Distributed Hash Tables in IPFS
DHT (Distributed Hash Tables)
분산 해시 테이블을 의미하는 것으로 말 그대로 해시 테이블을 분산하여 관리하는 기술 입니다.
어떤 항목을 찾아갈 때 해시 테이블을 이용하는데, 중앙 시스템이 아닌 각 노드들이 이름을 값으로 맵핑하는 기능을 하는 방식으로 부하가 집중되지 않고 분산된다는 큰 장점이 있어, 극단적으로 큰 규모의 노드들도 관리할 수 있습니다.

살짝 감이 오지 않습니까? IPFS 의 주요 기능말입니다.
분산 해시 테이블에 대한 기본 이해
해시 테이블은 Key/Value 데이터 구조로 구성되어 있습니다. DHT는 해싱으로 생성된 데이터 Key 값과 서버 ID 의 짝을 시스템을 구성하고 있는 모든 노드에 균일하게 분산하기 위하여 고안된 lookup 방법입니다. 데이터 Key 값과 서버 ID 를 통하여 모든 노드와 데이터들을 동일 주소 공간에 할당함으로써 데이터와 노드 정보들을 한꺼번에 관리하기가 용이하기 때문에 P2P 시스템에서 많이 사용합니다. (데이터의 Key 값과 분산 서버 ID는 동일한 해시 함수로 동일한 주소 공간에 데이터와 노드를 배치)
한마디로 중앙 서버 없이 데이터를 관리하는 분산된 서버를 찾을 수 있으며 클러스터에 참여하는 서버의 추가/제거가 자동으로 이루어질 수 있도록 구성할 수 있기 때문입니다.
부하가 집중되지 않고 분산된다는 큰 장점이 있어, 극단적으로 큰 규모의 노드들도 관리할 수 있습니다. 종래의 순수 P2P에서 채용되었던 방식에서는 수십만 노드 정도가 한계였으나, DHT의 사용으로 수십억개의 노드를 검색범위로 할 수 있게 되었습니다.
IPFS 에서는 Kademlia DHT 와 BitTorrent 그리고 Git, Self-certifying File System 에 대한 이해를 필요로 합니다.
각각은 차차 알아보기로 하고 조금 더 DHT 에 대한 이야기를 해보겠습니다.
IPFS 에서 DHT
네트워크에 참여한 노드가 해시 테이블을 사용하여 서버없이 P2P 네트워크를 실현하는 기술로 파일(데이터, 컨텐츠)을 검색하는데 사용됩니다.
HTTP는 IP를 기반으로 검색이 되었으나 IPFS는 Content-Addressed를 사용합니다. 즉, 컨텐츠 자체가 주소역할을 대신 합니다.
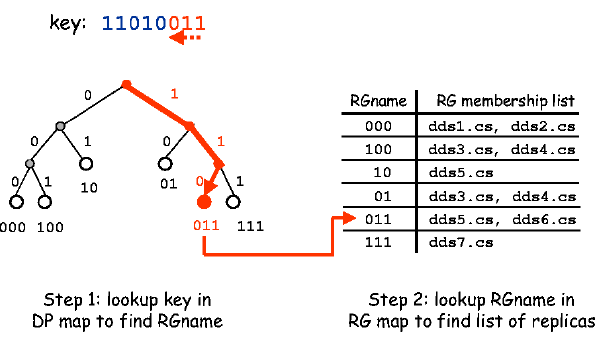
| Content Name | Node Location |
|---|---|
| Content01 | Node01 |
| Content02 | Node03, Node05 |
| Content03 | Node02, Node08 |
해시테이블에서 컨텐츠 이름을 찾으면 컨텐츠를 보유하고 있는 노드를 알 수 있습니다.
Kademlia DHT
Kademlia는 현재 가장 대중적으로 사용되는 P2P DHT 입니다. Kademlia는 다음과 같은 용어에 대한 이해가 필요합니다.
- Node: node는 Kademlia DHT 네트워크에 참여하는 컴퓨터
- pair (Key/Value): KV(Key/Value) 형태로 데이터를 저장, Kademlia 네트워크에서 값을 찾기 위한 고유 키이며 값은 DHT에 저장되는 데이터
- LookUP: Kademlia 네트워크에서 주어진 키에 대한 실제 값을 찾는 과정
- Data/Content: Kademlia DHT에 pair(KV) 형태로 저장되어 있는 실제 데이터
Kademlia를 사용하는 이유
- Node간 주고받는 데이터를 최소화
- 네트워크에 속한 node, 인접 node 등에 대한 설정 정보가 자동적으로 Kademlia 네트워크에 확산
- Kademlia 네트워크의 node들은 다른 node를 통해 파악 (적은 비용으로 node간 경로 탐색)
- Kademlia는 작동하지 않는 node의 timeout을 피할 수 있는 병렬적이고, 비동기적 쿼리 제공
- DOS 공격 방지
Key
Kademila는 Node와 데이터를 식별하기 위해 160 비트 key를 이용합니다. 네트워크에 참여하는 컴퓨터는 각각 160 비트 NodeId 키를 가집니다. Kademila는 pair(KV)로 데이터를 저장하기 때문에 160 비트 key를 사용해서 데이터를 식별합니다.
Distance
두 Node 간의 ‘거리’를 계산하는 것으로 두 NodeId의 XOR로 계산되고 정수형 값을 가집니다. Key와 NodeId는 같은 형태, 길이의 정수형 값을 가지고 있기 때문에 XOR연산이 가능합니다. NodeId는 Node를 식별할 수 있는 무작위의 정수형 값(UUID)을 가집니다. 즉, 물리적 거리가 먼 Node라도 NodeId 값이 비슷하다면 논리적으로 이웃에 위치할 수 있습니다.
- 임의의 Node와 그 Node 자신에 대한 거리는 0
- XOR 연산은 대칭성을 가짐: A에서 B 거리의 계산 결과는 B에서 A 거리와 동일
- 삼각 부등식 성립: A, B, C Node가 주어질 경우, A와 B 사이 거리는 A와 C 또는 C와 B의 거리합과 같거나 작음
위와 같은 특징은 간단하면서 빠른 XOR 연산의 특징을 보여줍니다.
Kademlia 탐색 작업이 반복될 때마다 한 비트씩 탐색 대상에 가까워집니다. 2^n 개의 Node를 가지고 있는 Kademlia 네트워크에서는 최대 n번 탐색을 반복하면 임의의 Node를 찾을 수 있습니다.
라우팅 테이블
각 NodeId들의 각 비트를 저장한 리스트를 포함하고 있습니다. 리스트의 모든 항목은 다른 Node들의 위치에 대한 주요 정보를 저장합니다. 리스트의 각 항목은 일반적으로 다른 Node의 IP 주소, 포트, NodeId를 저장합니다. 후보 id의 n-1번째 비트는 NodeId와 일치하여야 합니다. (모든 리스트는 특정 node의 거리와 대응됩니다. n번째 리스트에 갈 수 있는 Node는 반드시 NodeId의 n번째 비트가 달라야 합니다.)
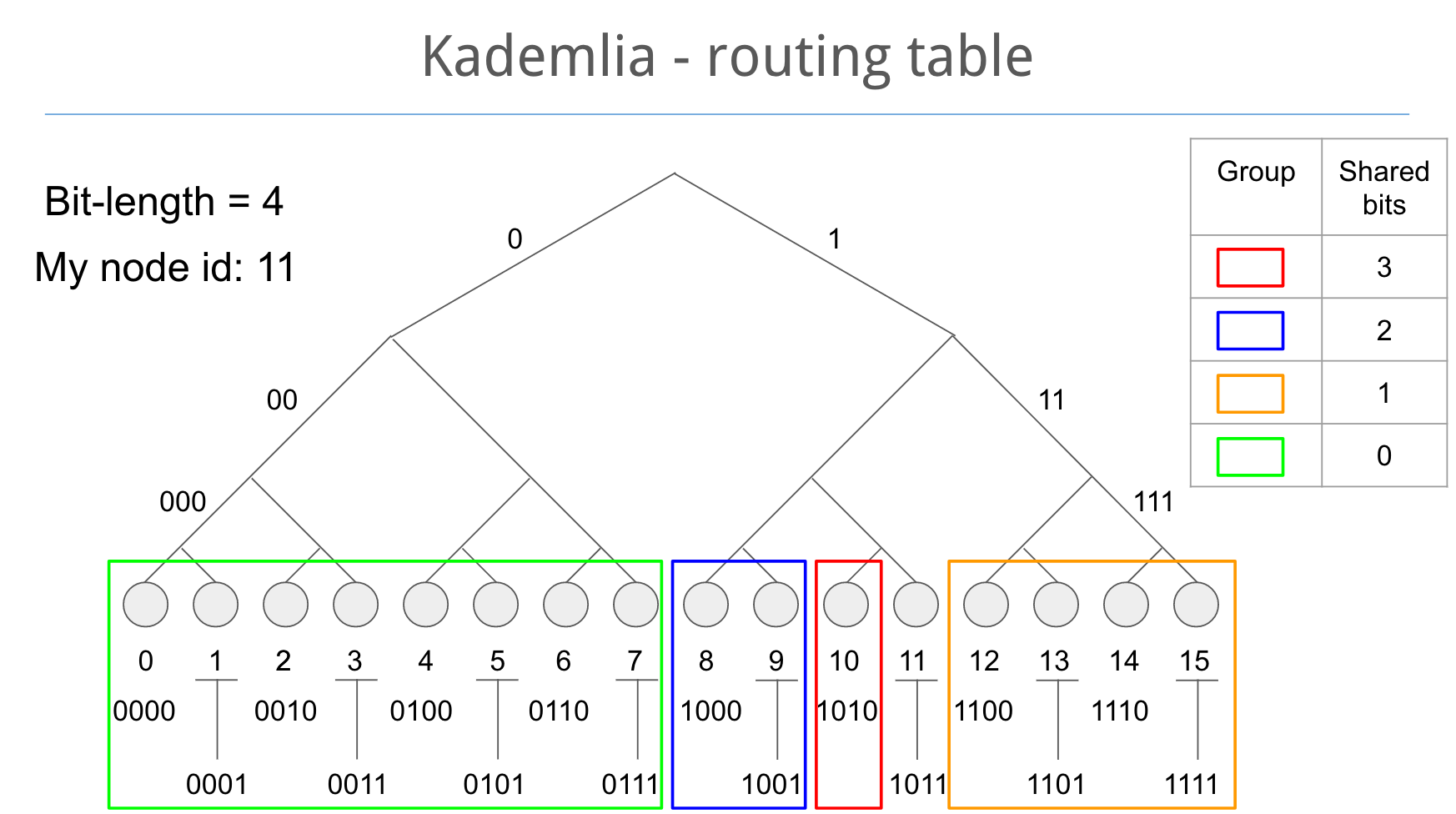
128 비트의 id가 있는 네트워크에서는, 128개의 다른 거리로 다른 Node들을 식별하게 됩니다. Node가 네트워크에 참가하게 되면, 리스트에 추가됩니다. 이러한 과정은 통해 다른 Node들이 Key를 찾는 것을 돕습니다.
프로토콜 메시지
- PING: Node 작동상태 확인
- Sotre: 한 Node에 pair(KV) 데이터를 저장
- FIND_NODE: 요청한 Key에 제일 가깝게 위치한 k Node들을 반환
- FIND_VALUE: FIND_NODE와 같은 역할을 하며 요청한 Key에 대한 해당 데이터가 있으면 데이터 반환
요청에 의해 반환되는 RPC 메시지는 발신자가 지정한 랜덤한 값을 포함합니다. 랜덤으로 정해진 값은 요청 메시지와 응답 결과를 대응시키기 위해 사용됩니다.
Location Nodes
Node 탐색은 동기적으로 동작합니다. 동시에 일어나는 탐색 요청은 α로 나타내며, 일반적인 α 값은 3입니다. Node은 원하는 Key 값에 가장 가까운 α개의 Node에 FIND_NODE 요청을 전송합니다. FIND_NODE 요청을 받은 Node들은 자신의 k-buckets을 탐색하여 Key 값에 가장 가까운 k개의 Node들을 반환합니다. 탐색 요청자는 요청 결과를 저장하며, k개의 가장 가까운 NodeId를 저장합니다.
탐색 요청자는 저장하고 있는 NodeId들을 선택하여 각 Node들이 위와 같은 요청을 하도록 하는 작업이 반복됩니다. 각 Node들은 자신 주위에 있는 Node들에 가장 잘 알고 있기 때문에 이러한 작업이 반복될 수록 Key 값에 더 가까운 Node를 찾게 됩니다.
탐색 작업은 전 탐색 결과보다 Key에 더 가까운 Node들이 없을때까지 반복됩니다. 탐색이 중지되었을때 저장되어 있는 k Node들이 원하는 Key에 가장 가까운 Node가 됩니다.
