IPFS (InterPlanetary File System) 첫번째
IPFS
IPFS (InterPlanetary File System) 의 영문만 해석을 하면 ‘행성간 파일 시스템’ 입니다. 제목만 보았을때 ‘무슨 이런 황당한’ 이라는 생각이 들었습니다.
일단 주요 링크는 다음과 같습니다.
- IPFS 공식 사이트: https://ipfs.io/
- IPFS 공식 도큐먼트: https://docs.ipfs.io/
- IPFS 논문: https://github.com/ipfs/papers/raw/master/ipfs-cap2pfs/ipfs-p2p-file-system.pdf
- IPFS Demo Youtube: https://youtu.be/8CMxDNuuAiQ
앞으로 수많은 어려움이 있을 듯 싶지만 하나씩 알아보고자 합니다.
IPFS 는 무엇일까?
IPFS 를 최초로 소개한 논문의 Abstract를 살펴보면 다음과 같습니다.
IPFS는 ‘InterPlanetary File System’ 의 약자로 모든 컴퓨팅 장치를 동일한 파일 시스템과 연결하려는 P2P 분산 파일 시스템입니다. 어떤면에서 IPFS는 웹과 비슷하지만 IPFS는 하나의 Git 저장소 내에서 오브젝트를 교환하는 단일 BitTorrent swarm 으로 볼 수 있습니다. 즉, IPFS는 content addressed 하이퍼 링크를 사용하여 높은 처리량의 content addressed 블록 스토리지 모델을 제공합니다. 이는 버전화 된 파일 시스템, 블록 체인 및 심지어 영구 웹을 구축 할 수 있는 데이터 구조인 일반화 된 Merkle DAG 를 형성합니다. IPFS 는 분산 해시 테이블, 인센티브화 된 블록 교환 및 자체 인증 네임 스페이스를 결합합니다. IPFS는 단일 장애 지점 (SOF) 이 없으며 노드는 서로를 신뢰 할 필요가 없습니다.
IPFS 를 최초로 설계한 Juan Benet 은 다음과 같이 이야기 했습니다.
When you have IPFS, you can start looking at everything else in one specific way and you realize that you can replace it all – Juan Benet
나에게는 ‘모든 것을 다르게 보고 모든 것을 바꾸어보자!’ 는 하나의 슬로건 처럼 보였습니다.
IPFS는 파일을 가져 와서 관리하고 버전을 저장하고 버전을 추적 할 수 있는 버전으로 관리하는 파일 시스템입니다. 또한 이러한 파일이 네트워크를 통해 이동하는 방식을 설명하므로 분산 파일 시스템이기도 합니다.
IPFS는 본질적으로 BitTorrent 와 유사한 네트워크에서 데이터와 컨텐트가 어떻게 이동하는지에 대한 규칙을 가지고 있습니다. 이 파일 시스템 계층은 다음과 같은 매우 흥미로운 속성을 제공합니다:
- 완전히 배포 된 웹 사이트
- 원본 서버가없는 웹 사이트
- 클라이언트 측 브라우저에서 완전히 실행할 수있는 웹 사이트
- 대화 할 서버가 없는 웹 사이트
Content Addressing
IPFS는 서버에 저장되는 객체(사진, 기사, 비디오)를 참조하는 대신 파일의 해시를 기준으로 모든 것을 참조합니다. 브라우저에서 특정 페이지에 액세스하려는 경우 IPFS는 전체 네트워크에 “이 해시에 해당하는 파일을 가지고 있습니까?” 라는 질문을 하고 IPFS에 있는 노드는 해당 파일을 반환할 수 있습니다.
IPFS는 HTTP 계층에서 content addressing 을 사용합니다. 위치별로 문제를 해결하는 식별자를 만드는 대신 콘텐츠 자체를 표현하여 문제를 해결하려고 합니다. 즉, 콘텐츠가 주소를 결정합니다. 이 메커니즘은 파일을 가져와서 암호화된 방식으로 해시하여 매우 작고 안전한 파일 표현으로 끝나도록 하는 것입니다. 따라서 다른 사람이 단순히 같은 해시를 가지고 있는 다른 파일을 만들어서 주소로 사용할 수 없습니다. IPFS에있는 파일의 주소는 보통 루트 객체를 식별하는 해시로 시작한 다음 경로를 따라 내려갑니다. 서버 대신에 특정 객체와 통신하고 그 객체 내의 경로를 확인합니다.
HTTP vs. IPFS to find and retrieve a file
HTTP에는 식별자가 위치하기 때문에 파일을 호스팅하고있는 컴퓨터를 쉽게 찾을 수있는 멋진 속성이 있습니다. 이것은 유용하며 일반적으로 잘 작동하지만 오프라인 사례 또는 네트워크에서 로드를 최소화하려는 대규모 분산 시나리오에서는 작동하지 않습니다.
IPFS에서는 단계를 두 부분으로 나눕니다:
- content addressing 을 사용하여 파일 식별
- Go and find it: hash가 생겼을 때 네트워크에 누가 ‘이 콘텐츠를 가지고 있는가? (hash)’ 를 물어 보고 해당 노드에 연결하여 다운로드
그 결과 매우 빠른 라우팅이 가능한 peer-to-peer 오버레이가 생성됩니다.
더 많은 정보는 Alpha Video 를 참조하기 바랍니다.
IPFS by Example
IPFS (InterPlanetary File System)는 DHT, Git 버전 시스템 및 Bittorrent 와 같이 잘 테스트 된 인터넷 기술을 종합 한 것입니다. 그것은 IPFS Object 의 교환을 허용하는 P2P swarm 을 만듭니다. 전체 IPFS Object 는 Merkle DAG 로 알려진 인증 된 데이터 구조를 형성하며 이 데이터 구조는 다른 많은 데이터 구조를 모델링하는 데 사용될 수 있습니다. 이 글에서는 IPFS 개체와 Merkle DAG를 소개하고 IPFS를 사용하여 모델링 할 수있는 구조의 예를 제시합니다.
IPFS Objects
IPFS는 기본적으로 IPFS Object 를 검색하고 공유하기 위한 P2P 시스템입니다. IPFS Object 는 두 개의 필드가있는 데이터 구조입니다.
- Data: 크기가 256 kB 미만인 비정형 바이너리 데이터
- Links: Link 구조체의 배열. 다른 IPFS Object 에 대한 링크
링크 구조에는 세 개의 데이터 필드가 있습니다:
- Name: 링크의 이름
- Hash: 링크된 IPFS Object 의 해시
- Size: 링크 다음의 링크를 포함한 연결된 IPFS Object 의 누적 크기
Size 필드는 P2P 네트워킹을 최적화하는 데 주로 사용되며 개념적으로 논리적 구조에는 필요하지 않기 때문에 대부분 여기에서 무시합니다.
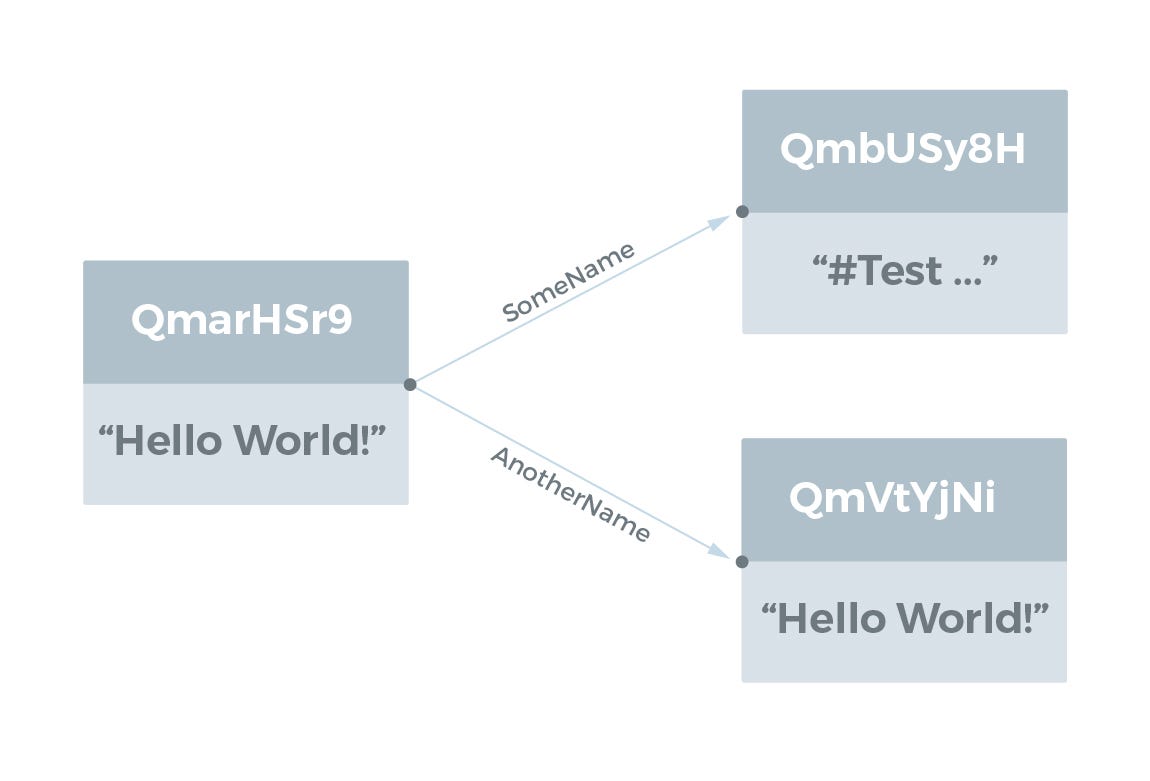
IPFS Object 는 일반적으로 Base58 로 인코딩 된 해시로 참조됩니다. 예를 들어 IPFS CLI Tool 을 사용하여 해시 QmarHSr9aaSNaPSR6KFPbuLV9aqJfTk1y9Bpdwline 에서 IPFS Object 를 살펴보면 다음과 같습니다.
$ ipfs object get QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq
{"Links": [{
"Name": "AnotherName",
"Hash": "QmVtYjNij3KeyGmcgg7yVXWskLaBtov3UYL9pgcGK3MCWu",
"Size": 18},
{"Name": "SomeName",
"Hash": "QmbUSy8HCn8J4TMDRRdxCbK2uCCtkQyZtY6XYv3y7kLgDC",
"Size": 58}],
"Data": "Hello World!"}
모든 해시가 “Qm”으로 시작한다는 것을 알 수 있습니다. 그 이유는 해시가 실제로 multihash (다중 해시) 이기 때문입니다. 해시 자체가 다중 해시의 처음 2 바이트에서 해시 함수와 길이를 지정하기 때문입니다. 위의 예에서 16 진수의 처음 2 바이트는 1220이며, 여기서 12는 SHA256 해시 함수이고 20은 바이트 단위의 해시 길이를 나타냅니다 (32 바이트).
데이터와 명명 된 링크는 IPFS Object 의 컬렉션에 Merkle DAG 의 구조를 제공합니다. DAG 는 Directed Acyclic Graph 를 의미하고 Merkle 은 암호화 해시를 사용하여 콘텐츠를 처리하는 암호로 인증 된 데이터 구조임을 나타냅니다.
그래프 구조를 시각화하기 위해 노드의 데이터와 링크가 그래프 에지를 다른 IPFS Object 로 향하게하는 그래프로 IPFS Object 를 시각화합니다. 여기서 링크 이름은 그래프 에지의 레이블입니다. 위의 예는 다음과 같이 시각화됩니다.
IPFS Object 로 나타낼 수 있는 다양한 데이터 구조의 예는 다음과 같습니다.
File Systems
IPFS는 파일과 디렉토리로 구성된 파일 시스템을 쉽게 나타낼 수 있습니다.
Small Files
작은 파일 (<256 kB)은 데이터가 파일 내용 (작은 머리글과 바닥 글 포함)이고 링크가없는 IPFS Object 로 표시됩니다. 즉, 링크 배열이 비어 있습니다. 파일 이름은 IPFS 개체의 일부가 아니므로 이름이 다른 파일과 내용이 동일한 두 파일의 IPFS 개체 표시는 동일하므로 해시가 동일합니다.
ipfs add 명령을 사용하여 IPFS에 작은 파일을 추가 할 수 있습니다:
user@user-VBox:~/tmp$ ipfs add test_dir/hello.txt
added QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG test_dir/hello.txt
ipfs cat 명령을 사용하여 위의 IPFS Object 의 파일 내용을 볼 수 있습니다.
user@user-VBox:~/tmp$ ipfs cat QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
Hello World!
ipfs object get 명령을 사용하여 기본 구조를 볼 수 있습니다.
user@user-VBox:~/tmp$ ipfs object get QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
{"Links": [],
"Data": "\u0008\u0002\u0012\rHello World!\n\u0018\r"}
이 파일을 다음과 같이 시각화합니다:

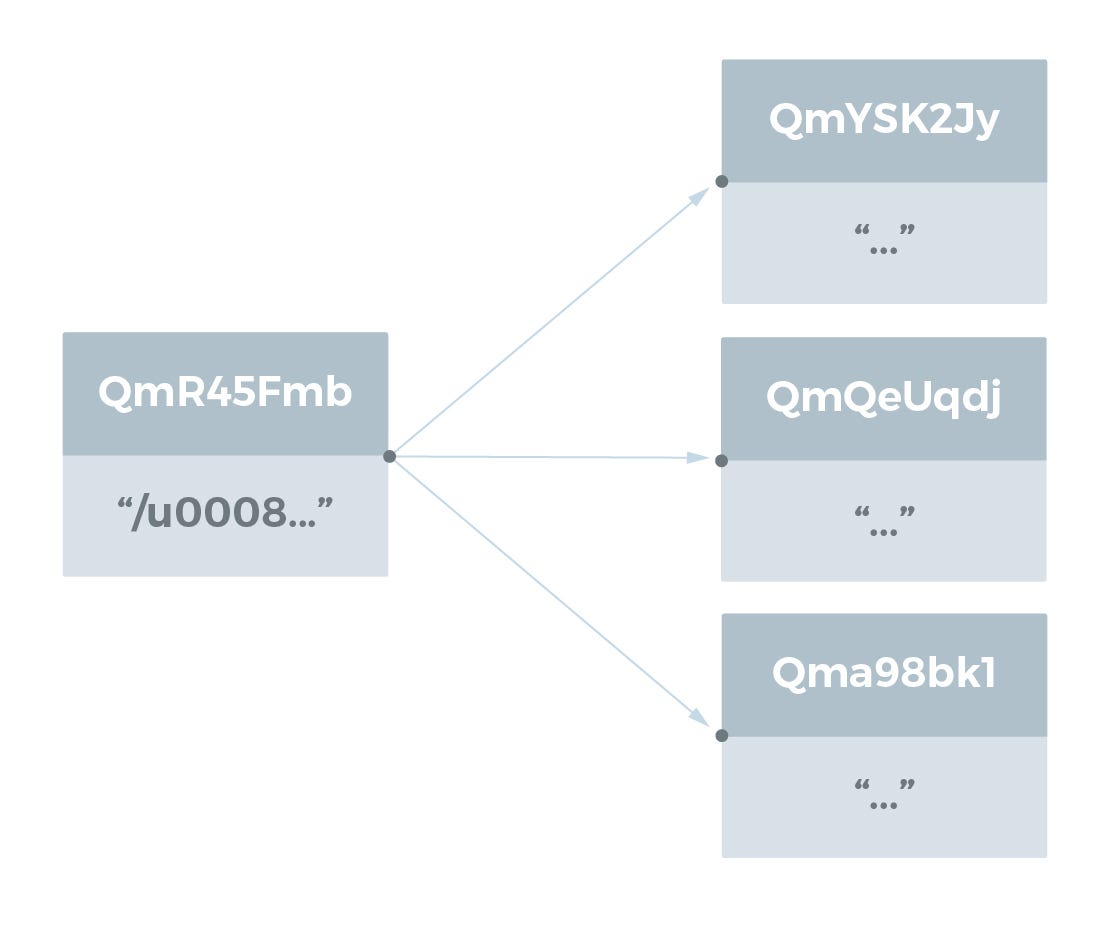
Large Files
큰 파일 (> 256 kB)은 <256 kB 인 파일 청크에 대한 링크 목록으로 표시되며이 Object 는 큰 파일을 나타내는 최소 데이터만 표시됩니다. 파일 청크에 대한 링크는 빈 문자열을 이름으로 갖습니다.
user@user-VBox:~/tmp$ ipfs add test_dir/bigfile.js
added QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w test_dir/bigfile.js
user@user-VBox:~/tmp$ ipfs object get QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w
{"Links": [{
"Name": "",
"Hash": "QmYSK2JyM3RyDyB52caZCTKFR3HKniEcMnNJYdk8DQ6KKB",
"Size": 262158},
{"Name": "",
"Hash": "QmQeUqdjFmaxuJewStqCLUoKrR9khqb4Edw9TfRQQdfWz3",
"Size": 262158},
{"Name": "",
"Hash": "Qma98bk1hjiRZDTmYmfiUXDj8hXXt7uGA5roU5mfUb3sVG",
"Size": 178947}],
"Data": "\u0008\u0002\u0018* \u0010 \u0010 \n"}
Directory Structures
디렉토리는 파일 또는 다른 디렉토리를 나타내는 IPFS Object 에 대한 링크 목록으로 나타냅니다. 링크의 이름은 파일과 디렉토리의 이름입니다. 예를 들어, test_dir 디렉토리의 다음 디렉토리 구조를 참고하기 바랍니다.
user@user-VBox:~/tmp$ ls -R test_dir
test_dir:
bigfile.js hello.txt my_dir
test_dir/my_dir:
my_file.txt testing.txt
hello.txt 및 my_file.txt 파일에는 모두 Hello World!\n 라는 문자열이 있습니다. testing.txt 파일에는 Testing 123\n 문자열이 있습니다.
이 디렉토리 구조를 IPFS Object 로 나타낼 때 다음과 같이 보입니다:
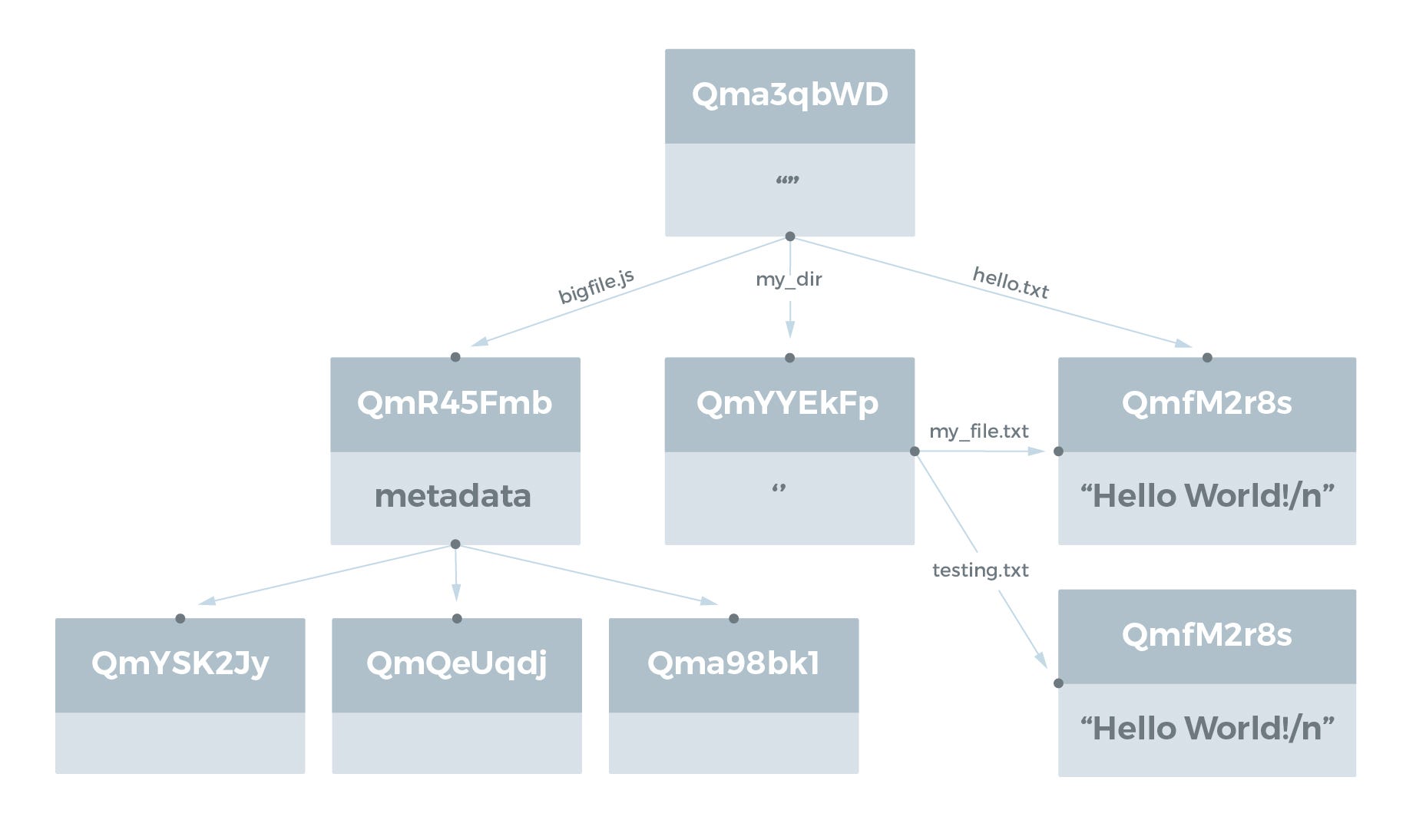
Hello World!\n 파일을 포함하는 파일의 자동 중복 제거에 유의하십시오. 이 파일의 데이터는 IPFS의 한 논리적 위치(해시에 의해 추가됨)에만 저장됩니다.
IPFS command-line tool 은 디렉토리 링크 이름을 따라 파일 시스템을 탐색 할 수 있습니다.
user@user-VBox:~/tmp$ ipfs cat Qma3qbWDGJc6he3syLUTaRkJD3vAq1k5569tNMbUtjAZjf/my_dir/my_file.txt
Hello World!
Versioned File Systems
IPFS는 버전화된 파일 시스템을 허용하기 위해 Git 에서 사용하는 데이터 구조를 나타낼 수 있습니다. Git 커밋 Object 는 Git Book에 설명되어있으니 참조하기 바랍니다. IPFS 커밋 Object 의 구조는 완전히 지정되지 않았으며 지금까지도 토론이 진행 중입니다.
Commit Object 의 주요 속성은 이전 커밋을 가리키는 parent0, parent1 등의 이름을 가진 하나 이상의 링크와 해당 커밋에서 참조하는 파일 시스템 구조를 가리키는 name Object (Git 에서 tree) 가 있는 하나 이상의 링크를 포함한다는 것입니다.
다음과 같은 두 가지 커밋과 함께 이전 파일 시스템 디렉토리 구조를 예제로 제공합니다. 첫 번째 커밋은 원래 구조이고 두 번째 커밋에서는 my_file.txt 파일을 본래 Hello World! 대신 Another World! 로 업데이트합니다.
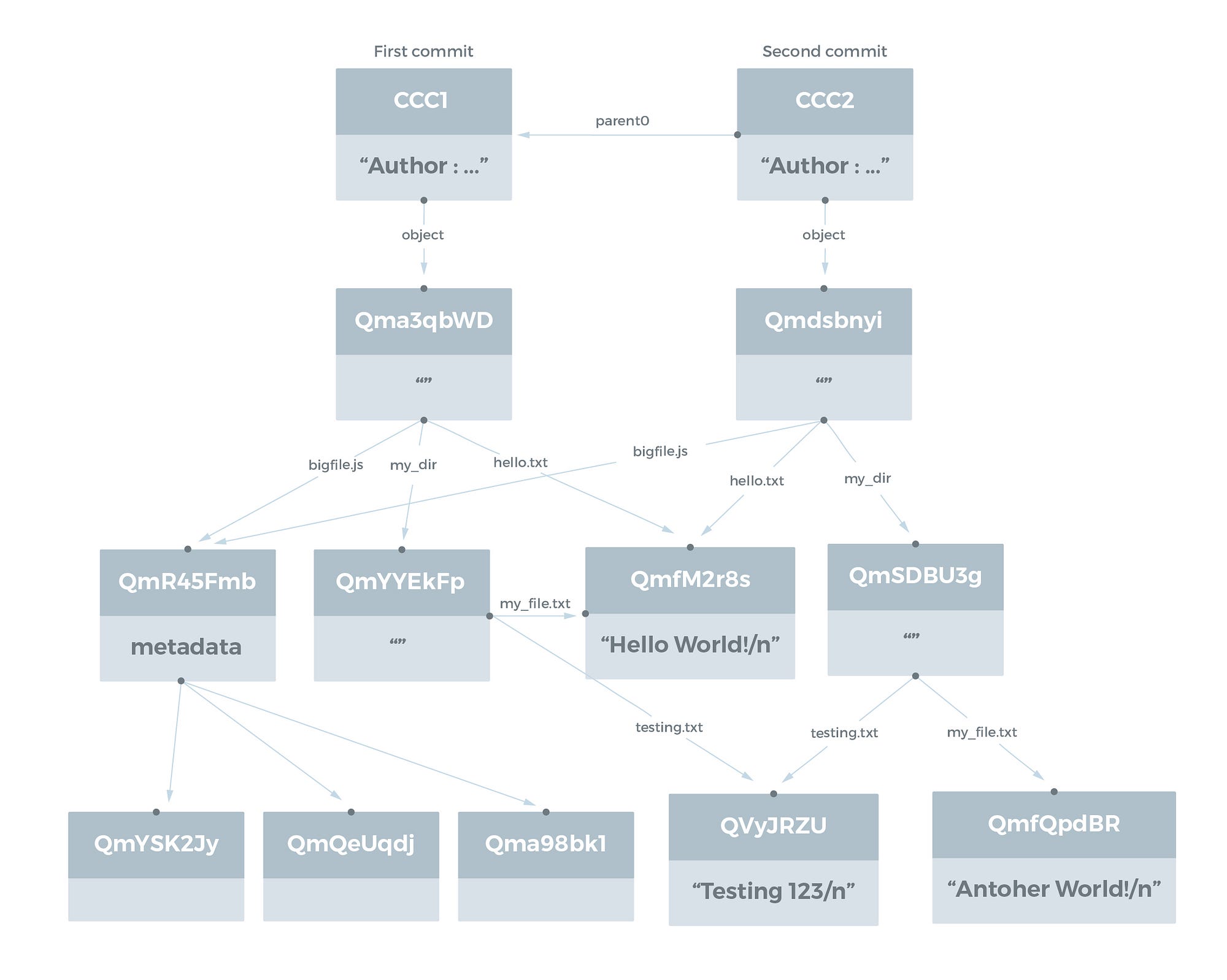
자동 중복 제거가 있으므로 두 번째 커밋의 새 Object 는 기본 디렉토리이고 새 디렉토리는 my_dir 이며 업데이트 된 파일은 my_file.txt 입니다.
Blockchains
이것은 IPFS의 가장 흥미로운 사용 사례 중 하나입니다. 블록체인은 자연스러운 DAG 구조를 가지고 있습니다. 과거 블록은 항상 이후의 블록과 해시로 연결됩니다. Ethereum 블록체인과 같은 고급 블록체인에는 IPFS Object 를 사용하여 에뮬레이트 할 수 있는 Merkle-Patricia 트리 구조가 있는 연결된 state 데이터베이스도 있습니다.
각 블록에 다음 데이터가 포함된 블록체인의 단순화된 모델을 가정해 봅시다.
- 트랜잭션 Object 리스트
- 이전 블록에 대한 링크
- state (상태) tree 및 데이터베이스의 해시
블록체인은 다음과 같이 IPFS 에서 모델링 될 수 있습니다.
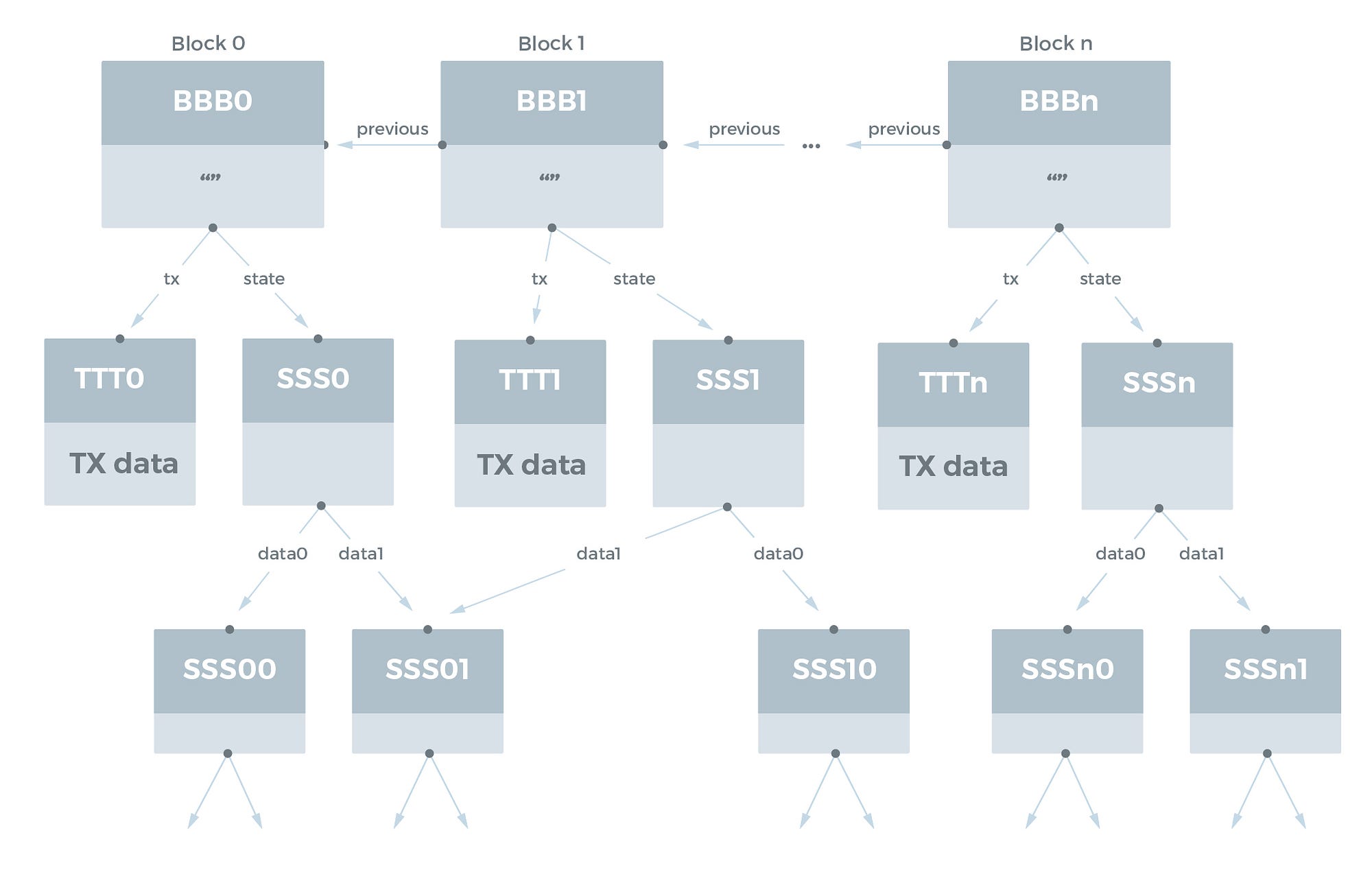
상태 데이터베이스를 IPFS 에 넣을 때 중복 제거가 발생합니다. 두 블록 사이에 변경된 상태 항목만 명시적으로 저장해야 합니다.
여기서 흥미로운 점은 블록체인에 데이터를 저장하는 것과 블록체인에 데이터의 해시를 저장하는 것 사이의 차이입니다. Ethereum 플랫폼에서는 주 데이터베이스의 중복을 최소화하기 위해 관련 상태 데이터베이스 (“blockchain bloat”) 에 데이터를 저장하는 데 상당한 비용을 지불해야 합니다. 따라서 데이터 자체가 아니라 상태 데이터베이스에서 데이터의 IPFS 해시를 저장하는 것이 일반적인 설계 패턴입니다.
연관된 상태 데이터베이스와 블록체인이 이미 IPFS에 표시되어 있는 경우, 모든 것이 IPFS에만 저장되므로 블록체인에 해시를 저장하고 블록체인에 데이터를 저장하는 것 사이의 구분이 다소 모호해집니다. 이 경우 IPFS 링크를 블록체인에 저장한 경우, 마치 데이터가 블록체인에 저장된 것처럼 이 링크를 따라 데이터에 액세스할 수 있습니다.
그러나 온체인과 오프체인 데이터 스토리지를 구분할 수 있습니다. 새로운 블록을 만들 때 마이너가 처리해야하는 것을 살펴봄으로써 이를 수행합니다. 현재 Ethereum 네트워크에서 마이너는 상태 데이터베이스를 업데이트 할 트랜잭션을 처리해야 합니다. 이렇게 하려면 전체 상태 데이터베이스에 액세스 하여야 변경된 곳마다 데이터베이스를 업데이트 할 수 있습니다.
따라서 IPFS로 표현 된 블록 체인 상태 데이터베이스에서 “온체인”또는 “오프체인”으로 데이터에 태그를 지정해야 합니다. 마이너가 마이닝을 위해 국부적으로 유지하기 위해서는 “온체인” 데이터가 필요하며 이 데이터는 거래의 직접적인 영향을받습니다. “오프체인” 데이터는 사용자가 업데이트 해야하며 마이너가 접촉 할 필요가 없습니다.
IPFS 를 지탱하는 기반 기술
IPFS 에서는 Kademlia DHT 와 BitTorrent 그리고 Git, Self-certifying File System 에 대한 이해를 필요로 합니다.
앞으로 차근차근 이에대한 이야기를 하도록 하겠습니다.
