IPFS에있는 파일의 주소는 보통 루트 객체를 식별하는 해시로 시작한 다음 경로를 따라 내려갑니다. 서버 대신에 특정 객체와 통신하고 그 객체 내의 경로를 확인합니다.
HTTP vs. IPFS to find and retrieve a file
HTTP에는 식별자가 위치하기 때문에 파일을 호스팅하고있는 컴퓨터를 쉽게 찾을 수있는 멋진 속성이 있습니다. 이것은 유용하며 일반적으로 잘 작동하지만 오프라인 사례 또는 네트워크에서 로드를 최소화하려는 대규모 분산 시나리오에서는 작동하지 않습니다.
IPFS에서는 단계를 두 부분으로 나눕니다:
- content addressing 을 사용하여 파일 식별
- Go and find it: hash가 생겼을 때 네트워크에 누가 ‘이 콘텐츠를 가지고 있는가? (hash)’ 를 물어 보고 해당 노드에 연결하여 다운로드
그 결과 매우 빠른 라우팅이 가능한 peer-to-peer 오버레이가 생성됩니다.
더 많은 정보는 Alpha Video 를 참조하기 바랍니다.
IPFS by Example
IPFS (InterPlanetary File System)는 DHT, Git 버전 시스템 및 Bittorrent 와 같이 잘 테스트 된 인터넷 기술을 종합 한 것입니다. 그것은 IPFS Object 의 교환을 허용하는 P2P swarm 을 만듭니다. 전체 IPFS Object 는 Merkle DAG 로 알려진 인증 된 데이터 구조를 형성하며 이 데이터 구조는 다른 많은 데이터 구조를 모델링하는 데 사용될 수 있습니다. 이 글에서는 IPFS 개체와 Merkle DAG를 소개하고 IPFS를 사용하여 모델링 할 수있는 구조의 예를 제시합니다.
IPFS Objects
IPFS는 기본적으로 IPFS Object 를 검색하고 공유하기 위한 P2P 시스템입니다. IPFS Object 는 두 개의 필드가있는 데이터 구조입니다.
- Data: 크기가 256 kB 미만인 비정형 바이너리 데이터
- Links: Link 구조체의 배열. 다른 IPFS Object 에 대한 링크
링크 구조에는 세 개의 데이터 필드가 있습니다:
- Name: 링크의 이름
- Hash: 링크된 IPFS Object 의 해시
- Size: 링크 다음의 링크를 포함한 연결된 IPFS Object 의 누적 크기
Size 필드는 P2P 네트워킹을 최적화하는 데 주로 사용되며 개념적으로 논리적 구조에는 필요하지 않기 때문에 대부분 여기에서 무시합니다.
IPFS Object 는 일반적으로 Base58 로 인코딩 된 해시로 참조됩니다. 예를 들어 IPFS CLI Tool 을 사용하여 해시 QmarHSr9aaSNaPSR6KFPbuLV9aqJfTk1y9Bpdwline 에서 IPFS Object 를 살펴보면 다음과 같습니다.
$ ipfs object get QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq
{"Links": [{
"Name": "AnotherName",
"Hash": "QmVtYjNij3KeyGmcgg7yVXWskLaBtov3UYL9pgcGK3MCWu",
"Size": 18},
{"Name": "SomeName",
"Hash": "QmbUSy8HCn8J4TMDRRdxCbK2uCCtkQyZtY6XYv3y7kLgDC",
"Size": 58}],
"Data": "Hello World!"}
모든 해시가 “Qm”으로 시작한다는 것을 알 수 있습니다. 그 이유는 해시가 실제로 multihash (다중 해시) 이기 때문입니다. 해시 자체가 다중 해시의 처음 2 바이트에서 해시 함수와 길이를 지정하기 때문입니다. 위의 예에서 16 진수의 처음 2 바이트는 1220이며, 여기서 12는 SHA256 해시 함수이고 20은 바이트 단위의 해시 길이를 나타냅니다 (32 바이트).
데이터와 명명 된 링크는 IPFS Object 의 컬렉션에 Merkle DAG 의 구조를 제공합니다. DAG 는 Directed Acyclic Graph 를 의미하고 Merkle 은 암호화 해시를 사용하여 콘텐츠를 처리하는 암호로 인증 된 데이터 구조임을 나타냅니다.
그래프 구조를 시각화하기 위해 노드의 데이터와 링크가 그래프 에지를 다른 IPFS Object 로 향하게하는 그래프로 IPFS Object 를 시각화합니다. 여기서 링크 이름은 그래프 에지의 레이블입니다. 위의 예는 다음과 같이 시각화됩니다.
IPFS Object 로 나타낼 수 있는 다양한 데이터 구조의 예는 다음과 같습니다.
File Systems
IPFS는 파일과 디렉토리로 구성된 파일 시스템을 쉽게 나타낼 수 있습니다.
Small Files
작은 파일 (<256 kB)은 데이터가 파일 내용 (작은 머리글과 바닥 글 포함)이고 링크가없는 IPFS Object 로 표시됩니다. 즉, 링크 배열이 비어 있습니다. 파일 이름은 IPFS 개체의 일부가 아니므로 이름이 다른 파일과 내용이 동일한 두 파일의 IPFS 개체 표시는 동일하므로 해시가 동일합니다.
ipfs add 명령을 사용하여 IPFS에 작은 파일을 추가 할 수 있습니다:
user@user-VBox:~/tmp$ ipfs add test_dir/hello.txt
added QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG test_dir/hello.txt
ipfs cat 명령을 사용하여 위의 IPFS Object 의 파일 내용을 볼 수 있습니다.
user@user-VBox:~/tmp$ ipfs cat QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
Hello World!
ipfs object get 명령을 사용하여 기본 구조를 볼 수 있습니다.
user@user-VBox:~/tmp$ ipfs object get QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
{"Links": [],
"Data": "\u0008\u0002\u0012\rHello World!\n\u0018\r"}
이 파일을 다음과 같이 시각화합니다:

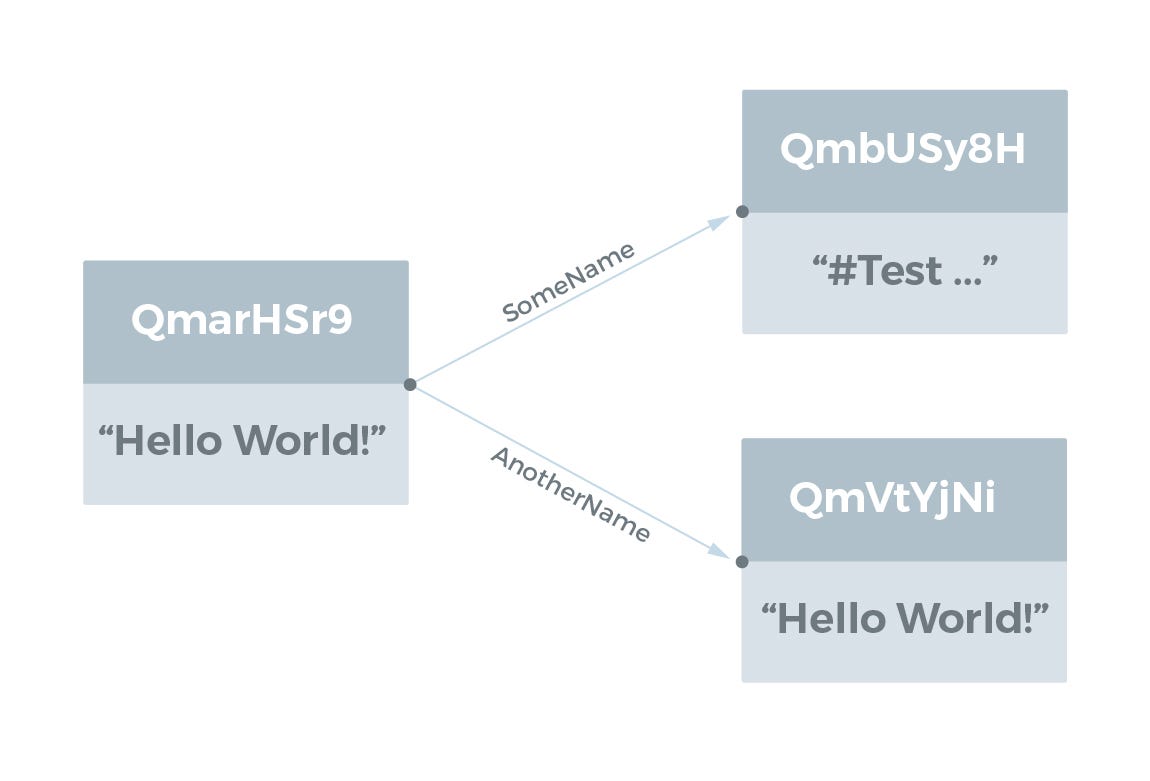
Large Files
큰 파일 (> 256 kB)은 <256 kB 인 파일 청크에 대한 링크 목록으로 표시되며이 Object 는 큰 파일을 나타내는 최소 데이터만 표시됩니다. 파일 청크에 대한 링크는 빈 문자열을 이름으로 갖습니다.
user@user-VBox:~/tmp$ ipfs add test_dir/bigfile.js
added QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w test_dir/bigfile.js
user@user-VBox:~/tmp$ ipfs object get QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w
{"Links": [{
"Name": "",
"Hash": "QmYSK2JyM3RyDyB52caZCTKFR3HKniEcMnNJYdk8DQ6KKB",
"Size": 262158},
{"Name": "",
"Hash": "QmQeUqdjFmaxuJewStqCLUoKrR9khqb4Edw9TfRQQdfWz3",
"Size": 262158},
{"Name": "",
"Hash": "Qma98bk1hjiRZDTmYmfiUXDj8hXXt7uGA5roU5mfUb3sVG",
"Size": 178947}],
"Data": "\u0008\u0002\u0018* \u0010 \u0010 \n"}
Directory Structures
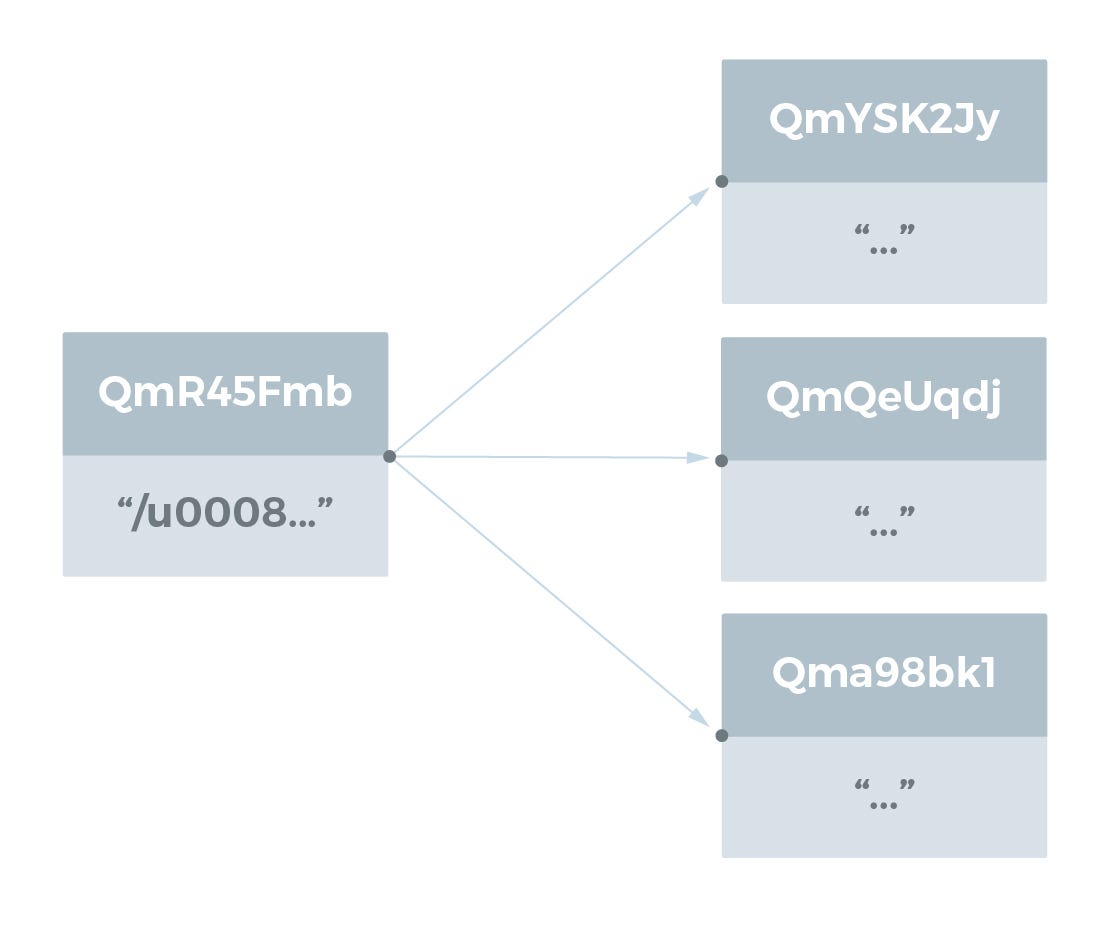
디렉토리는 파일 또는 다른 디렉토리를 나타내는 IPFS Object 에 대한 링크 목록으로 나타냅니다. 링크의 이름은 파일과 디렉토리의 이름입니다. 예를 들어, test_dir 디렉토리의 다음 디렉토리 구조를 참고하기 바랍니다.
user@user-VBox:~/tmp$ ls -R test_dir
test_dir:
bigfile.js hello.txt my_dir
test_dir/my_dir:
my_file.txt testing.txt
hello.txt 및 my_file.txt 파일에는 모두 Hello World!\n 라는 문자열이 있습니다. testing.txt 파일에는 Testing 123\n 문자열이 있습니다.
이 디렉토리 구조를 IPFS Object 로 나타낼 때 다음과 같이 보입니다:
Hello World!\n 파일을 포함하는 파일의 자동 중복 제거에 유의하십시오. 이 파일의 데이터는 IPFS의 한 논리적 위치(해시에 의해 추가됨)에만 저장됩니다.
IPFS command-line tool 은 디렉토리 링크 이름을 따라 파일 시스템을 탐색 할 수 있습니다.
user@user-VBox:~/tmp$ ipfs cat Qma3qbWDGJc6he3syLUTaRkJD3vAq1k5569tNMbUtjAZjf/my_dir/my_file.txt
Hello World!
Versioned File Systems
IPFS는 버전화된 파일 시스템을 허용하기 위해 Git 에서 사용하는 데이터 구조를 나타낼 수 있습니다. Git 커밋 Object 는 Git Book에 설명되어있으니 참조하기 바랍니다. IPFS 커밋 Object 의 구조는 완전히 지정되지 않았으며 지금까지도 토론이 진행 중입니다.
Commit Object 의 주요 속성은 이전 커밋을 가리키는 parent0, parent1 등의 이름을 가진 하나 이상의 링크와 해당 커밋에서 참조하는 파일 시스템 구조를 가리키는 name Object (Git 에서 tree) 가 있는 하나 이상의 링크를 포함한다는 것입니다.
다음과 같은 두 가지 커밋과 함께 이전 파일 시스템 디렉토리 구조를 예제로 제공합니다. 첫 번째 커밋은 원래 구조이고 두 번째 커밋에서는 my_file.txt 파일을 본래 Hello World! 대신 Another World! 로 업데이트합니다.
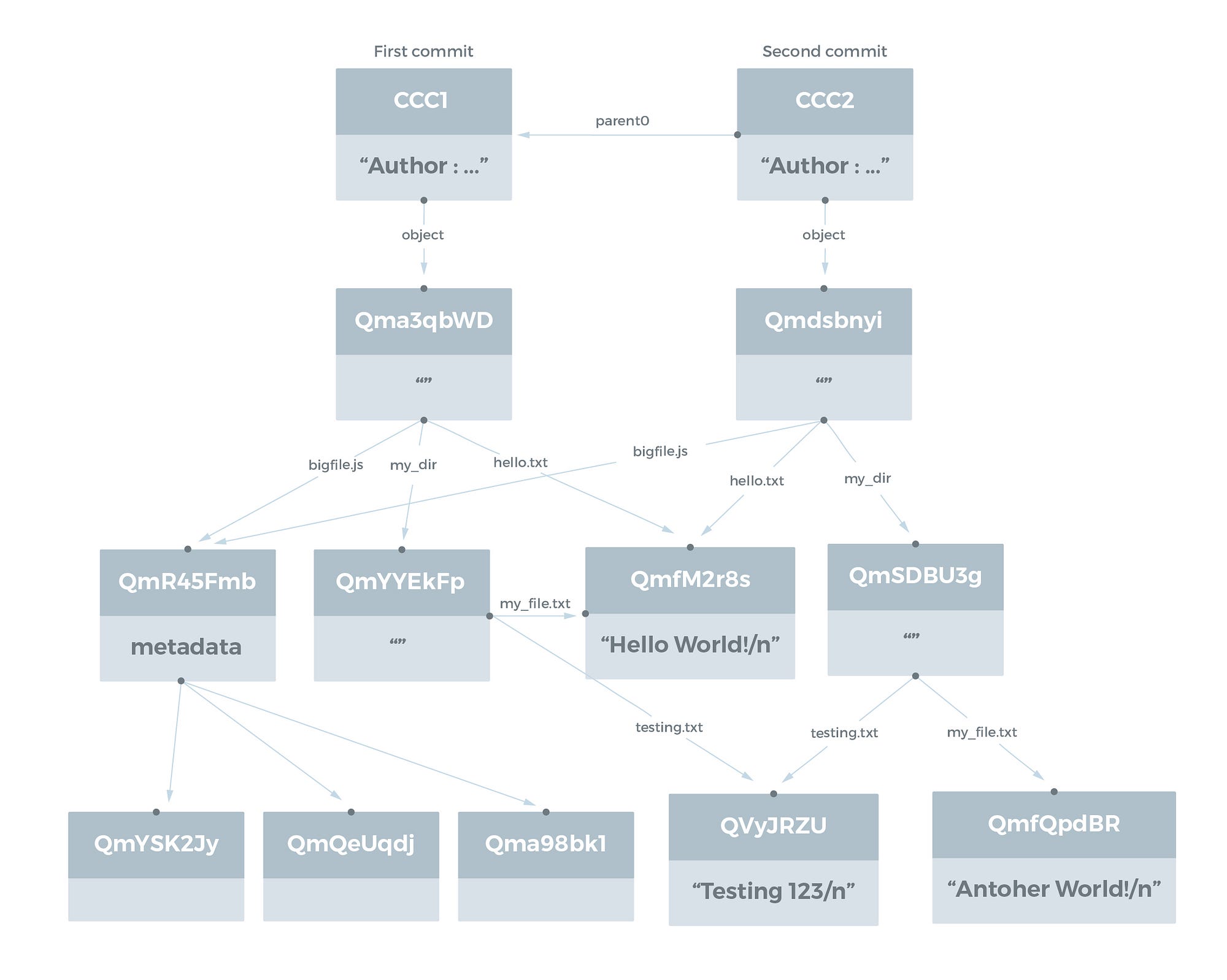
자동 중복 제거가 있으므로 두 번째 커밋의 새 Object 는 기본 디렉토리이고 새 디렉토리는 my_dir 이며 업데이트 된 파일은 my_file.txt 입니다.
Blockchains
이것은 IPFS의 가장 흥미로운 사용 사례 중 하나입니다. 블록체인은 자연스러운 DAG 구조를 가지고 있습니다. 과거 블록은 항상 이후의 블록과 해시로 연결됩니다. Ethereum 블록체인과 같은 고급 블록체인에는 IPFS Object 를 사용하여 에뮬레이트 할 수 있는 Merkle-Patricia 트리 구조가 있는 연결된 state 데이터베이스도 있습니다.
각 블록에 다음 데이터가 포함된 블록체인의 단순화된 모델을 가정해 봅시다.
- 트랜잭션 Object 리스트
- 이전 블록에 대한 링크
- state (상태) tree 및 데이터베이스의 해시
블록체인은 다음과 같이 IPFS 에서 모델링 될 수 있습니다.
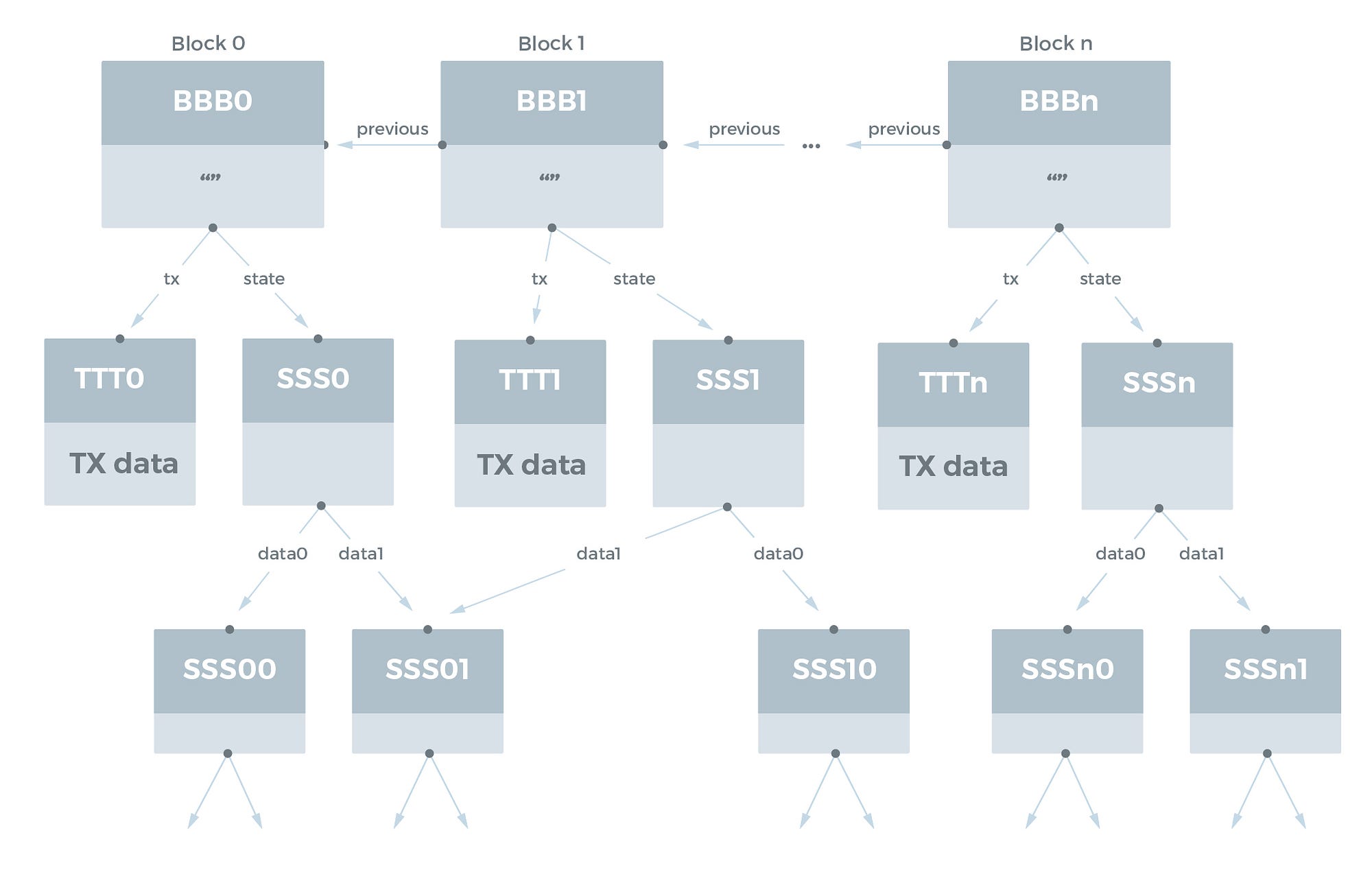
상태 데이터베이스를 IPFS 에 넣을 때 중복 제거가 발생합니다. 두 블록 사이에 변경된 상태 항목만 명시적으로 저장해야 합니다.
여기서 흥미로운 점은 블록체인에 데이터를 저장하는 것과 블록체인에 데이터의 해시를 저장하는 것 사이의 차이입니다. Ethereum 플랫폼에서는 주 데이터베이스의 중복을 최소화하기 위해 관련 상태 데이터베이스 (“blockchain bloat”) 에 데이터를 저장하는 데 상당한 비용을 지불해야 합니다. 따라서 데이터 자체가 아니라 상태 데이터베이스에서 데이터의 IPFS 해시를 저장하는 것이 일반적인 설계 패턴입니다.
연관된 상태 데이터베이스와 블록체인이 이미 IPFS에 표시되어 있는 경우, 모든 것이 IPFS에만 저장되므로 블록체인에 해시를 저장하고 블록체인에 데이터를 저장하는 것 사이의 구분이 다소 모호해집니다. 이 경우 IPFS 링크를 블록체인에 저장한 경우, 마치 데이터가 블록체인에 저장된 것처럼 이 링크를 따라 데이터에 액세스할 수 있습니다.
그러나 온체인과 오프체인 데이터 스토리지를 구분할 수 있습니다. 새로운 블록을 만들 때 마이너가 처리해야하는 것을 살펴봄으로써 이를 수행합니다. 현재 Ethereum 네트워크에서 마이너는 상태 데이터베이스를 업데이트 할 트랜잭션을 처리해야 합니다. 이렇게 하려면 전체 상태 데이터베이스에 액세스 하여야 변경된 곳마다 데이터베이스를 업데이트 할 수 있습니다.
따라서 IPFS로 표현 된 블록 체인 상태 데이터베이스에서 “온체인”또는 “오프체인”으로 데이터에 태그를 지정해야 합니다. 마이너가 마이닝을 위해 국부적으로 유지하기 위해서는 “온체인” 데이터가 필요하며 이 데이터는 거래의 직접적인 영향을받습니다. “오프체인” 데이터는 사용자가 업데이트 해야하며 마이너가 접촉 할 필요가 없습니다.
IPFS 를 지탱하는 기반 기술
IPFS 에서는 Kademlia DHT 와 BitTorrent 그리고 Git, Self-certifying File System 에 대한 이해를 필요로 합니다.
앞으로 차근차근 이에대한 이야기를 하도록 하겠습니다.
IPFS 그리고 Web
Internet 그리고 Web
위키피디아를 통해 찾아본 인터넷과 웹의 정의는 아래와 같습니다.
인터넷 은 컴퓨터로 연결하여 TCI/IP (Transmission Control Protocol/Inrternet Protocol) 통신 프로토콜을 이용해 정보를 주고받는 컴퓨터 네트워크 입니다.
World Wide Web 은 인터넷에 연결된 컴퓨터들을 통해 사람들이 정보를 공유할 수 있는 전 세계적인 정보 공간을 말합니다. 이를 간단히 웹 (Web) 이라고 부르는 경우가 많습니다. 이 용어는 인터넷과 동의어로 쓰이는 경우가 많으나 엄격히 말해 서로 다른 개념입니다. 웹은 전자메일과 같이 인터넷 상에서 동작하는 하나의 서비스 입니다.
그런데 우리가 가장 많이 사용하는 웹 프로토콜은 무엇일까요? 아마도 HTTP (HyperText Transfer Protocol) 가 아닐까 합니다.
HTTP 는 WWW 상에서 정보를 주고받을 수 있는 프로토콜 입니다. TCP 와 UDP 를 사용하고 80번 포트를 사용합니다. 결국 클라이언트와 서버 사이에 이루어지는 요청/응답(request/response) 프로토콜 입니다.
인터넷, 웹, HTTP, TCP/UDP 등등의 수많은 의미와 기술들은 요청한 파일을 전송하는 목적을 가지고 있습니다.
HTTP Web 의 한계
불안정
HTTP는 클라이언트가 서버에 데이터를 요청하면 서버에서 응답하며 데이터를 보내주는 구조입니다. 그렇기 때문에 서버의 전원이 차단되면 아무것도 할 수 없고 항상 서버 해킹에 대한 걱정을 안고 있어야 합니다. 특히나 해킹으로 인하여 서버의 데이터가 삭제된다면 무척이나 큰 일이 발생합니다.
자주 웹서핑을 하다가 분노를 일으키는 ‘404 Error’ 는 컨텐츠가 삭제되거나 이동하였음을 의미합니다.
가장 심각한 문제는 어떤 이유로든 데이터가 삭제되는 것 입니다. 이러한 문제를 줄이기 위해 이중화, 삼중화로 서버를 구성하고 네트워크보안을 추가하는 등 어마어마한 시간과 노력을 들이고 있지만 해결이 되지 않습니다.
중앙 집중화
인터넷을 기반으로 하는 시스템의 구성은 분산 시스템이지만 역설적이게도 매우 중앙 집중화되어 있습니다. 이는 결국 현재의 문제점을 낳고 말았습니다. 해커는 중앙 집중화된 몇개의 서버를 공격하여 개인정보를 탈취하고, 몇개의 서버를 장악하면 하나의 나라를 감시할 수 있습니다. 즉 중앙 집중화된 구조는 보안에 취약해질 수 밖에 없는 구조입니다.
Latency
지리적으로 가까운 서버에서 데이터를 제공하지 않는다면 속도 문제가 발생합니다. 특히나 지리적으로 너무 멀리 떨어진 서버라면 상상을 초월하는 속도 문제를 경험하게 됩니다. 대부분의 서비스 업체들은 리전이라고 하는 데이터센터를 세계 권역마다 마련하고 있습니다.

최근 매우 인기가 있는 Youtube 를 생각하면 인기 콘텐츠에 대한 요청이 어마어마하게 발생하고 있으며 이에 대한 응답 역시 어마어마하게 발생하고 있습니다. 작은 용량의 데이터가 전송되던 과거의 형태에서 매우 급격하게 증가한 데이터가 전송되고 있습니다. 스트리밍 서비스 영상이 고화질로 증가하면서 용량도 폭증하였습니다. 이는 결국 통신 속도의 저하를 초래하게 됩니다.
해결책은 데이터 분산
비교적 작은 데이터들이 돌아다녔던 과거의 HTTP 환경에서 이제는 매우 큰 데이터들이 어마어마한 트래픽을 발생시키는 환경으로 변화하였습니다. 하지만 아직도 HTTP를 가장 많이 활용하고 있습니다. 새로운 도전거리가 발생한 것 입니다. 즉, 네트워크도 진화하고 변화하여야 합니다.
대략의 진화 방향을 살펴보면 다음과 같습니다.
- 페타 바이트 데이터셋이 호스팅되고 분산됩니다.
- 조직 전체에 걸쳐 대규모 데이터를 기반으로 컴퓨팅 합니다.
- 대규모 데이터셋은 버전처리되어 관리 되고 연결됩니다.
- 중요한 파일이 실수로 사라지는 것을 방지합니다.
앞으로 이러한 변화의 선두에 서있는 IPFS (InterPlanetary File System) 에 대하여 알아보고자 합니다.
