IPFS 프로토콜 교환 계층 분석 - Provide Blocks
IPFS 데이터 교환 계층-Provide Blocks
GetBlocks 인터페이스가 동작하면서 Keys 요청을 받은 후 각 모듈에 KEYS에 대한 요청을 캐시하고 라우팅 계층을 통해 해당 데이터를 찾기 시작합니다. KEYS를 WantManager에 등록함과 동시에 WantManager는 이미 설정된 링크의 노드 정보를 Map에 저장하고 GetBlocks 요청이 수신되면 WantManager는 요청을 설정된 노드로 보냅니다. 다음 그림은 노드 정보의 Map 데이터 구조 입니다.
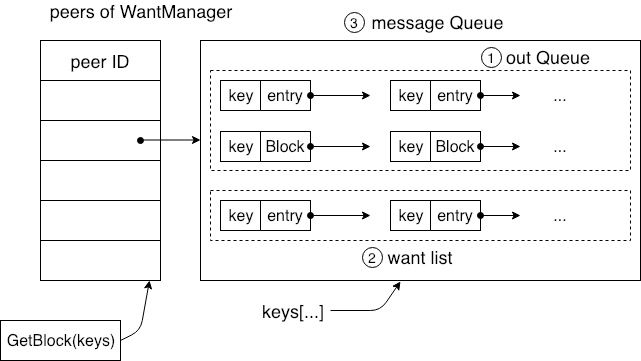
각 노드의 PeerID가 Message Queue에 해당하는 것을 확인할 수 있습니다. Message Queue는 Want List와 Out Queue의 두 부분으로 구성됩니다. Out Queue는 또 다른 Want List와 Block List가 있으며 Want List는 해당 키에 대한 요청을 저장하고 Block List는 Key에 해당하는 데이터를 저장합니다.
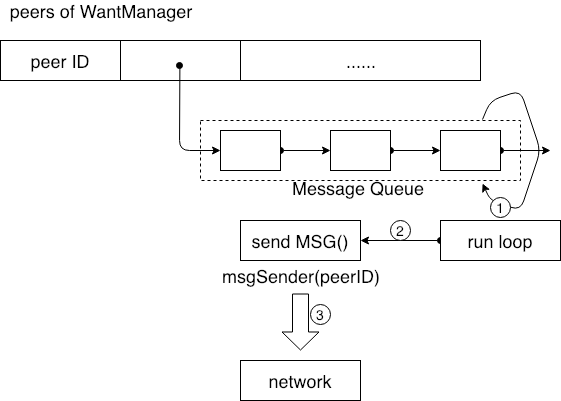
위 그림에서 각 메시지 대기열의 자체 run loop 를 활용하여 신규 검색 명령어가 오면 run loop 는 msgSender 객체를 통해 검색명령을 실행합니다. 이미 Peers MAP을 사용하고 있기 때문에 알고 있는 수신자 peerID를 Message sender 객체에 전달하여 네트워크 레이어를 통해 링크를 설정하고 검색명령을 수신자에게 전달할 수 있습니다.
이러한 내용은 노드와 링크를 설정한 노드의 검색명령을 수신하는 로직에 대한 내용입니다. 각 캐시는 명령어를 검색하는 방법과 각 캐시 자체의 run loop 가 데이터 쿼리 명령을 단계적으로 실행하는 방법이 저장됩니다.
다음은 이러한 쿼리 명령을 받은 후 쿼리된 노드가 어떻게 반응하는지 살펴보겠습니다.
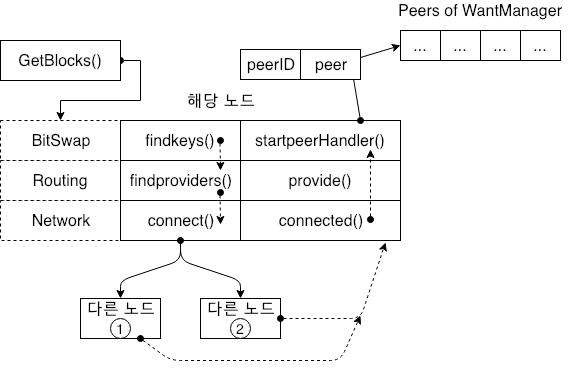
Want Manager 가 다른 노드 정보를 관리하지 않는 경우 GetBlocks 는 쿼리 개체의 KEY 배열의 첫번째 KEY에서 findkeys() 를 호출할 수 있습니다. 위 그림에서 링크 요청을 수신한 수 다른 노드의 동작을 추가하는 것을 볼 수 있습니다. 먼저 다은 노드가 해당 노드와 데이터 링크를 설정하고 IPFS의 프로토콜 계층은 다른 노드 정보를 Want Manager 의 다른 노드 목록에 추가하여 관리하게 됩니다. 위 그림은 프로토콜의 각 계층에 대한 키 처리를 보여줍니다.
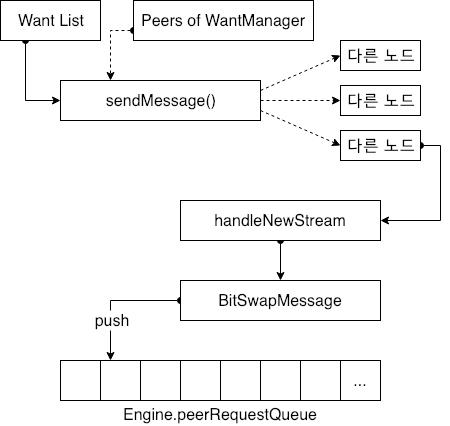
다른 노드 정보를 얻은 후 Send Message 요청을 시작하는 Run loop 가 존재하고 있음을 알게되며 해당 노드는 데이터를 찾는데 필요한 KEY 값을 사용 가능한 다른 모든 노드로 보냅니다. 데이터 쿼리 요청을 수신한 다른 노드는 네트워크 계층을 통해 데이터를 수락하고 데이터 교환 계층이 사용하는 BitSwapMessage 형식으로 수락한 데이터를 결합하고 이를 PeerRequestQueue 엔진 모듈의 큐에 배치합니다.
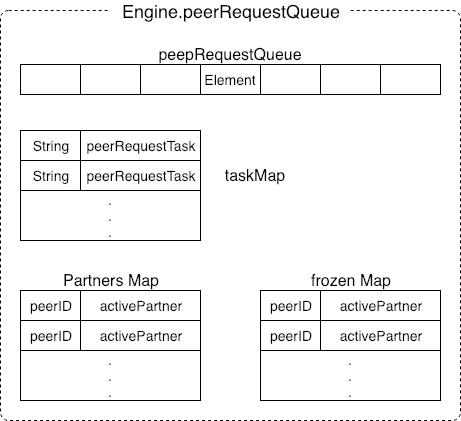
위 그림은 Engine.peerRequestQueue 의 데이터 구조로 특정 데이터의 목록을 유지하는 것을 보여줍니다. TaskMap 은 요청 작업을 관리하는데 사용되며 허용된 각 데이터는 하나의 작업으로 캡슐화됩니다. 요청을 보내는 피어 정보를 저장하기 위한 두가지 맵도 존재합니다. 하나는 partners Map 이고 다른 하나는 frozon partners Map (고정 파트너 맵) 입니다. IPFS 데이터 교환 프로토콜에서 Engine 은 노드 및 기타 내용을 관리합니다. 악의적인 공격을 막기위한 노드의 데이터 교환노드가 데이터만 수집하고 데이터를 제공하지 않으면 이 노드는 다른 노드에 의해 고정된 목록으로 추가될 수 있습니다.
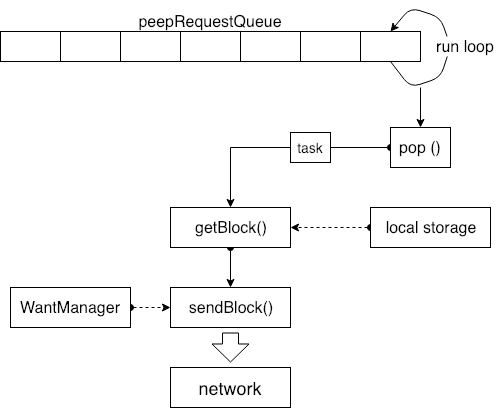
데이터 요청 큐에는 task 가 있는지 여부를 지속적으로 확인하고 큐 헤더의 순서대로 pop 하고 요청한 task 를 가지고 온 다음 task 에 저장된 데이터를 로컬 데이터 저장소에 조회하여 저장하는 run loop 가 있습니다. 데이터 요청 키가 검색되고 키에 해당하는 특정 데이터 블록을 찾고 데이터를 가지고 오면 Send Manager 의 sendBlock 인터페이스가 호출되어 데이터를 네트워크로 전송합니다.
IPFS 프로토콜 교환 계층 분석 - GetBlocks
IPFS 데이터 교환 계층-GetBlocks
데이터 교환 계층이 상위 프로토콜에 대해 제공해야 하는 기본 기능을 알아보고자 합니다. 우선 IPFS의 교환 계층 인터페이스 설계는 다음 위치에서 확인할 수 있습니다.
IPFS exchange interface (interface.go)
// Package exchange defines the IPFS exchange interface
package exchange
import (
"context"
"io"
blocks "github.com/ipfs/go-block-format"
cid "github.com/ipfs/go-cid"
)
// Interface defines the functionality of the IPFS block exchange protocol.
type Interface interface { // type Exchanger interface
Fetcher
// TODO Should callers be concerned with whether the block was made
// available on the network?
HasBlock(blocks.Block) error
IsOnline() bool
io.Closer
}
// Fetcher is an object that can be used to retrieve blocks
type Fetcher interface {
// GetBlock returns the block associated with a given key.
GetBlock(context.Context, cid.Cid) (blocks.Block, error)
GetBlocks(context.Context, []cid.Cid) (<-chan blocks.Block, error)
}
// SessionExchange is an exchange.Interface which supports
// sessions.
type SessionExchange interface {
Interface
NewSession(context.Context) Fetcher
}
데이터 교환 계층이 상위 계층 프로토콜을 위해 제공해야하는 기본 기능을 결정하는 위 코드는 IPFS의 스위치 계층 인터페이스 설계이며 데이터를 검색하고 데이터를 교환하는 기능을 제공하기 위해 특정 스위치 계층 구현자를 필요로 합니다.
GetBlocks: 지정된 키 세트에 해당하는 데이터 인터페이스를 가지고 옵니다.
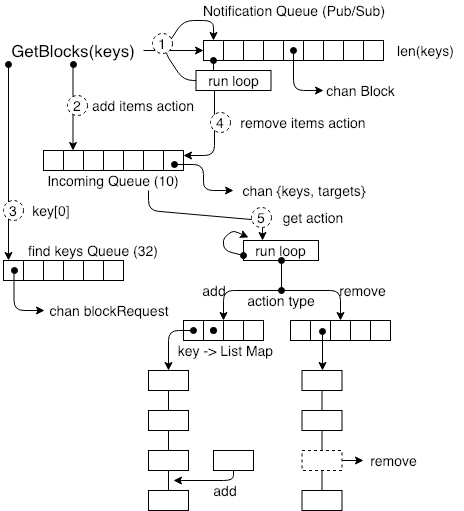
위의 그림은 GetBlocks() 인터페이스의 첫 번째 단계로, 키 집합에 해당하는 데이터 요청을 데이터 교환 계층의 여러 구성 요소로 전송하여 각 모듈에 새 작업이 도착했음을 알립니다.
먼저 모든 키를 Pub/Sub 모듈에 건네고 모든 키를 알림 대기열(Notification Queue)이라는 구독 큐에 추가합니다. 이 구독 큐는 파이프 그룹이며 파이프 그룹의 길이는 키 수에 의해 결정됩니다. 이 파이프 라인 큐 관리는 순환루틴입니다. 가입 키에 대응하는 데이터 블록이 도착할 때마다, want list로 부터 삭제 요청이 생성되고, 위 그림의 절차 4에 도시 된 바와 같이, 획득 된 데이터에 대응하는 키가 want list로 부터 삭제된다.
두 번째 단계에서는 그룹 키가 요청 데이터 항목에 패키지화되어 Incoming Queue에 추가됩니다. 이는 고정 크기가 10인 요청 캐시이며 데이터를 가져 오기위한 요청과 데이터 요청 취소 요청을 저장하는 데 사용됩니다. 이 대기열의 사용은 계속해서 다음 섹션에서 설명합니다. 그의 역할은 데이터에 대한 캐시 요청으로 작동하는 것입니다.
세 번째 단계에서이 키 집합의 0 번째 요소는 findkeys Queue의 요소로 삽입되며 큐의 길이는 32 고정 크기입니다. 이 큐의 상세한 사용은 다음에 상세하게 설명합니다.
다섯 번째 단계는 Incoming Queue에서 작업을 제거하고 작업 유형을 결정하는 것입니다. 데이터의 ID에 따라 Key-Value 맵이 있습니다. 맵의 각 항목은 메시지 대기열입니다. 작업 유형이 증가하면, 작업 유형으로 전달 된 키를 대기열에 추가하고, 삭제 된 경우 키에 따라 메시지 대기열에서 데이터를 삭제하는 방법은 다음과 같습니다. 이 단계에서 사용 된 실행 루프는 두 가지 유형의 원하는 목록에서 작동해야한다는 점을 지적해야합니다. 하나는 normal want list이고 다른 하나는 broadcast want list입니다. broadcast want list는 질의 노드없이 키 데이터를 저장합니다. normal want list는 이니시에이터가 고정 키 배열을 찾기 위해 지정한 질의 노드 객체를 찾습니다.
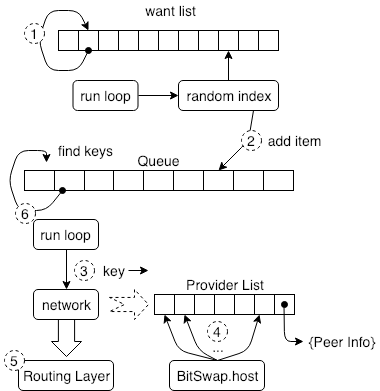
normal want list에는 Findkeys Queue에 가입하기 위해 목록에서 임의로 키를 선택하는 동시 루틴 타이밍이 있습니다. Findkeys Queue에는 이 큐를 관리하기 위한 순환이 있습니다. 이 큐는 요소 중 하나를 사용하고 데이터 교환 프로토콜에 액세스합니다. 네트워크 인터페이스는, 어떤 노드가 요소에 대한 데이터 (요소의 데이터에 해당하는 키 값)를 제공 할 수 있는지 쿼리하고, 네트워크 인터페이스는 해당 라우팅 계층을 호출하여 해당 노드를 찾습니다.
네트워크 인터페이스는 키에 대한 데이터 공급자 목록을 반환합니다. 이 목록에 저장된 요소는 Peer Info입니다. 이 정보는 네트워크 계층 (네트워크 레이어 - 라우팅 레이어 - 파일교환 레이어 순서)에 사용됩니다. 데이터 연결에 대한 기본 정보를 설정합니다. 데이터 교환 층은 데이터 교환 층과 네트워크 층 사이의 네트워크 링크 정보를 관리하는 호스트 객체를 갖는다. 이 개체를 통해 데이터 교환 계층은 반환 된 모든 네트워크 계층 노드와 직접 연결됩니다.
요약하면이 섹션에서는 주로 GetBlocks() 인터페이스 명령을 받아들이는 노드의 처리 흐름을 분석합니다.이 명령을받은 후에 노드는 명령을 캐시하고 네트워크 전체의 데이터 쿼리를 수행하도록 각 큐에 알리는 것에 중점을 둡니다. 관련 노드는 직접 네트워크 레이어 링크를 설정합니다. 다음 섹션에서는 데이터 수집 프로세스의 전체 과정이 데이터 공급자 또는 데이터 중계자의 관점에서 어떻게 구현되는지 분석합니다.
[논문분석] Docker Reference Architecture: Designing Scalable, Portable Docker Container Networks
원문: Docker Reference Architecture: Designing Scalable, Portable Docker Container Networks
배우게 될 것
도커 컨테이너는 실행에 필요한 모든 것, 즉 코드, 런타임, 시스템 도구, 시스템 라이브러리 등 서버에 설치할 수 있는 모든 것을 포함하는 완전한 파일 시스템에 있는 소프트웨어 하나를 래핑한다. 이는 소프트웨어가 환경에 관계없이 항상 동일한 기능을 실행할 것을 보장한다. 기본적으로 컨테이너는 애플리케이션을 서로 격리하고, 애플리케이션을 위한 추가적인 보호 계층을 제공한다.
애플리케이션이 서로 간에, 또는 호스트와, 혹은 외부 네트워크와 통신해야 한다면 어떻게 해야하는가? 애플리케이션 이식성, 서비스 검색, 로드 밸런싱, 보안, 성능 및 확장성을 유지하면서 적절한 연결성을 위해 네트워크를 설계하는 방법은 무엇인가? 이 문서는 이러한 네트워크 설계 문제와 사용 가능한 도구 및 일반적인 배포 패턴을 다룬다. 물리적 네트워크 설계을 기술하거나 권장하지는 않지만 애플리케이션과 물리적 네트워크의 제약 조건을 고려하면서 도커 네트워크를 설계하는 방법에 대한 선택 사항들을 제공한다.
사전 지식
계속하기 전에 도커 개념과 도커 Swarm에 대해 잘 알고 있어야 한다.
네트워킹 컨테이너 및 마이크로 서비스의 미션
마이크로서비스는 실전에서 애플리케이션의 스케일을 증가시켰는데, 이러한 애플리케이션들은 제공되는 연결성 및 격리 방법들이 훨씬 더 중시된다. 도커 네트워킹 철학은 애플리케이션 중심이다. 네트워크 운영자에게 옵션과 유연성을 제공하는 것을 목표로 하는 것 뿐만 아니라 애플리케이션 개발자에게 적합한 수준의 추상화를 제공하는 것을 목표로 한다.
여느 설계처럼, 네트워크 설계은 밸런스를 맞추는 행위이다. 도커 엔터프라이즈 에디션과 도커 생태계는 네트워크 엔지니어들에게 그들의 애플리케이션과 환경에 대한 최상의 밸런스를 달성하기 위해 다양한 도구를 제공한다. 각 옵션은 서로 다른 장점과 트레이드오프를 제공한다. 이 가이드의 나머지 부분에서는 네트워크 엔지니어가 자신의 환경에 가장 적합한 것을 이해할 수 있도록 이러한 각각 선택에 대해 자세히 설명한다.
도커는 애플리케이션을 공급하는 새로운 방법을 개발했고, 그와 함께 컨테이너는 네트워킹 접근 방식의 일부 측면도 변화시켰다. 다음 주제는 컨테이너형 애플리케이션에 대한 일반적인 설계 주제이다.
- 이식성
- 고유한 네트워크 특성을 활용하면서 다양한 네트워크 환경에서 최대한의 이식성을 어떻게 보장할 수 있는가?
- 서비스 검색
- 서비스가 확장 및 축소될 때 어디에 살고 있는지 어떻게 알 수 있는가?
- 로드 밸런싱
- 서비스 자체가 커지고 확장될 때 서비스 간에 부하를 어떻게 공유하는가?
- 보안
- 잘못된 컨테이너가 서로 액세스하지 못하도록 어떻게 구분하는가?
- 애플리케이션 및 클러스터 제어 트래픽이 있는 컨테이너가 안전하다는 것을 어떻게 보장하는가?
- 성능
- 대기 시간을 최소화하고 대역폭을 최대화하는 동시에 고급 네트워크 서비스를 어떻게 제공하는가?
- 확장성
- 여러 호스트에 걸쳐 애플리케이션을 확장할 때 이러한 특성들이 저하되지 않도록 하려면 어떻게 하는가?
컨테이너 네트워킹 모델
도커 네트워킹 아키텍처는 CNM(Container Networking Model)이라고 하는 인터페이스 집합 위에 구축된다. CNM의 철학은 다양한 인프라 구조에서 애플리케이션 이식성을 제공하는 것이다. 이 모델은 애플리케이션 이식성을 이루기 위해 밸런스를 맞추고 인프라의 특징과 기능을 활용한다.

CNM 구성물
CNM에는 몇 가지 상위 레벨의 구성물이 있다. 이들은 모두 OS 및 인프라에 구애받지 않으므로 인프라 스택에 관계없이 애플리케이션이 동일한 환경을 가질 수 있다.
- 샌드박스 - 샌드박스는 컨테이너 네트워크 스택의 설정을 포함한다. 여기에는 컨테이너 인터페이스, 라우팅 테이블 및 DNS 설정 관리가 포함된다. 샌드박스의 구현은 Linux 네트워크 네임스페이스, FreeBSD Jail 또는 기타 유사한 개념일 수 있다. 샌드박스는 여러 네트워크의 많은 엔드포인트를 포함할 수 있다.
- 엔드포인트 - 엔드포인트가 샌드박스를 네트워크에 연결한다. 엔드포인트는 네트워크에 대한 실제 연결을 애플리케이션에서 추상화할 수 있도록 존재한다. 이는 서비스가 네트워크에 어떻게 연결되어 있는지에 신경쓰지 않으며 여러 유형의 네트워크 드라이버를 사용할 수 있도록 이식성을 유지하는데 도움을 준다.
- 네트워크 - CNM은 OSI 모델 측면에서 네트워크를 명시하지 않는다. 네트워크의 구현은 리눅스 브리지, VLAN 등이 될 수 있다. 네트워크는 이들 사이에 연결성이 있는 엔드포인트의 모음이다. 네트워크에 연결되지 않은 엔드포인트는 네트워크에 연결되어 있지 않다.
CNM 드라이버 인터페이스
컨테이너 네트워킹 모델은 사용자, 커뮤니티 및 벤더가 네트워크에서 추가 기능, 가시성 또는 제어 기능을 활용할 수 있는 2개의 플러그형 및 개방형 인터페이스를 제공한다.
다음과 같은 네트워크 드라이버가 있다.
- 네트워크 드라이버 - 도커 네트워크 드라이버는 네트워크를 작동시키는 실제 구현을 제공한다. 다른 드라이버를 사용할 수 있고 다양한 유스케이스를 쉽게 지원할 수 있도록 상호 교환될 수 있는 플러그 스타일이다. 주어진 도커 엔진 또는 클러스터에서 여러 개의 네트워크 드라이버를 동시에 사용할 수 있지만, 각 도커 네트워크는 단일 네트워크 드라이버를 통해서만 인스턴스화된다. CNM 네트워크 드라이버는 크게 두 가지 유형이 있다.
- 네이티브 네트워크 드라이버 - 네이티브 네트워크 드라이버는 도커 엔진의 네이티브 요소이며 도커에서 제공한다. 오버레이 네트워크나 로컬 브리지와 같은 다양한 기능을 지원하는 여러 드라이버가 있다.
- 원격 네트워크 드라이버 - 원격 네트워크 드라이버는 커뮤니티와 다른 벤더가 만든 네트워크 드라이버이다. 이러한 드라이버는 기존 소프트웨어 및 하드웨어와의 통합을 제공할 수 있다. 사용자는 또한 기존 네트워크 드라이버가 지원하지 않는 특정 기능을 원하는 경우 자신의 드라이버를 만들 수도 있다.
- IPAM 드라이버 - 도커에는 네트워크 및 엔드포인트의 기본 서브넷 또는 IP 주소를 지정하지 않은 경우 이를 제공하는 네이티브 IP 주소 관리 드라이버가 있다. IP 주소 지정은 네트워크, 컨테이너 및 서비스 생성 명령을 통해 수동으로 할당할 수도 있다. 원격 IPAM 드라이버도 존재하며 기존 IPAM 도구와 통합된다.

도커 네이티브 네트워크 드라이버
도커 네이티브 네트워크 드라이버는 도커 엔진의 일부이므로 추가 모듈은 필요없다. 이들은 표준 docker network 명령을 통해 호출되고 사용된다. 다음과 같은 네이티브 네트워크 드라이버가 있다.
| 드라이버 | 설명 |
|---|---|
| Host | host 드라이버가 있는 호스트 컨테이너는 호스트의 네트워킹 스택을 사용함. 네임스페이스 분리가 없으므로 호스트의 모든 인터페이스를 컨테이너에서 직접 사용할 수 있음. |
| Brdige | bridge 드라이버는 도커가 관리하는 호스트에 리눅스 브리지를 생성함. 기본적으로 브리지의 컨테이너는 서로 통신할 수 있음. 또한 브리지 드라이버를 통해 컨테이너에 대한 외부 액세스를 구성할 수 있음. |
| Overlay | overlay 드라이버는 도커 외부에서 다중 호스트 네트워크를 지원하는 오버레이 네트워크를 생성함. 로컬 리눅스 브리지와 VXLAN을 함께 사용하여 물리적 네트워크 인프라를 통해 컨테이너와 컨테이너 간의 통신을 오버레이함. |
| MACVLAN | macvlan 드라이버는 MACVLAN 브리지 모드를 사용해서 컨테이너 인터페이스와 상위 호스트 인터페이스(또는 하위 인터페이스) 간의 연결을 설정함. 물리적 네트워크에서 라우팅 가능한 컨테이너에 IP 주소를 제공하기 위해 사용될 수 있음. 또한 VLAN은 Layer 2 컨테이너 분할을 실행하기 위해 macvlan 드라이버에 트렁킹될 수 있음. |
| None | none 드라이버는 컨테이너에 자체 네트워킹 스택과 네트워크 네임스페이스를 제공하지만, 컨테이너 내부에 인터페이스를 구성하지는 않음. 추가 구성없이 컨테이너가 호스트 네트워킹 스택에서 완전히 분리됨. |
네트워크 스코프
docker network ls 출력에서 볼 수 있듯이, 도커 네트워크 드라이버는 스코프 라는 개념이 있다. 네트워크 스코프는 local 또는 swarm 범위인 드라이버의 도메인이다. Local 스코프 드라이버는 호스트의 범위 내에서 연결 및 네트워크 서비스(예: DNS 또는 IPAM)를 제공한다. Swarm 스코프 드라이버는 Swarm 클러스터 전반에서 연결 및 네트워크 서비스를 제공한다. Swarm 스코프 네트워크는 전체 클러스터에서 동일한 네트워크 ID를 가지고 있고, 반면에 Local 스코프 네트워크는 각 호스트에 고유한 네트워크 ID를 가지고 있다.
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
1475f03fbecb bridge bridge local
e2d8a4bd86cb docker_gwbridge bridge local
407c477060e7 host host local
f4zr3zrswlyg ingress overlay swarm
c97909a4b198 none null local
도커 원격 네트워크 드라이버
아래 커뮤니티 및 벤더에서 만든 원격 네트워크 드라이버는 CNM과 호환되며, 각 드라이버는 컨테이너를 위한 고유한 기능과 네트워크 서비스를 제공한다.
| 드라이버 | 설명 |
|---|---|
| contiv | 멀티 테넌트(Multi-tenant) 마이크로 서비스 구현를 위한 인프라 및 보안 정책을 제공하는 오픈 소스 네트워크 플러그인, Cisco Systems가 리딩. 또한 Contiv는 비컨테이너 워크로드 및 ACI와 같은 물리적 네트워크에 대해 통합을 제공. Contiv는 원격 네트워크 및 IPAM 드라이버를 구현하고 있음. |
| weave | 도커 컨테이너를 여러 호스트 또는 클라우드에 연결하는 가상 네트워크를 만드는 네트워크 플러그인. Weave는 애플리케이션 자동 검색 기능을 제공하며 부분적으로 연결된 네트워크에서 작동할 수 있으며, 외부 클러스터 저장소가 필요하지 않고, 운영 친화적임. |
| calico | 클라우드 데이터 센터의 가상 네트워킹을 위한 오픈 소스 솔루션. 대부분의 워크로드(VM, 컨테이너 또는 베어 메탈 서버)가 IP 연결만 필요로 하는 데이터 센터를 대상으로 함. Calico는 표준 IP 라우팅을 사용하여 이 연결성을 제공함. 테넌트 소유권 (tenant ownership) 또는 보다 세분화된 정책에 따라 워크로드 간의 격리는 소스 및 대상 워크로드를 호스팅하는 서버에서 iptables 프로그래밍을 통해 수행됨. |
| kuryr | 오픈스택 Kuryr 프로젝트의 일부로 개발된 네트워크 플러그인. 오픈스택 네트워킹 서비스인 Neutron을 활용하여 도커 네트워킹 (libnetwork) 원격 드라이버 API를 구현함. Kuryr에는 IPAM 드라이버도 포함되어 있음. |
도커 원격 IPAM 드라이버
커뮤니티 및 벤더가 만든 IPAM 드라이버도 기존 시스템 또는 특수 기능과의 통합을 제공하는데 사용될 수 있다.
| 드라이버 | 설명 |
|---|---|
| infobox | 기존 Infoblox 툴과 통합되는 오픈소스 IPAM 플러그인. |
많은 도커 플러그인이 존재하며, 더 많은 플러그인이 계속 만들어지고 있다. 도커는 가장 일반적인 플러그인 목록을 유지한다.
리눅스 네트워크 기본원리
리눅스 커널은 TCP/IP 스택 (DNS 및 VXLAN과 같은 기타 네이티브 커널 기능과 더불어)을 매우 성숙하고 효율적으로 구현한다. 도커 네트워킹은 커널의 네트워킹 스택을 하위 레벨의 기본 요소로 사용하여 상위 레벨의 네트워크 드라이버를 만든다. 간단히 말해서, 도커 네트워킹 은 리눅스 네트워킹 이다.
기존에 구현된 리눅스 커널 기능은 고성능과 견고성을 보장한다. 가장 중요한 점은 여러 배포판과 버전에 걸쳐 이식성을 제공하므로 애플리케이션의 이식성이 향샹된다는 것이다. *도커가 네이티브 CNM 네트워크 드라이버를 구현하는데 사용하는 몇 가지 리눅스 네트워킹 빌딩 블록이 있다. 이 목록에는 리눅스 브리지, 네트워크 네임스페이스, veth pair 및 iptable이 포함된다. 네트워크 드라이버로 구현되는 이러한 도구의 조합은 복잡한 네트워크 정책을 위한 전달 규칙, 네트워크 분할 및 관리 도구를 제공한다.
리눅스 브리지
리눅스 브리지는 리눅스 커널 내부의 물리적 스위치를 가상으로 구현한 Layer 2 디바이스이다. 트래픽을 검사하여 동적으로 학습되는 MAC 주소를 기반으로 트래픽을 전달한다. 리눅스 브리지는 많은 도커 네트워크 드라이버에서 광범위하게 사용된다. 리눅스 브리지를 리눅스 브리지의 상위 레벨 구현인 bridge 도커 네트워크 드라이버와 혼동해서는 안된다.
네트워크 네임스페이스
리눅스 네트워크 네임스페이스는 커널에 격리된 네트워크 스택으로 자체 인터페이스, 라우트 및 방화벽 규칙을 지니고 있다. 컨테이너와 리눅스의 보안적인 측면으로, 컨테이너를 격리하는데 사용된다. 네트워킹 용어에서는 호스트 내부의 네트워크 제어와 데이터 플레인을 격리하는 VRF와 유사하다. 네트워크 네임 스페이스는 도커 네트워크를 통해 구성된 경우가 아니면 동일한 호스트의 두 컨테이너가 서로 통신하거나 호스트 자체와 통신할 수 없음을 보장한다. 일반적으로 CNM 네트워크 드라이버는 각 컨테이너에 대해 별도의 네임스페이스를 구현한다. 그러나 컨테이너는 동일한 네트워크 네임스페이스를 공유할 수도 있고 호스트의 네트워크 네임스페이스의 일부가 될 수도 있다. 호스트 네트워크 네임스페이스 컨테이너는 호스트 인터페이스와 호스트 라우팅 테이블이다. 이 네트워크 네임스페이스를 글로벌 네트워크 네임스페이스라고 한다.
가상 이더넷 디바이스
가상 이더넷 디바이스 (virtual ethernet device) 또는 veth는 두 네트워크 네임스페이스 사이의 연결선으로 동작하는 리눅스 네트워킹 인터페이스이다. veth는 각 네임스페이스에 단일 인터페이스가 있는 전이중 링크(full duplex link)이다. 한 인터페이스의 트래픽은 다른 인터페이스로 전달된다. 도커 네트워크를 만들 때 도커 네트워크 드라이버는 veth를 사용하여 네임스페이스간에 명시적인 연결을 제공한다. 컨테이너가 도커 네트워크에 연결되면 veth의 한쪽 끝은 컨테이너 내부에 배치되며 (일반적으로 ethX 인터페이스로 표시됨), 다른 쪽은 도커 네트워크에 연결된다.
iptables
iptables는 네이티브 패킷 필터링 시스템으로 버전 2.4 이후 리눅스 커널의 일부였다. 이는 패킷 마킹, 매스쿼레이딩(masquerading) 및 드라핑(dropping)에 대한 룰체인을 제공하는 기능이 풍부한 L3/L4 방화벽이다. 네이티브 도커 네트워크 드라이버는 iptables를 광범위하게 활용하여 네트워크 트래픽을 세분화하고, 호스트 포트 매핑을 제공하며, 로드 밸런싱 결정을 위해 트래픽을 마킹한다. (역자: What is IP masquerading and when is it of use?)
도커 네트워크 컨트롤 플레인
도커 분산형 네트워크 제어 플레인은 컨트롤 플레인 데이터를 전파하는 것 외에 Swarm 스코프 도커 네트워크의 상태를 관리한다. 도커 Swarm 클러스터의 내장 기능으로 외부 KV 저장소와 같은 추가 구성 요소가 필요하지 않다. 컨트롤 플레인에서는 SWIM에 기반한 가십 프로토콜을 사용하여 도커 컨테이너 클러스터에 네트워크 상태 정보와 토폴로지를 전파한다. 가십 프로토콜은 대규모 클러스터에서 메시지 크기, 오류 감지 시간 및 컨버전스 시간을 일정하게 유지하면서 클러스터 내에서 결과적 일관성(eventual consistency)을 달성하는 데 매우 효율적이다. 이는 네트워크가 느린 컨버전스 또는 잘못된 긍정 노드 오류와 같은 확장 문제를 일으키지 않고 네트워크가 여러 노도로 확장되게 한다.
컨트롤 플레인은 암호화된 채널을 통해 기밀성, 무결성 및 인증을 제공하며 매우 안전하다. 또한 네트워크 마다 범위가 지정되어 있어 주어진 호스트에서 수신하는 업데이트를 크게 감소시킨다.

대규모 네트워크 전반에 걸쳐 빠른 컨버전스를 달성하기 위해서 함께 동작하는 몇 가지 컴포넌트로 구성되어 있다. 컨트롤 플레인의 분산 특성은 클러스터 컨트롤러 장애가 네트워크 성능에 영향을 미치지 않도록 보장한다.
도커 네트워크 컨트롤 플레인의 컴포넌트는 다음과 같다.
- 메세지 확산 (Message Dissemination)은 각 교환의 정보가 보다 큰 노드 그룹으로 확장되는 P2P 방식으로 노드를 업데이트한다. 피어 그룹의 고정된 간격과 크기는 클러스터의 크기가 확장되는 경우에도 네트워크 사용량을 일정하게 한다. 피어 간의 기하급수적인 정보 전파는 신속하고 모든 클러스터 크기에 연결되게 한다.
- 장애 탐지 (Failure Detection)는 네트워크 정체와 긍정 노드(false posivive node) 장애를 유발하는 특정 경로를 배제시키기 위해 직접 및 간접 hello 메시지를 사용한다.
- 전체 상태 동기화 (Full State Syncs)는 일관성(consistency)을 신속하게 구성하고, 네트워크 파티션을 해결하기 위해 주기적으로 발생한다.
- 토폴로지 인식 (Topology Aware) 알고리즘은 자신과 다른 피어 간의 상대적인 대기 시간을 이해한다. 이것은 컨버전스를 보다 빠르고 효율적으로 만드는 피어 그룹을 최적화하는 데 사용된다.
- Control Plane Encryption (Control Plane Encryption)은 네트워크 보안을 손상시킬 수 있는 중간자 공격(man in the middle) 및 다른 공격에서 보호한다.
도커 네트워크 컨트롤 플레인은 Swarm의 구성 요소이며 Swarm 클러스터가 운영되어야 한다.
도커 호스트 네트워크 드라이버
host 네트워크 드라이버는 도커 없이 리눅스가 사용하는 것과 동일한 네트워킹 설정이기 때문에 도커가 처음인 사람들에게 가장 친숙한다. -net=host는 효과적으로 도커 네트워킹을 해제하고, 컨테이너는 호스트 운영체제의 호스트(또는 디폴트) 네트워킹 스택을 사용한다.
일반적으로 다른 네트워킹 드라이버의 경우, 각 컨테이너는 자체 네트워크 네임스페이스(또는 샌드박스)에 배치되어 서로 완전한 네트워크 격리를 제공한다. host 드라이버 컨테이너는 모두 동일한 호스트 네트워크 네임스페이스에 있으며 호스트의 네트워크 인터페이스와 IP 스택을 사용한다. 호스트 네트워크의 모든 컨테이너는 호스트 인터페이스에서 서로 통신할 수 있다. 네트워킹 관점에서 이는 컨테이너 없이 호스트에서 실행되는 여러 프로세스와 동일하다. 이들이 동일한 호스트 인터페이스를 사용하고 있기 때문에, 두 컨테이너가 똑같은 TCP 포트에 바인딩할 수 없다. 같은 호스트에서 여러 컨테이너를 스케줄링하는 경우, 포트 경합이 발생할 수 있다.

#호스트 네트워크에 컨테이너를 생성함
$ docker run -itd --net host --name C1 alpine sh
$ docker run -itd --net host --name nginx
#호스트 eth0 표시
$ ip add | grep eth0
2: eth0: <BROADCAST, MULTICAST, UP, LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
inet 172.31.21.213/20 brd 172.31.31.255 scope global eth0
#C1으로부터 eth0 표시
$ docker run -it --net host --name C1 alpine ip add | grep eth0
2: eth0: <BROADCAST, MULTICAST, UP, LOWER_UP> mtu 9001 qdisc mq state UP qlen 1000
inet 172.31.21.213/20 brd 172.31.31.255 scope global eth0
#C1의 locahost를 통해 nginx 컨테이너에 연결
$ curl localhost
!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
이 예제에서, 컨테이너가 host 네트워크를 사용할 때 호스트, C1 및 nginx는 모두 eth0에 대해 동일한 인터페이스를 공유한다. 이는 host를 멀티 테넌트(Multi-tenant) 또는 보안 수준이 높은 애플리케이션에 적합하지 않게 만든다. host 컨테이너는 호스트의 다른 모든 컨테이너에 네트워크 액세스 권한을 가진다. C1에서 curl nginx를 실행할 때 예제와 같이 localhost를 사용하여 컨테이너 간에 통신이 가능하다.
host 드라이버를 사용하는 경우, 도커는 포트 매핑 또는 라우팅 규칙과 같은 컨테이너 네트워킹 스택의 어떤 부분도 관리하지 않는다. 이것은 -p와 --icc와 같은 일반적인 네트워킹 플래그가 호스트 드라이버에 아무런 의미가 없다는 것을 의미한다. 이들은 무시된다. 이는 host 네트워킹을 네트워킹 드라이버 중에서 가장 간단하게 그리고 가장 낮은 지연 시간(latency)을 갖게 한다. 트래픽 경로는 컨테이너 프로세스에서 호스트 인터페이스로 직접 이동하며, 컨테이너화되지 않은 프로세스와 동등한 베어메탈 성능을 제공한다.
전체 호스트 액세스 및 부재한 자동화된 정책의 관리 방식들은 host 드라이버를 일반 네트워크 드라이버로 사용하기에 적합하지 않을 수 있다. 그러나, host 초고성능 애플리케이션 또는 애플리케이션 트러블슈팅과 같은 유즈케이스에 적용할 수 있는 몇 가지 흥미로운 속성을 가지고 있다.
도커 브리지 네트워크 드라이버
이 섹션에서는 기본 도커 브리지 네트워크와 사용자 정의 브리지 네트워크를 설명한다.
기본 도커 브리지 네트워크
도커 엔진을 실행하는 호스트에는 기본적으로 bridge 라는 로컬 도커 네트워크가 있다. 이 네트워크는 docker0 이라 불리는 리눅스 브리지를 인스턴스화하는 bridge 네트워크 드라이버를 사용하여 생성된다. 이는 혼란스럽게 들릴지도 모른다.
- bridge는 도커 네트워크의 이름이다.
- brdige는 이 네트워크가 생성되는 네트워크 드라이버 또는 템플릿이다.
- docker0은 이 네트워크를 구현하는데 사용되는 커널 빌딩 블록인 리눅스 브리지의 이름이다.
독립 실행형 도커 호스트에서, bridge는 다른 네트워크가 지정되지 않은 경우 컨테이너가 연결되는 기본 네트워크다. 다음 예에서 컨테이너는 네트워크 매개변수 없이 생성된다. 도커 엔진은 기본적으로 이를 브리지 네트워크에 연결한다. 컨테이너 내부 eth0을 주목하라. 이는 bridge 드라이버에 의해 생성되고 도커 네이티브 IPAM 드라이버에 의해 주소가 지정된다.
#"c1"이라는 이름의 busybox 컨테이너를 만들고 해당 IP 주소를 표시
host $ docker run -it --name c1 busybox sh
c1 # ip 주소
4: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
...
컨테이너 인터페이스의 MAC 주소는 동적으로 생성되고 충돌을 피하기 위해 IP 주소를 포함한다. 여기서
ac:11:00:02는 172.17.0.2에 해당한다.
호스트의 brctl 툴은 호스트 네트워크 네임 스페이스에 존재하는 리눅스 브리지를 표시한다. docker0이라 부르는 단일 브리지가 표시된다. docker0에는 하나의 인터페이스 vetha3788c4가 있는데, 이 인터페이스는 브리지에서 컨테이너 c1 내부의 eth0 인터페이스에 대한 연결을 제공한다.
host $ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242504b5200 no vethb64e8b8
컨테이너 c1 내부의 컨테이너 라우팅 테이블은 컨테이너의 eth0로 트래픽을 전달하고, 따라서 docker0 브리지로 이동한다.
c1# ip 라우트
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 src 172.17.0.2
컨테이너는 연결되는 네트워크 수에 따라 0개에서 다수의 인터페이스를 가질 수 있다. 각 도커 네트워크는 컨테이너 마다 하나의 인터페이스만 가질 수 있다.

호스트 라우팅 테이블이 보여주는 것처럼, 글로벌 네트워크 네임스페이스의 IP 인터페이스는 이제 docker0을 포함한다. 호스트 라우팅 테이블은 외부 네트워크에서 doker0과 eth0 사이의 연결시켜 컨테이너 내부에서 외부 네트워크로의 경로를 완성한다.
host $ ip route
default via 172.31.16.1 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.42.1
172.31.16.0/20 dev eth0 proto kernel scope link src 172.31.16.102
기본적으로 bridge는 기존 호스트 인터페이스와 겹치지 않는 172.[17-31].0.0/16 또는 192.168.[0-240].0/20 범위에서 서브넷 한 개가 할당된다. 또한 기본 bridge 네트워크는 사용자 제공 주소 범위를 사용하도록 구성할 수 있다. 또한 도커가 생성하는 대신 기존 Linux 브리지가 bridge 네트워크에 사용될 수 있다.
bridge 사용자 정의에 대한 자세한 내용은 도커 엔진 문서를 참조하라.
기본
bridge네트워크는 레거시 링크를 지원하는 유일한 네트워크다. 이름 기반 서비스 검색 (Name-based service discovery) 및 사용자 제공 IP 주소는 기본bridge네트워크에 의해 지원되지 않는다.
사용자 정의 브리지 네트워크
기본 네트워크 외에도, 사용자들은 모든 네트워크 드라이버 유형의 사용자 정의 네트워크 (user-defined-network) 라고 불리는 네트워크를 만들 수 있다. 사용자 정의 bridge 네트워크의 경우 호스트에 새 리눅스 브리지를 설정한다. 기본 bridge 네트워크와 달리, 사용자 정의 네트워크는 수동 IP 주소와 서브넷 할당을 지원한다. 할당이 지정되지 않은 경우에는, 도커의 기본 IPAM 드라이버가 프라이빗 IP 공간에서 사용할 수 있는 다음 서브넷을 할당한다.

사용자 정의 bridge 네트워크 아래에는 2개의 컨테이너가 연결되어 있다. 서브넷이 지정되고, 네트워크는 my_bridge로 이름이 붙여진다. 하나의 컨테이너에는 IP 매개변수가 제공되지 않으므로, IPAM 드라이버는 서브넷에 사용 가능한 다음 IP를 할당한다. 다른 컨테이너에는 IP가 지정되어 있다.
$ docker network create -d bridge --subnet 10.0.0.0/24 my_bridge
$ docker run -itd --name c2 --net my_bridge busybox sh
$ docker run -itd --name c3 --net my_bridge --ip 10.0.0.254 busybox sh
brctl은 이제 호스트에 두번째 리눅스 bridge를 나타낸다. 리눅스 브리지의 이름인 br-4bcc22f5e5b9는 my_bridge 네트워크의 네트워크 ID와 일치한다. my_bridge는 또한 컨테이너 c2와 c3에 연결된 2개의 veth 인터페이스가 있다.
$ brctl show
bridge name bridge id STP enabled interfaces
br-b5db4578d8c9 8000.02428d936bb1 no vethc9b3282
vethf3ba8b5
docker0 8000.0242504b5200 no vethb64e8b8
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
b5db4578d8c9 my_bridge bridge local
e1cac9da3116 bridge bridge local
...
글로벌 네트워크 네임스페이스 인터페이스 목록은 도커 엔진에 의해 인스턴스화된 리눅스 네트워킹 서킷을 보여준다. 각 veth 및 리눅스 브리지 인터페이스는 리눅스 브리지 중 하나와 컨테이너 네트워크 네임스페이스 사이의 링크로 나타난다.
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
5: vethb64e8b8@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
6: br-b5db4578d8c9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
8: vethc9b3282@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
10: vethf3ba8b5@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
...
독립 실행형 컨테이너의 외부 접근
기본적으로 동일한 도커 네트워크의 모든 컨테이너 (멀티 호스트 swarm 스코프 또는 local 스코프)는 모든 포트에서 서로 연결된다. 서로 다른 도커 네트워크와 외부 도커에서 발생하는 컨테이너 인그레스 트래픽 간의 통신은 방화벽으로 보호된다. 이는 컨테이너 애플리케이션을 외부 세계 및 서로에게서 보호하는 기본적인 보안 측면이다. 자세한 내용은 네트워크 보안을 참조하라.
대부분 유형의 도커 네트워크(brdige와 overlay 포함)의 경우 애플리케이션을 위한 외부 인그레스 액세스를 명시적으로 부여해야 한다. 이는 내부 포트 매핑을 통해 이루어진다. 도커는 내부 컨테이너 인터페이스에 호스트 인터페이스에 노출된 포트를 퍼블리싱한다. 다음 다이어그램은 컨테이너 C2로의 인그레스(하향 화살표) 및 엔그레스(상단 화살표) 트래픽을 나타낸다. 아웃바운드(엔그레스) 컨테이너 트래픽은 기본적으로 허용된다. 컨테이너에 의해 시작된 엔그레스 연결은 임시 포트(일반적으로 32768 - 60999 범위)에 마스커레이딩되거나 SNAT된다. 이 연결에 대한 반송 트래픽(return traffic)이 허용되므로 컨테이너는 임시 포트에서 호스트에 라우팅할 수 있는 최상의 IP 주소를 사용한다.
인그레스 액세스는 명시적인 포트 퍼블리싱을 통해 제공된다. 포트 퍼블리싱은 도커 엔진에 의해 수행되며 UCP 또는 엔진 CLI를 통해 제어할 수 있다. 서비스나 컨테이너를 노출하도록 특정 또는 무작위로 선택된 포트를 구성할 수 있다. 포트는 특정(또는 모든) 호스트 인터페이스에서 수신 대기하도록 설정할 수 있으며, 모든 트래픽은 이 포트에서 포트 및 컨테이너 내부의 인터페이스로 매핑된다.
$ docker run -d --name C2 --net my_bridge -p 5000:80 nginx

외부 액세스는 도커 CLI 또는 UCP에서 --publish/-p를 사용하여 설정되며, 위의 명령을 실행한 후 다이어그램은 컨테이너 C2가 my_bridge 네트워크에 연결되고 IP 주소가 10.0.0.2인 것으로 표시된다. 컨테이너는 192.168.0.2의 호스트 인터페이스의 포트 5000에서 외부 세계에 서비스를 알린다. 이 인터페이스:포트로 전송되는 모든 트래픽은 컨테이너 인터페이스의 10.0.2:80에 퍼블리싱된 포트다.
컨테이너에 의해 시작된 아웃바운드 트래픽은 호스트 인터페이스 192.168.0.2의 사용 후 삭제 포트 32768에서 소싱되도록 마스커레이딩된다. 반송 트래픽(return traffic)은 목적지와 동일한 IP 주소와 포트를 사용하며 내부적으로 다시 컨테이너 주소:포트 10.0.2:33920로 마스커레이딩된다. 포트 게시를 사용할 때, 네트워크의 외부 트래픽은 항상 호스트 IP와 노출된 포트를 사용하며 컨테이너 IP와 내부 포트는 사용하지 않는다.
도커 엔진의 클러스터에 컨테이너와 서비스를 노출하는 방법에 대한 자세한 내용은 Swarm 서비스 외부 액세스를 참조하라.
오버레이 드라이버 네트워크 아키텍처
네이티브 도커 overlay 네트워크 드라이버는 멀티 호스트 네트워킹의 여러가지 문제를 근본적으로 단순화한다. overlay 드라이버를 사용하면, 멀티 호스트 네트워크가 외부 프로비저닝이나 컴포넌트 없이 도커 내부의 일급 시민이다. overlay는 swarm 분산 컨트롤 플레인을 사용하여 대규모 클러스터에 걸쳐 중앙 집중식 관리, 안정성 및 보안을 제공한다.
VXLAN 데이터 플레인
overlay 드라이버는 기본 물리적 네트워크(언더레이)와 컨테이너 네트워크를 분리하는 업계 표준 VXLAN 데이터 플레인을 활용한다. 도커 오버레이 네트워크는 컨테이너 트래픽을 VXLAN 헤더에 컨테이너 트래픽을 캡슐화하여 물리적 Layer 2 또는 Layer 3 네트워크를 통과할 수 있도록 한다. 오버레이를 사용하면 기본 물리적 토폴로지에 상관없이 네트워크 분할을 동적으로 제어하기 쉽다. 표준 IETF VXLAN 헤더를 사용해서 네트워크 트래픽을 검사하고 분석하기 위한 표준 툴링을 꾀할 수 있다.
VXLAN은 버전 3.7부터 리눅스 커널의 일부였으며, 도커는 커널의 기본 VXLAN 기능을 사용하여 오버레이 네트워크를 생성한다. 도커 오버레이 데이터패스는 전적으로 커널 공간에 있다. 따라서 컨텍스트 스위치가 줄어들고 CPU 오버헤드가 감소하며, 대기 시간이 짧고, 애플리케이션과 물리적 NIC 간의 직접적인 트래픽 경로가 생긴다.
IETF VXLAN(RFC 7348)은 Layer 3 네트워크에서 Layer 2 세그먼트를 오버레이하는 데이터 계층 캡슐화 형식이다. VXLAN은 표준 IP 네트워크에서 사용하도록 설계되었으며 공유된 물리적 네트워크 인프라에서 대규모 멀티 테넌트(Multi-tenant) 설계를 지원할 수 있다. 기존 사내 및 클라우드 기반 네트워크는 VXLAN을 투명하게 지원할 수 있다.
VXLAN은 언더레이 IP/UDP 헤더 내에 컨테이너 Layer 2 프레임을 배치하는 MAC-in-UDP 캡슐화로 정의된다. 언더레이 IP/UDP 헤더는 언더레이 네트워크의 호스트 간의 전송을 제공한다. 오버레이는 지정된 오버레이 네트워크에 참여하는 각 호스트 간에 점 대 다중점 연결로 존재하는 상태 비저장 VXLAN 터널이다. 오버레이는 언더레이 토폴로지와 독립적이기 때문에 애플리케이션이 더 쉽게 이동할 수 있다. 따라서, 네트워크 정책 및 연결성은 온프레미스, 개발자 데스크탑, 또는 퍼블릭 클라우드에 관계없이 애플리케이션과 함께 전송될 수 있다.

이 다이어그램에서 오버레이 네트워크의 패킷 흐름이 표시된다. 다음은 c1이 공유 오버레이 네트워크에서 c2 패킷을 전송할 때 수행되는 단계이다.
- c1은 c2에 대해 DNS 조회를 한다. 두 컨테이너가 동일한 오버레이 네트워크에 있으므로 도커 엔진 로컬 DNS 서버는 c2를 오버레이 IP 주소 10.0.0.3으로 확인한다.
- 오버레이 네트워크는 L2 세그먼트이므로 c1은 c2의 MAC 주소로 지정된 L2 프레임을 생성한다.
- 프레임은 overlay 네트워크 드라이버에 의해 VXLAN 헤더로 캡슐화된다. 분산 오버레이 컨트롤 플레인은 각 VXLAN 터널 엔드포인트의 위치와 상태를 관리하므로 c2가 192.168.0.3의 물리적 주소에 있는 host-B에 있다는 것을 알고 있다. 이 주소는 언더레이 IP 헤더의 대상 주소가 된다.
- 일단 캡슐화되면 패킷이 전송된다. 물리적 네트워크는 VXLAN 패킷을 올바른 호스트로 라우팅하거나 브리징하는 역할을 한다.
- 패킷은 host-B의 eth0 인터페이스에 도착하며 overlay 네트워크 드라이버에 의해 캡슐 해제된다. c1의 원래 L2 프레임은 c2의 eth0 인터페이스와 수신 대기중인 애플리케이션까지 전달된다.
오버레이 드라이버 내부 아키텍처
도커 Swarm 컨트롤 플레인은 오버레이 네트워크에 대한 모든 프로비저닝을 자동화한다. VXLAN 설정 또는 리눅스 네트워킹 설정은 필요없다. 오버레이의 옵션 기능인 데이터 플레인 암호화도 네트워크가 생성될 때 오버레이 드라이버에 의해 자동으로 설정된다. 사용자 또는 네트워크 운영자는 네트워크를 정의하고 (docker network create -d overlay ...) 컨테이너를 해당 네트워크에 연결하기만 하면 된다.

오버레이 네트워크 생성 중에 도커 엔진은 각 호스트에 오버레이에 필요한 네트워크 인프라를 만든다. 리눅스 브리지는 연결된 VXLAN 인터페이스와 함께 오버레이별로 생성된다. 도커 엔진은 해당 네트워크에 연결된 컨테이너가 호스트에 예약되어 있을 때만 호스트의 오버레이 네트워크를 지능적으로 인스턴스화한다. 이렇게 하면 연결된 컨테이너가 없는 오버레이 네트워크의 무질서한 확산을 방지할 수 있다.
다음 예제는 오버레이 네트워크를 생성하고 그 네트워크에 컨테이너를 연결한다. 도커 Swarm/UCP는 자동으로 오버레이 네트워크를 생성한다. 다음 예제는 Swarm 또는 UCP를 미리 설정해야 한다.
#오버레이 드라이버로 "ovnet"이라는 이름의 오버레이 생성
$ docker network create -d overlay --subnet 10.1.0.0/24 ovnet
#nginx 이미지에서 서비스를 생성하여 "ovnet" 오버레이 네트워크에 연결
$ docker service create --network ovnet nginx
오버레이 네트워크가 생성되면 호스트 내부에 여러 개의 인터페이스와 브리지가 생성되고, 이 컨테이너 내부에 두 개의 인터페이스도 생성된다는 점에 주목해야 한다.
#이 서비스의 컨테이너를 들여다 보면 내부 인터페이스를 볼 수 있다
conatiner$ ip address
#docker_gwbridge 네트워크
52: eth0@if55: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
link/ether 02:42:ac:14:00:06 brd ff:ff:ff:ff:ff:ff
inet 172.20.0.6/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe14:6/64 scope link
valid_lft forever preferred_lft forever
#오버레이 네트워크 인터페이스
54: eth1@if53: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450
link/ether 02:42:0a:01:00:03 brd ff:ff:ff:ff:ff:ff
inet 10.1.0.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet 10.1.0.2/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe01:3/64 scope link
valid_lft forever preferred_lft forever
현재 호스트에 있는 두 개의 브리지에 해당하는 컨테이너 내부에 두 개의 인터페이스가 생성되었다. 오버레이 네트워크에서, 각 컨테이너에는 overlay와 docker_gwbridge를 각각 연결하는 최소한 두 개의 인터페이스가 있다.
| 브리지 | 목적 |
|---|---|
| overlay | 오버레이 네트워크로의 인그레스 및 엔그레스는 VXLAN이 캡슐화하고 (선택적으로) 동일한 오버레이 네트워크의 컨테이너 간에 전송되는 트래픽을 암호화함. 이 특정 오버레이에 참여하는 모든 호스트에 걸쳐 오버레이를 확장함. 호스트의 오버레이 서브넷당 하나씩 존재하며 지정된 특정 오버레이 네트워크 이름과 동일한 이름을 가지고 있음. |
| docker_gwbridge | 클러스터에서 나가는 트래픽에 대한 엔그레스 브리지. 호스트당 하나의 docker_gwbridgege 만 존재. 이 브리지의 컨테이너 대 컨테이너 트래픽은 인그레스/엔그레스 트래픽 플로우만 허용함. |
도커 오버레이 드라이버는 도커 엔진 1.9 이후 존재해왔으며, 네트워크 상태를 관리하기 위해 외부 K/V 스토어가 필요했다. 도커 엔진 1.12는 더 이상 외부 저장소가 필요하지 않도록 컨트롤 플레인 스테이트를 도커 엔진에 통합했다. 또한 1.12는 암호화와 서비스 로드 밸런싱을 포함한 몇 가지 새로운 기능을 도입했다. 도입된 네트워킹 기능은 이러한 기능을 지원하는 도커 엔진 버전이 필요하며, 이러한 기능을 이전 버전의 도커 엔진과 함께 사용하는 것은 지원하지 않는다.
도커 서비스를 위한 외부 액세스
Swarm & UCP는 클러스터 포트 퍼블리싱 외부에서 서비스에 액세스한다. 서비스의 인그레스 및 엔그레스는 중앙 집중식 게이트웨이에 의존하지 않고 특정 서비스 태스크가 실행 중인 호스트에 인그레스/엔그레스가 분산된다. 서비스를 위한 포트 퍼블리싱에는 host 모드와 ingress 모드라는 두 가지 모드가 있다.
인그레스 모드 서비스 퍼블리싱
ingress 모드 포트 퍼블리싱은 Swarm Routing Mesh를 사용하여 서비스 태스크 간에 로드 밸런싱을 적용한다. 인그레스 모드는 모든 UCP/Swarm 노드에 노출된 포트를 퍼블리싱한다. 퍼블리시된 포트로 들어오는 트래픽은 라우팅 메쉬에 의해 로드 밸런싱되고 라운드 로빈 로드 밸런싱을 통해 서비스의 정상적인 태스크 중 하나로 이동된다. 특정 호스트가 서비스 태스크를 실행하고 있지 않더라도 이 포트는 호스트에 퍼블리시되고 태스크가 있는 호스트에 로드 밸런싱된다.
$ docker service create --replicas 2 --publish mode=ingress,target=80,published=8080 nginx
mode=ingress는 서비스의 기본 모드다. 이 명령은 축약 버전-p 80:8080으로도 가능하다. 포트8080은 클러스터의 모든 호스트에 노출되며, 이 서비스에서는 두 컨테이너에 대한 로드 밸런성이 이루어진다.
호스트 모드 서비스 퍼블리싱
host 모드 포트 퍼블리싱은 특정 서비스 태스크가 실행 중인 호스트의 포트만 노출한다. 포트는 해당 호스트의 컨테이너에 직접 매핑된다. 포트 충돌을 방지하기 위해 각 호스트에서 특정 서비스의 단일 태스크만 실행할 수 있다.
$ docker service create --replicas 2 --publish mode=host,target=80,published=8080 nginx
host모드는mode=host플래그가 필요하다. 이 두 컨테이너가 실행 중인 호스트에 포트8080을 로컬로 퍼블리싱한다. 로드 밸런싱은 적용하지 않으므로, 해당 노드에 대한 트래픽은 로컬 컨테이너에만 전달된다. 복제본 수에 사용할 수 있는 포트가 충분하지 않은 경우, 포트 충돌이 발생할 수 있다.
인그레스 설계
두 가지 퍼블리싱 모드 중 하나를 위한 좋은 유즈케이스가 많이 있다. ingress 모드는 여러 복제본이 있고, 해당 복제본 간에 로드 밸런싱이 필요한 서비스에 잘 작동한다. host 모드는 다른 툴에 의해 외부 서비스 검색이 이미 제공되어 있는 경우 잘 작동한다. 호스트 모드의 또 다른 좋은 유즈케이스는 호스트별로 한 번씩 존재하는 글로벌 컨테이너이다. 이러한 컨테이너는 해당 호스트에만 관련이 있고 그 서비스에 액세스할 때 로드 밸런싱을 원하지 않는 로컬 호스트에 대한 특정 정보(예: 모니터링 또는 로깅)를 노출할 수도 있다.

MACVLAN
macvlan 드라이버는 실제로 새로 구현된 진정한 네트워크 가상화 기술이다. 리눅스 구현은 매우 가볍다. 왜나하면 격리를 위해 리눅스 브리지를 사용하는 대신, 네트워크 격리와 물리적 네트워크 연결성을 강제하기 위해 리눅스 이더넷 인터페이스 또는 하위 인터페이스와 간단히 연결되기 때문이다.
MACVLAN은 여러 가지 고유한 특징과 기능을 제공한다. 매우 단순하고 가벼운 아키텍처 덕택에 성능에 긍정적인 영향을 미친다. MACVLAN 드라이버는 포트 매핑 대신 컨테이너와 물리적 네트워크 간에 직접적으로 액세스한다. 또한 컨테이너는 물리적 네트워크의 서브넷에 있는 라우팅 가능한 IP 주소를 수신할 수 있다.
MACVLAN 유즈케이스는 다음을 포함할 수 있다.
- 대기 시간이 매우 짧은 애플리케이션
- 컨테이너가 외부 호스트 네트워크와 동일한 서브넷에 있고 IP를 외부 네트워크 호스트로 사용해야 하는 네트워크의 설계
macvlan 드라이버는 부모 인터페이스의 개념을 사용한다. 이 인터페이스는 eth0과 같은 물리적인 인터페이스, eth0.10 (VLAN 10을 나타내는 .10)과 같은 802.1q VLAN 태깅을 위한 하위 인터페이스, 또는 두 이더넷 인터페이스를 단일 논리적 인터페이스에 결합하는 본드 호스트 어댑터와 같은 물리적 인터페이스일 수도 있다.
MACVLAN 네트워크를 구성할 때, 게이트웨이 주소가 필요하다. 게이트웨이는 네트워크 인프라에서 제공하는 호스트 외부에 있어야 한다. MACVLAN 네트워크는 동일한 네트워크에 있는 컨테이너 간의 액세스를 허용한다. 동일한 호스트의 다른 MACVLAN 네트워크 간 액세스는 호스트 외부로 라우팅하지 않으면 불가능하다.

이 예제는 호스트의 eth0에 MACVLAN 네트워크를 바인딩한다. 또한 두 개의 컨테이너를 mvnet MACVLAN 네트워크에 연결하고 그들 사이에서 핑(ping)할 수 있다는 것을 보여준다. 각 컨테이너는 물리적 네트워크 서브넷 192.168.0.0/24에 주소가 있고, 기본 게이트웨이는 물리적 네트워크의 인터페이스이다.
#호스트의 eth0에 바인딩된 MACVLAN 네트워크 "mvnet"생성
$ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 mvnet
#"mvnet"네트워크에 컨테이너 생성
$ docker run -itd --name c1 --net mvnet --ip 192.168.0.3 busybox sh
$ docker run -it --name c2 --net mvnet --ip 192.168.0.4 busybox sh
# 192.168.0.3 ping
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.052 ms
이 다이어그램에서 볼 수 있듯이, c1과 c2는 호스트의 eth0에 연결된 macvlan 이라는 MACVLAN 네트워크를 통해 연결된다.
MACVLAN을 사용한 VLAN 트렁킹
리눅스 호스트에 802.1q를 트렁킹하는 것은 운영에 있어 많은 이들에게 악명높을 정도로 고통스럽다. 재부팅에도 지속되려면 설정 파일을 변경해야 한다. 브리지가 관련되어 있으면, 물리적 NIC를 브리지로 옮기고 그 브리지가 IP 주소를 얻어와야 한다. macvlan 드라이버는 생성, 파괴 및 호스트 재부팅을 통해 MACVLAN 네트워크의 하위 인터페이스와 기타 컴포넌트를 완벽하게 관리한다.

macvlan 드라이버가 하위 인터페이스로 인스턴스화되면 호스트와 L2의 세그먼트 컨테이너에 대한 VLAN 트렁킹할 수 있다. macvlan 드라이버는 자동으로 하위 인터페이스를 만들고, 이를 컨테이너 인터페이스에 연결한다. 그 결과, 각 컨테이너는 다른 VLAN에 있으며 트래픽이 물리적 네트워크에서 라우팅되지 않는 한, 컨테이너 간의 통신은 불가능하다.
#VLAN 10에 macvlan10 네트워크 생성
$ docker network create -d macvlan --subnet 192.168.10.0/24 --gateway 192.168.10.1 -o parent=eth0.10 macvlan10
#VLAN 20에 macvlan20 네트워크 생성
$ docker network create -d macvlan --subnet 192.168.20.0/24 --gateway 192.168.20.1 -o parent=eth0.20 macvlan20
#별도의 MACVLAN 네트워크에서 컨테이너 생성
$ docker run -itd --name c1--net macvlan10 --ip 192.168.10.2 busybox sh
$ docker run -it --name c2--net macvlan20 --ip 192.168.20.2 busybox sh
앞선 설정에서 하위 인터페이스를 상위 인터페이스로 사용하도록 설정된 macvlan 드라이버를 사용하여 두 개의 개별 네트워크를 생성했다. macvlan 드라이버는 하위 인터페이스를 생성하고 이를 호스트의 eth0과 컨테이너 인터페이스 간에 연결한다. 호스트 인터페이스와 업스트림 스위치는 switchport mode trunk로 설정해 주어야 VLAN이 태그되어 인터페이스를 통과할 수 있다. 하나 또는 그 이상의 컨테이너를 지정된 MACVLAN 네트워크에 연결해서 L2를 통해 세그먼트화된 복잡한 네트워크 정책을 만들 수 있다.
여러 개의 MAC 주소가 단일 호스트 인터페이스 뒤에 있으므로, MAC 필터링의 NIC 지원에 따라 인터페이스에서 비규칙 모드(promiscuous mode)를 활성화해야할 수도 있다.
무지정(None, 격리용) 네트워크 드라이버
호스트 네트워크 드라이버와 마찬가지로 none 네트워크 드라이버는 기본적으로 관리되지 않는 네트워킹 옵션이다. 도커 엔진은 컨테이너 내부에 인터페이스를 만들거나, 포트 매핑을 설정하거나, 연결을 위한 경로를 설치하지 않는다. --net=none을 사용하는 컨테이너는 다른 컨테이너와 호스트로부터 완전히 격리된다. 네트워킹 관리자 또는 외부 툴이 이 배관을 제공해야 한다. none을 사용하는 컨테이너는 루프백 인터페이스만 있고 다른 인터페이스는 없다.
호스트 드라이버와 달리, none 드라이버는 각 컨테이너에 대해 구분된 네임스페이스를 생성하지 않는다. 이는 컨테이너와 호스트 사이의 컨테이너 네트워크를 확실하게 격리시킨다.
--net=none또는--net=host를 사용하는 컨테이너는 다른 도커 네트워크에 연결할 수 없다.
물리적 네트워크 설계 요구사항
도커 엔터프라즈 엔진 및 도커 네트워킹은 공통 데이터 센터 네트워크 인프라와 토폴로지에서 실행되도록 설계되었다. 중앙 집중식 컨트롤러와 무정지(fault-tolerance) 클러스터는 광범위한 네트워크 환경에서 호환성을 보장한다. 네트워킹 기능(네트워크 프로비저닝, MAC 학습, 오버레이 암호화)을 제공하는 컴포넌트는 도커 엔진, UCP 또는 리눅스 커널 자체의 일부이다. 네이티브 도커 네트워킹 드라이버를 실행하는 데 추가 컴포넌트나 특수 네트워킹 기능이 필요없다.
보다 구체적으로, 도커 네이티브 네트워크 드라이버는 다음에 대한 요구사항이 없다.
- 멀티캐스트
- 외부 키밸류 저장소
- 특정 라우팅 프로토콜
- 호스트 간의 Layer 2 종속성
- 스핀(spine) 및 리프(leaf), 전통적인 3티어 및 PoD 설계와 같은 특정 토폴로지. 이러한 토폴로지는 지원된다.
이는 모든 환경에서 애플리케이션 이식성을 향샹시키면서 애플리케이션에 필요한 성능 및 정책을 변함없이 획득하는 컨테이너 네트워킹 모델(CNM)과 일치한다.
Swarm 네이티브 서비스 검색
도커는 단일 도커 엔진에서 실행되는 컨테이너와 도커 Swarm에서 실행되는 task에 대한 서비스 검색을 제공하기 위해 내장된 DNS를 사용한다. 도커 엔진에는 사용자 정의 브리지, 오버레이 및 MACVLAN 네트워크의 호스트에 있는 모든 컨테이너에 이름 분석(name resolution)을 하는 내부 DNS 서버가 있다. 각 도커 컨테이너(또는 Swarm 모드의 task)에는 DNS 리졸버가 있어 DNS 쿼리를 DNS 서버 역할을 하는 도커 엔진에 전달한다. 그런 다음 도커 엔진은 DNS 쿼리가 요청 컨테이너가 속한 네트워크의 컨테이너 또는 service에 속하는지 여부를 확인한다. 이 경우 도커 엔진은 키밸류 저장소에서 컨테이너, task 또는 server의 이름과 일치하는 IP 주소를 찾아 해당 IP 또는 서비스 가상 IP(VIP)를 다시 요청자에게 반환한다.
서비스 검색은 네트워크 스코프화되며, 동일한 네트워크에 있는 컨테이너 또는 태스크만 내장형 DNS 기능을 사용할 수 있음을 의미한다. 같은 네트워크에 있지 않은 컨테이너는 서로의 주소를 확인할 수 없다. 덧붙여, 네트워크의 DNS 항목이 있는 특정 네트워크 저장소에 컨테이너 또는 태스크가 있는 노드만 사용할 수 있다. 이는 보안과 성능을 증진시킨다.
대상 컨테이너 또는 service가 소스 컨테이너와 동일한 네트워크에 있지 않는 경우, 도커 엔진은 기본 DNS 서버를 구성하기 위해 도커 쿼리를 전달한다.

이 예에서는 myservice라고 하는 두 개의 컨테이너 서비스가 있다. 두 번째 서비스(client)는 동일한 네트워크에 존재한다. 그 client는 docker.com과 myservice에 대해 두 번의 curl 태스크를 실행한다.
다음은 발생하게 되는 액션이다.
- docker.com 및 myservice에 대한 DNS 쿼리가 client에 의해 시작된다.
- 컨테이너의 내장형 리졸버는 127.0.11:53의 DNS 쿼리를 가로채 도커 엔진의 DNS 서버로 보낸다.
- 내 myservice는 개별 태스크 IP 주소로 내부 로드 밸런싱되는 해당 서비스의 가상 IP(VIP)로 식별된다. IP 주소에 직접 연결되더라도 컨테이너 이름은 마찬가지로 리졸브된다.
- docker.com은 mynet 네트워크에 서비스 이름으로 존재하지 않으므로 요청은 설정된 기본 DNS 서버로 전달된다.
도커 네이티브 로드 밸런싱
도커 Swarm 클러스터에는 엔진에 바로 내장된 내부 및 외부 로드 밸런싱 기능이 있다. 내부 로드 밸런싱은 동일한 Swarm 또는 UCP 클러스터 내의 컨테이너 간에 로드 밸런싱을 제공한다. 외부 로드 밸런싱은 클러스터로 들어오는 인그레스 트래픽의 로드 밸런싱을 제공한다.
UCP 내부 로드 밸런싱
도커 서비스가 만들어지면 내부 로드 밸런싱이 자동으로 인스턴스화된다. 서비스가 도커 Swarm 클러스터에서 생성되면 서비스 네트워크의 일부인 가상 IP(VIP)가 자동으로 할당된다. 서비스 이름을 확인하면 VIP가 반환된다. 해당 VIP에 대한 트래픽은 오버레이 네트워크를 통해 해당 서비스의 정상적인 모든 태스크로 자동 전송된다. 이 방법은 단일 IP만 클라이언트로 반환되기 때문에 클라이언트측 로드 밸런싱을 피할 수 있다. 도커는 라우팅을 처리하고 정상적인 서비스 태스크 전반에 트래픽을 균등하게 분배한다.

VIP를 보기 위해서는, 다음과 같이 docker service inspect my_service```
를 실행한다.
# mynet이라 부르는 오버레이 네트워크 생성
$ docker network create -d overlay mynet
a59umzkdj2r0ua7x8jxd84dhr
# 해당 네트워크의 일부로 2개의 복제본을 사용하여 myservice를 생성
$ docker service create --network mynet --name myservice --replicas 2 busybox ping localhost
8t5r8cr0f0h6k2c3k7ih4l6f5
# 해당 서비스에 대해 생성된 VIP 보기
$ docker service inspect myservice
...
"VirtualIPs": [
{
"NetworkID": "a59umzkdj2r0ua7x8jxd84dhr",
"Addr": "10.0.0.3/24"
},
]
DNS RR(DNS RR) 로드 밸런싱은 서비스에 대한 또 다른 로드 밸런싱 옵션이다(
--endpoint-mode로 구성). DNS RR 모드에서는 각 서비스에 대해 VIP가 만들어지지 않는다. Docker DNS 서버는 라운드 로빈 방식으로 개별 컨테이너 IP에 대한 서비스 이름을 확인한다.
UCP 외부 L4 로드 밸런싱 (도커 라우팅 메쉬)
서비스를 만들거나 업데이트할 때 --publish 플래그를 사용하여 서비스를 외부에 노출할 수 있다. 도커 Swarm 모드로 포트를 게시하는 것은 클러스터의 모든 노드가 해당 포트에서 수신 중임을 의미한다. 하지만 서비스 태스크가 해당 포트에서 수신 중인 노드에 있지 않으면 어떻게 될까?
이 지점에서 라우팅 메쉬가 작동한다. 라우팅 메쉬는 ipvs와 iptables를 결합하여 강력한 클러스터 전체 전송 계층(L4) 로드 밸런서를 만드는 Docker 1.12의 새로운 기능이다. 모든 Swarm 노드는 서비스의 퍼블리싱된 포트에 대한 연결을 허용할 수 있도록 한다. Swarm 노드가 실행 중인 service의 퍼블리싱된 TCP/UDP 포트로 향하는 트래픽을 수신할 때, ingress라는 사전 정의된 오버레이 네트워크를 사용하여 이를 서비스의 VIP로 전달한다. ingress 네트워크는 다른 오버레이 네트워크와 유사하게 동작하지만 유일한 목적은 외부 클라이언트에서 클러스터 서비스로 메쉬 라우팅 트래픽을 전송하는 것이다. 이전 섹션에서 설명한 것과 동일한 VIP 기반 내부 로드 밸런싱을 사용한다.
서비스를 시작하면 애플리케이션에 대한 외부 DNS 레코드를 만들어 모든 도커 Swarm 노드 중 일부 또는 전부에 매핑할 수 있다. 클러스터의 모든 노드가 라우팅 메쉬 라우팅 기능이 있는 노드처럼 보이므로 컨테이너가 실행되는 위치에 대해 걱정할 필요가 없다.
# 2개의 복제본을 사용하여 서비스를 생성하고 클러스터에 포트 8000을 내보내기
$ docker service create --name app --replicas 2 --network appnet -p 8000:80 nginx

이 다이어그램은 라우팅 메쉬가 어떻게 작동하는지 보여준다.
- 서비스는 두 개의 복제본으로 만들어지며 포트 8000에 외부적으로 매핑된다.
- 라우팅 메쉬는 클러스터의 각 호스트에 있는 포트 8000을 노출한다.
- app으로 향하는 트래픽은 모든 호스트에서 들어갈 수 있다. 이 경우 외부 LB는 서비스 복제본이 없이 호스트에 트래픽을 전송한다.
- 커널의 IPVS 로드 밸런서는 ingress 오버레이 네트워크의 트래픽을 정상적인 서비스 복제본으로 리디렉션한다.
UCP 외부 L7 로드 밸런싱 (HTTP 라우팅 메쉬)
UCP는 HTTP 라우팅 메쉬를 통해 L7 HTTP/HTTPS 로드 밸런싱을 제공한다. URL은 서비스에 로드 밸런싱될 수 있고 서비스 복제본에 걸쳐 로드 밸런싱될 수 있다.

UCP 로드 밸런싱 참조 아키텍처로 가서 UCP L7 LB 설계에 대해 좀 더 살펴보라.
도커 네트워크 보안 및 암호화
도커를 사용하여 컨테이너형 워크로드를 설계하고 구현할 때 네트워크 보안은 최우선 고려사항이다. 이 섹션에서는 도커 네트워크를 배포할 때 고려해야할 핵심 보안사항을 다룬다.
네트워크 세분화(Segmentation) 그리고 데이터 플레인 보안
도커는 도커 네트워크를 세분화하고 컨테이너 리소스에 대한 악의적인 액세스를 방지하기 위해 분산 방화벽 규칙을 관리한다. 기본적으로 도커 네트워크는 트래픽을 차단하기 위해 서로 세분화되어 있다. 이 접근방식은 Layer 3에서 진정한 네트워크 격리를 제공한다.
도커 엔진은 네트워크 간 액세스를 차단하고 노출된 컨테이너의 포트를 관리하는 호스트 방화벽 규칙을 관리한다. Swarm & UCP 클러스터에서 이렇게 하면 클러스터에서 애플리케이션이 스케쥴링될 때 애플리케이션을 동적으로 보호하는 분산 방화벽이 만들어진다.
이 표는 도커 네트워크를 이용한 몇 가지 액세스 정책을 요약한 것이다.
| 경로 | 액세스 |
|---|---|
| 도커 네트워크 내부 | 액세스는 동일한 도커 네트워크의 모든 포트에 있는 모든 컨테이너 사이에 허용된다. 이는 모든 네트워크 유형(메인 범위, 로컬 범위, 내장 드라이버 및 원격 드라이버)에 적용된다. |
| 도커 네트워크 사이 | 액세스는 도커 엔진에 의해 관리되는 분산 호스트 방화벽 규칙에 의해 도커 네트워크 사이에 거부된다. 컨테이너를 여러 개의 네트워크에 연결하여 다른 도커 네트워크 사이에 통신할 수 있다. 도커 네트워크 사이의 네트워크 연결은 호스트 외부에서 관리할 수도 있다. |
| 도커 네트워크에서 엔그레스 | 도커 호스트 외부로 향하는 도커 네트워크 내부에서 발생한 트래픽은 허용된다. 호스트의 로컬 스테이트풀 방화벽은 연결을 추적하여 해당 연결에 대한 응답을 허용한다. |
| 인그레스에서 도커 네트워크 | 인그레스 트래픽은 기본적으로 거부된다. 호스트 포트 또는 인그레스 모드 포트를 통한 포트 노출은 명백한 인그레스 액세스를 제공한다. |
| 예외적으로 MACVLAN 드라이버는 외부 네트워크와 동일한 IP 공간에서 작동하고 해당 네트워크 내에서 완전히 열린다. MACVLAN과 유사하게 작동하는 다른 원격 드라이버는 인그레스 트래픽도 허용할 수 있다. |
컨트롤 플레인 보안
도커 Swarm은 통합된 PKI를 따른다. Swarm에 있는 모든 관리자와 노드는 서명된 인증서 형식의 암호로 암호화된(cryptographically signed) ID를 가지고 있다. 관리자-관리자 사이 및 매니저-노드 사이의 모든 컨트롤 통신은 TLS를 통해 외부로부터 보호된다. 도커 Swarm 모드에서 종단간 컨트롤 플레인 트래픽을 확보하기 위해 외부에서 인증서를 생성하거나 CA를 수동으로 설정할 필요가 없다. 인증서는 주기적으로 자동으로 순환된다.
데이터 플레인 네트워크 암호화
도커는 바로 사용할 수 있는 오버레이 네트워크에 대해 IPSec 암호화를 지원한다. Swarm 및 UCP 관리 IPSec 터널은 소스 컨테이너를 떠날 때 네트워크 트래픽을 암호화하고 목적지 컨테이너에 들어갈 때 암호를 복호한다. 이렇게 하면 기본 네트워크에 관계없이 전송되는 애플리케이션 트래픽이 매우 안전할 수 있다. 하이브리드, 멀티 테넌트(Multi-tenant) 또는 멀티 클라우드 환경에서는 제어할 수 없는 네트워크를 통과할 때 데이터가 안전하게 보호되도록 하는 것이 중요하다.
이 다이어그램은 도커 Swarm의 서로 다른 호스트에서 실행되는 두 컨테이너 사이의 통신을 보호하는 방법을 보여준다.

이 기능은 --opt crypted=true 옵션 (예: docker network create -d overlay --opt crypted=true <NETWORK_NAME>)을 추가하여 생성시 네트워크별로 활성화할 수 있다. 네트워크가 생성된 후에는 해당 네트워크에서 서비스를 시작할 수 있다 (예: docker service create --netWORK_NAME> <IMAGE> <COMMAND>). 동일한 서비스의 두 태스크가 서로 다른 두 호스트에서 생성되면, IPsec 터널이 생성되고 소스 호스트를 떠날 때 트래픽이 암호화되고, 목적지 호스트에 들어올 때 암호가 복호된다.
Swarm 리더는 주기적으로 대칭 키를 재생성하여 모든 클러스터 노드에 안전하게 배포한다. 이 키는 IPsec에서 데이터 플레인 트래픽을 암호화하고 복호화하는 데 사용된다. 암호화는 AES-GCM을 사용하여 호스트 간 전송 모드에서 IPSec를 통해 구현된다.
관리 플레인 보안 및 UCP의 RBAC
UCP로 네트워크를 만들 때, 팀과 레이블은 컨테이너 리소스에 대한 액세스를 정의한다. 리소스 권한 레이블은 특정 도커 네트워크를 보고 설정하고 사용할 수 있는 사용자를 정의한다.

이 UCP 스크린샷은 해당 팀 구성원에게만 이 네트워크에 대한 접근을 제어하기 위한 product-team 라벨의 사용을 보여준다. 또한 네트워크 암호화와 같은 옵션은 UCP를 통해 전환할 수 있다.
IP 주소 관리
컨테이너 네트워킹 모델(CNM)은 유연한 IP 주소 관리 방법을 제공한다. IP 주소 관리를 위한 두 가지 방법이 있다.
- CNM은 클러스터에 대해 전역으로 IP 주소를 간단하게 할당하고 중복 할당을 방지하는 네이티브 IPAM 드라이버를 가지고 있다. 네이티브 IPAM 드라이버는 다른 드라이버가 지정되지 않은 경우 기본적으로 사용되는 드라이버다.
- CNM은 다른 벤더와 커뮤니티의 원격 IPAM 드라이버를 사용하는 인터페이스를 가지고 있다. 이러한 드라이버는 기존 벤더 또는 자체 내장 IPAM 도구에 통합될 수 있다.
컨테이너 IP 주소와 네트워크 서브넷의 수동 구성은 UCP, CLI 또는 도커 API를 사용해 수행할 수 있다. 주소 요청은 선택된 드라이버를 거친 후에 요청을 처리하는 방법을 결정한다.
서브넷 크기와 설계는 주로 특정 애플리케이션과 특정 네트워크 드라이버에 의존한다. IP 주소 공간 설계는 다음 절에서 각 네트워크 배포 모델에 대해 보다 심도 있게 다룬다. 포트 매핑, 오버레이 및 MACVLAN의 사용은 모두 IP 주소 할당 방법에 영향을 미친다. 일반적으로 컨테이너 주소 지정은 두 개의 버킷으로 나뉜다. 내부 컨테이너 네트워크(브리지 및 오버레이)는 기본적으로 물리적 네트워크에서 라우팅할 수 없는 IP 주소를 가진 컨테이너를 처리한다. MACVLAN 네트워크는 물리적 네트워크의 서브넷에 있는 컨테이너에 IP 주소를 제공한다. 따라서, 컨테이너 인터페이스의 트래픽은 물리적 네트워크에서 라우팅할 수 있다. 내부 네트워크(브리지, 오버레이)의 서브넷이 물리적 언더레이 네트워크의 IP 공간과 충돌하지 않아야 한다는 점에 유의해야 한다. 겹치는 주소 공간으로 인해 트래픽이 목적지에 도달하지 못할 수 있다.
네트워크 트러블슈팅
도커 네트워크 트러블슈팅은 데브옵스 엔지니어와 네트워크 엔지니어에게 어려울 수 있다. 도커 네트워킹의 작동 방식과 적절한 도구 세트를 올바르게 이해하면 이러한 네트워크 문제를 해결할 수 있다. 한 가지 권장되는 방법은 netshoot 컨테이너를 사용하여 네트워크 문제를 해결하는 것이다. netshoot 컨테이너에는 도커 네트워크 문제를 해결하는 데 사용할 수 있는 강력한 네트워킹 트러블슈팅 도구 모음이다.
netshoot과 같은 트러블슈팅 컨테이너를 사용하는 것의 장점은 네트워크 트러블슈팅 도구가 이식 가능하다는 것이다. netshoot 컨테이너는 호스트 네트워크의 뷰포인트를 검사하기 위해 어떤 네트워크에 연결되거나, 호스트 네트워크 네임스페이스, 또는 다른 컨테이너의 네트워크 네임스페이스에 배치될 수 있다.
컨테이너에는 아래 도구 등이 포함된다.
- iperf
- tcpdump
- netstat
- iftop
- drill
- util-linux(nsenter)
- curl
- nmap
네트워크 배포 모델
다음 예제는 도커 펫이라는 가상의 앱을 사용하여 네트워크 배포 모델(Network Deployment Models)을 보여준다. 백엔드 데이터베이스에서 페이지에 대한 히트 수를 계산하면서 웹페이지에 있는 애완동물의 이미지를 제공한다.
- web은 chrch/docker-pets:1.0 이미지를 기반으로 하는 프런트엔드 웹 서버임
- db는 consul 백엔드임
chrch/docker-pets는 백엔드 db 서비스를 찾는 방법을 알려주는 환경 변수 DB를 기대한다.
단일 호스트의 브리지 드라이버
이 모델은 네이티브 도커 bridge 네트워크 드라이버의 기본 동작이다. bridge 드라이버는 호스트 내부에 전용 네트워크를 생성하고 외부 연결을 위해 호스트 인터페이스에 외부 포트 매핑을 제공한다.
$ docker network create -d bridge petsBridge
$ docker run -d --net petsBridge --name db consul
$ docker run -it --env "DB=db" --net petsBridge --name web -p 8000:5000 chrch/docker-pets:1.0
Starting web container e750c649a6b5
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
IP 주소를 지정하지 않으면 호스트의 모든 인터페이스에 포트 매핑이 노출된다. 이 경우 컨테이너의 애플리케이션이
0.0.0.0:8000에 노출된다. 알릴 특정 IP 주소를 제공하려면 플래그-p IP:host_port:container_port를 사용한다. 포트를 노출하는 추가 옵션은 도커 docs에서 찾을 수 있다.

애플리케이션은 모든 인터페이스의 포트 8000에서 이 호스트에 로컬로 노출된다. 또한 백엔드 컨테이너의 이름을 제공하는 DB=db도 공급된다. 도커 엔진의 내장 DNS를 통해 이 컨테이너 이름이 db의 IP 주소로 확인된다. bridge는 로컬 드라이버이기 때문에 DNS 레졸루션 범위는 단일 호스트에만 있다.
아래의 출력은 우리의 컨테이너가 petsBridge 네트워크의 172.19.0.0/24 IP 공간으로부터 개인 IP를 할당받았다는 것을 보여준다. 도커는 다른 IPAM 드라이버가 지정되지 않은 경우, 내장 IPAM 드라이버를 사용하여 적절한 서브넷에서 IP를 제공한다.
$ docker inspect --format web
172.19.0.3
$ docker inspect --format db
172.19.0.2
이러한 IP 주소는 petsBridge 네트워크 내부의 통신에 내부적으로 사용된다. 이러한 IP는 호스트 밖으로 절대 노출되지 않는다.
외부 서비스 검색의 멀티 호스트 브리지 드라이버
브리지 드라이버는 로컬 범위 드라이버이기 때문에 다중 호스트 네트워킹에는 다중 호스트 서비스 검색 솔루션이 필요하다. 외부 SD는 컨테이너 또는 서비스의 위치와 상태를 등록한 다음 다른 서비스가 해당 위치를 검색할 수 있도록 한다. 브리지 드라이버는 외부 액세서를 위해 포트를 노출하므로, 외부 SD는 host-ip:port를 지정된 컨테이너의 위치로 저장한다.
다음 예에서는, 각 서비스의 위치가 수동으로 설정되어, 외부 서비스 검색을 시뮬레이션한다. db 서비스의 위치는 DB 환경 변수를 통해 웹으로 전달된다.
# 백엔드 db 서비스를 생성하여 포트 8500에 노출
host-A $ docker run -d -p 8500:8500 --name db consul
# host-A의 호스트 IP 표시
host-A $ ip add show eth0 | grep inet
inet 172.31.21.237/20 brd 172.31.31.255 scope global eth0
inet6 fe80::4db:c8ff:fea0:b129/64 scope link
# 프론트엔드 웹 서비스를 생성하여 host-B의 포트 8000에 노출
host-B $ docker run -d -p 8000:5000 -e 'DB=172.31.21.237:8500' --name web chrch/docker-pets:1.0
web 서비스는 이제 host-B IP 주소의 포트 8000에서 웹 페이지를 서비스해야 한다.

이 예에서는 사용할 네트워크를 지정하지 않으므로, 기본 도커
bridge네트워크가 자동으로 선택된다.
db 위치를 172.31.237:8500으로 설정하면, 서비스 검색의 폼을 생성하게 된다. 우리는 웹 서비스를 위한 db 서비스의 위치를 정적으로 설정하고 있다. 단일 호스트 예에서, 도커 엔진은 컨테이너 이름에 대해 내장 DNS 레졸루션을 제공했기 때문에, 자동으로 수행되었다. 이 다중 호스트 예제에서는 서비스 검색을 수동으로 수행하고 있다.
프로덕션 환경에서는 애플리케이션 위치의 하드 코딩이 권장되지 않는다. 외부 서비스 검색 도구는 클러스터에서 컨테이너가 생성 및 파괴될 때 이러한 매핑을 동적으로 제공한다. 몇 가지 예는 consul과 etcd이다.
다음 섹션에서는 클러스터 전반에서 전역 서비스 검색을 내장 기능으로 제공하는 overlay 드라이버 시나리오를 살펴본다. 이러한 단순성은 네트워크 서비스를 제공하기 위해 여러 외부 도구를 사용하는 것과 대조적인 overlay 드라이버의 주요 장점이다.
오버레이 드라이버가 있는 다중 호스트
이 모델은 네이티브 overlay 드라이버를 사용하여 외부로 다중 호스트 연결성을 제공한다. 오버레이 드라이버의 기본 설정은 컨테이너 애플리케이션 내에서 내부 연결 및 서비스 검색뿐만 아니라 외부 세계에 대한 외부 연결을 제공한다. 오버레이 드라이버 구조 섹션에서는 이 섹션을 읽기 전에 검토해야 할 오버레이 드라이버의 내부를 검토한다.
이 예제는 이전 docker-pets 애플리케이션을 재사용한다. 이 예를 따르기 전에 도커 swarm를 설정하라. Swarm을 설정하는 방법에 대한 지침은 도커 문서를 참조하라. Swarm을 설정한 후, docker service create 명령을 사용하여 Swarm이 관리할 컨테이너와 네트워크를 생성하라.
다음은 Swarm을 검사하고, 오버레이 네트워크를 생성한 후, 해당 오버레이 네트워크에 일부 서비스를 프로비저닝하는 방법을 보여준다. 이 명령들은 UCP/Swarm 컨트롤러 노드에서 실행된다.
# 이미 생성된 이 swarm 클러스터에 참여하는 노드 표시
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
a8dwuh6gy5898z3yeuvxaetjo host-B Ready Active
elgt0bfuikjrntv3c33hr0752 * host-A Ready Active Leader
# dognet 오버레이 네트워크 생성
host-A $ docker network create -d overlay petsOverlay
# 백엔드 서비스를 생성하여 dognet 네트워크에 배치
host-A $ docker service create --network petsOverlay --name db consul
# 프런트엔드 서비스를 생성하고 포트 8000에 외부 노출
host-A $ docker service create --network petsOverlay -p 8000:5000 -e 'DB=db' --name web chrch/docker-pets:1.0
host-A $ docker service ls
ID NAME MODE REPLICAS IMAGE
lxnjfo2dnjxq db replicated 1/1 consul:latest
t222cnez6n7h web replicated 0/1 chrch/docker-pets:1.0

단일 호스트 브릿지 예에서와 같이, 우리는 web 서비스에 환경변수로 DB=db를 전달한다. 오버레이 드라이버는 컨테이너의 오버레이 IP 주소로 서비스 이름 db를 결정한다. web과 db 사이의 통신은 오버레이 IP 서브넷을 단독으로 사용하여 이루어진다.
오버레이 및 브리지 네트워크 내부에서는 컨테이너에 대한 모든 TCP 및 UDP 포트가 열려 오버레이 네트워크에 연결된 다른 모든 컨테이너가 액세스할 수 있다.
web 서비스는 포트 8000에 노출되며, 라우팅 메쉬는 Swarm 클러스터의 모든 호스트에 포트 8000을 노출한다. 브라우저의 <host-A>:8000 또는 <host-B>:8000에 가서 애플리케이션이 작동하는지 테스트하라.
오버레이 장점 및 유즈케이스
- 소규모 및 대규모 구축을 위한 매우 단순한 다중 호스트 연결
- 추가 구성 또는 컴포넌트 없이 서비스 검색 및 로드 밸런싱 제공
- 암호화된 오버레이를 통한 동-서 마이크로 세분화에 유용
- 라우팅 메쉬를 사용하여 전체 클러스터에 서비스를 알릴 수 있음
튜토리얼 앱: MACVLAN 브리지 모드
애플리케이션 또는 네트워크 환경에 언더레이 서브넷의 일부인 라우팅 가능한 IP 주소가 컨테이너에 필요한 경우가 있을 수 있다. MACVLAN 드라이버는 이를 가능케 하도록 구현되어 있다. MACVLAN 구조 섹션에 설명된 것처럼, MACVLAN 네트워크는 호스트 인터페이스에 바인딩된다. 물리적 인터페이스, 논리적 하위 인터페이스 또는 결합된 논리적 인터페이스가 될 수 있다. 가상 스위치 역할을 하며 동일한 MACVLAN 네트워크의 컨테이너들 사이에 통신을 제공한다. 각 컨테이너는 노드가 연결된 물리적 네트워크의 고유한 MAC 주소와 IP 주소를 수신한다.

이 예제에서 Pets 애플리케이션은 host-A 및 host-B에 배포된다.
# 두 호스트에 로컬 macvlan 네트워크 생성
host-A $ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 petsMacvlan
host-B $ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 petsMacvlan
# host-B에 db 컨테이너 생성
host-B $ docker run -d --net petsMacvlan --ip 192.168.0.5 --name db consul
# host-A에 web 컨테이너 생성
host-A $ docker run -it --net petsMacvlan --ip 192.168.0.4 -e 'DB=192.168.0.5:8500' --name web chrch/docker-pets:1.0
이는 다중 호스트 브리지 예제와 매우 비슷하게 보일 수 있지만 몇 가지 주목할 만한 차이점이 있다.
- web에서 db로의 참조는 호스트와 반대되는 db 자체의 IP 주소를 사용한다. macvlan 컨테이너 IP는 언더레이 네트워크에서 라우팅할 수 있다는 점을 기억하라.
- 컨테이너에 열린 포트는 컨테이너 컨테이너 IP 주소를 사용하여 즉시 연결할 수 있으므로 db 또는 web 포트는 노출하지 않는다.
macvlan 드라이버는 이러한 고유한 이점을 제공하지만, 희생되는 영역 중 하나는 이식성이다. MACVLAN 설정 및 배포는 언더레이 네트워크와 밀접하게 연관되어 있다. 컨테이너 어드레싱은 중복 주소 할당을 방지하는 것 외에 컨테이너 배치의 물리적 위치를 준수해야 한다. 이 때문에, MACVLAN 네트워크의 외부로 IPAM을 관리하는 데에 주의를 기울여야 한다. IP 어드레싱을 겹치거나 잘못된 서브넷을 사용하면 컨테이너 연결이 끊어질 수 있다.
MACVLAN 장점 및 유즈케이스
- NAT을 활용하지 않기 때문에 대기 시간이 매우 짧은 애플리케이션은 macvlan 드라이버의 이점을 누릴 수 있다.
- MACVLAN은 일부 환경에서는 요구 사항이 될 수 있는 컨테이너당 IP를 제공할 수 있다.
- IPAM에 대한 고려가 보다 신중히 이루어져야 한다.
결론
도커는 빠르게 진화하는 기술이며, 네트워킹 옵션은 매일 점점 더 많은 유즈케이스를 충족시키기 위해 증가하고 있다. 현존 네트워킹 벤더, 순수 SDN 벤더 및 도커 모두 이 분야의 공헌자이다. 물리적 네트워크, 네트워크 모니터링 및 암호화와의 보다 긴밀한 통합은 모두 상당한 관심과 혁신의 영역이다.
이 문서는 자세한 내용을 설명하지만, 존재하는 CNM 네트워크 드라이버와 가능한 모든 배치를 모두 다루진 않았다. 개별 드라이버와 이러한 드라이버를 구성하는 더 많은 방법이 있지만 일상적으로 배포되는 공통 모델은 몇 가지 뿐임을 알 수 있었으면 한다. 각 모델의 장단점을 이해하는 것이 장기적인 성공의 열쇠이다.
기타
IPFS 프로토콜 Kademlia 기본 모델 계층 분석
분산 시스템
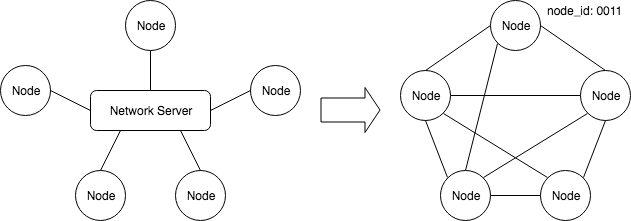
기존의 라우팅 프로토콜에서는 다른 노드를 찾는 서비스를 제공하는 중앙 집중식 서버가 존재합니다. 상호 연결을 하는 경우 각 노드는 동일한 중앙 서버에 등록해야 합니다. 이러한 방식으로, 사용자의 고유 식별 정보에 기초하여 두 당사자에 대한 연결이 성립 됩니다. 분산 시스템에서는 어느 누구도 각 노드의 정보를 관리하지 못합니다. 노드와 노드는 상호 연결되어야 합니다. 특정 알고리즘과 방법을 통해 서로를 찾고, 서로를 식별하고 연결을 설정해야 합니다. 각 노드에는 온라인 네트워크 노드를 나타내는 고유의 node_id 가 있습니다.
Kademlia 기본 모델
네트워크의 다른 노드를 빠르게 찾고 연결 관계를 유지하려면 현재 노드와 다른 노드 사이의 거리를 계산해야 합니다. kademlia DHT 디자인은 XOR 연산을 사용하여 거리를 계산합니다. 노드 간의 거리(XOR 연산을 통한 노드 ID 사이의 비트 거리)를 기반으로 네트워크 라우팅 정보를 유지합니다.
XOR 연산
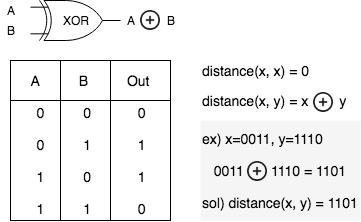
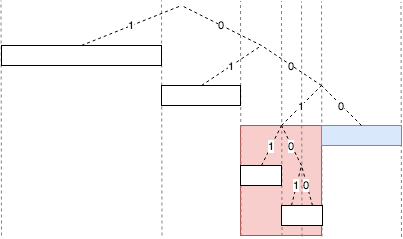
노드 거리를 계산하는 방법은 XOR 연산을 사용합니다. 두 비트의 값이 같으면 XOR 연산의 결과는 0 이고 두 비트의 값이 다른 경우 연산 결과는 1 입니다. 두 네트워크 노드의 ID를 기반으로 이와 같이 계산합니다. 아래 그림에서 노드 ID가 0011 인 A 노드에서 노드 ID가 1110 인 목적지 노드까지 거리는 1101 입니다. 이 XOR 연산을 기반으로 다음과 같은 계산을 유도합니다.

위 그림에서 A 노드 ID에서 다른 노드 ID를 찾는 과정을 간단하게 나열하면 다음과 같습니다.
- 0번째 비트가 있는 A 노드에는 1 이 있음
- 처음 세자리는 001 이며 마지막만 다른 노드 즉, ID가 0010 인 노드가 있을 수 있음
- 해당 노드는 XOR 연산에 따라 거리가 ‘1’ 임을 알 수 있음
- 1번째 비트를 위와 같이 바라보면 노드와 다른 ID를 가진 노드는 2가지가 있을 수 있음
- 0000, 0001 임을 알 수 있음
- 즉, 노드 ID가 00 으로 시작하는 노드가 있음을 알 수 있음
- 2번째 비트를 위와 같이 바라보면 노드와 다른 ID를 가진 노드는 4가지가 있을 수 있음
- 0100, 0101, 0110, 0111 임을 알 수 있음
- 즉, 노드 ID가 0 으로 시작하는 노드가 있음을 알 수 있음
- 3번째 비트를 위와 같이 바라보면 노드와 다른 ID를 가진 노드는 8가지가 있을 수 있음
- 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111 임을 알 수 있음
- 즉, 노드 ID가 1 로 시작하며 노드 ID와 공통 시작점을 가지고 있지 않음
- 이러한 계산을 통하여 A 노드 0011 과의 거리에 따라 다른 카테고리로 나눌 수 있음
- 0번째 비트와의 거리는 ‘1’
- 1번째 비트와의 거리는 ‘2~3’
- 2번째 비트와의 거리는 ‘4~7’
- 3번째 비트와의 거리는 ‘8~15’
즉, i 번째부터 시작하는 노드와의 거리는 현재 노드의 [2^i, 2^(i+1)-1] 입니다. 이를 이진트리 형식으로 표현하면 다음과 같습니다.
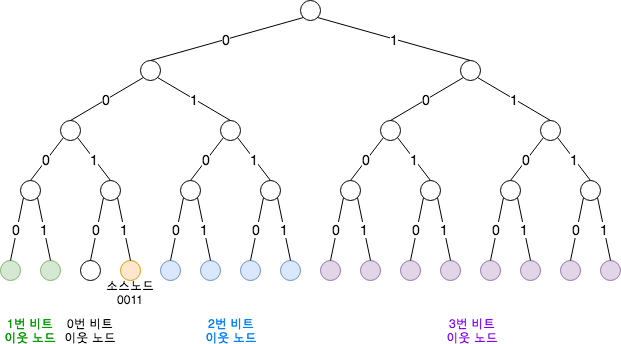
위 그림의 각 색상으로 표현된 그룹은 0, 1, 2, 3 번째 비트에서 소스노드 0011 의 ID와 다른 노드 그룹입니다. 이진트리의 경로는 노드 번호의 각 비트의 값으로 나타냅니다. 리프 노드는 네트워크 노드 번호이며 그 값은 루트 노드에서 리프 노드까지의 경로입니다.
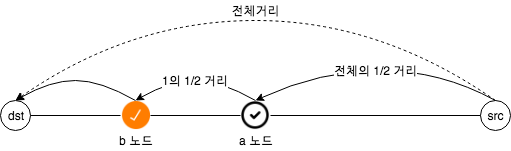
위의 디자인 다이어그램에서 src 노드에서 dst 노드를 찾을 때 위와 같이 src 노드와 dst 노드 사이의 거리를 계산 한 다음 거리와 일치하는 노드 그룹을 찾습니다. 자신의 하프 존에 없는 노드 그룹을 찾고 dst 노드로 부터 절반 거리에 위치한 중계노드인 a 노드를 찾습니다. a 노드는 자신의 라우팅 거리 테이블에서 dst 노드까지 거리보다 절반 짧은 중계노드인 b 노드를 찾습니다. 이런 반복을 통하여 dst 노드를 찾을 수 있도록 합니다.
이 방법으로 경로를 찾으면 전체 네트워크에 n개의 노드가 있는 경우 최악 검색 속도는 n의 2 로그입니다. 이 알고리즘은 매우 빠른 검색 알고리즘입니다. 노드가 100만 개이면 검색은 최대 20회만에 대상 노드를 찾을 수 있습니다.
즉, 0011 노드가 1100 노드를 찾는 경우 ‘1’ 로 시작되는 모든 노드 정보를 알 필요 없이 ‘1’로 시작되는 노드 하나만 알면되고, 그 노드를 통해 1100 의 행방을 수소문 하면 되는 것입니다. 결론적으로 Kademlia는 모든 정보를 가지고 있을 수 없는 거대한 집합군에서 특정 노드를 빠르게 O(log2(n)) 찾기 위한 방식입니다.
k-bucket
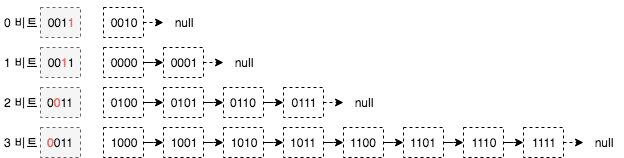
ID가 0011 인 네트워크 노드의 경우 라우팅 테이블에 저장된 정보는 위 그림과 같습니다. 위 그림은 네트워크 ID에 대하여 4가지 비트를 비교하고 모든 노드 정보를 저장하고 있습니다. 그러나 네트워크의 ID가 160 비트까지 늘어나는 경우를 생각한다면 각 노드에 대한 정확한 정보를 저장하는 것은 중복성 및 정확성에 있어 문제가 됩니다. ID의 모든 노드가 항상 온라인 상태가 아니므로 많은 데이터 일관성 문제가 발생합니다.
IPFS는 이러한 문제를 해결하기 위해 k-buckets 디자인을 적용하였습니다. 이 디자인의 원칙은 로컬 노드와의 거리에 따라 다른 ID 공간의 노드를 그룹화하고, 각 그룹은 최대 K 개의 노드 정보를 저장할 수 있습니다. 예를들어 4비트 ID 공간 주소라면 K = 3 인 경우, 노드는 아래 그림과 같이 라우팅 정보를 저장합니다.
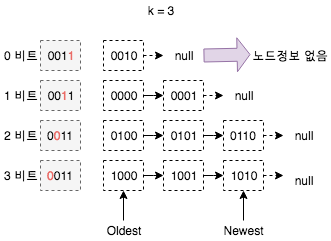
위 그림에서 비트로 나뉜 각 그룹은 최대 K 개의 노드 정보를 저장합니다. k-buckets 디자인을 적용하면 각 노드가 저장할 정보의 양을 줄일 수 있습니다. 유효거리가 가까운 노드인 경우 (온라인이 아니거나 노드 정보가 작성되지 않는 경우) 정보를 저장하지 않습니다. 위 그림에서는 그룹 ‘0’ 번이 이에 해당됩니다. ‘3’ 번 그룹의 경우 전체 네트워크 노드 ID 공간의 절반을 담당하기 때문에 온라인 노드 정보를 사용할 수 있습니다.
노드를 찾을 때 적절한 그룹으로 이동하여 노드를 선택하여 대상 노드에 대한 정보를 요청합니다. 예를들어 a 노드 그룹이 K 보다 작거나 같은 경우 a 노드는 목적지 노드를 찾는데 도움이 됩니다. 검색 프로세스에서 a 노드가 응답하지 않으면 노드 정보를 그룹에서 제거합니다. 응답이 있는 경우 그룹의 k-buckets 큐 끝에 노드를 추가합니다. 즉, 마지막에 저장된 정보는 최근에 사용 가능함을 확인한 노드 정보 입니다. 네트워크 라우팅 과정에서 노드가 사용 가능한 것으로 판명(자신의 k-buckets 대기열 중 하나에 속함)되면 다음 노드 정보가 큐의 끝에 추가됩니다. 만약 큐에 K 개 이상의 노드가 있는 경우 큐의 시작 노드가 사용 가능한지 확인합니다. 연결되어 있는 경우라면 새로 발견된 노드는 추가할 수 없으므로 삭제합니다. 연결되어있지 않다면 큐에서 사용할 수 없는 노드를 제거한 뒤 새로 발견된 노드 정보를 큐 마지막에 추가합니다.
이를 테스트하면 다음과 같은 그래프를 얻을 수 있습니다.
위 그래프에서 x 축은 시간을 의미하고 y 축은 한 시간전에 온라인 상태인 노드가 온라인 상태를 유지하는 확률을 나타냅니다. 즉, 노드는 온라인 시간이 길수록 상태를 유지하는 경향이 있습니다. 따라서 새로 발견 된 노드를 버리고 오래된 온라인 상태의 노드를 업데이트 합니다. 업데이트 방식의 또 다른 장점은 DOS 공격에 대한 강력한 방어 수단이 있다는 것입니다. DOS 공격이 발생하면 새로운 공격 노드가 이전 온라인 노드의 상태를 대신할 수 없습니다. 또한 새로운 공격 노드의 링크 요청이나 라우팅 정보를 삭제할 수 있습니다.
IPFS에서 Kademlia 활용
Kedamlia 프로토콜은 PING, STORE, FIND_NODE, FIND_VALUE 네 가지 유형의 명령을 지원합니다.
PING은 ID에 대한 노드가 온라인인지 여부를 확인하고 STORE는 이러한 데이터를 저장 노드로 전달합니다. FIND_NODE는 ID에 대한 네트워크 노드 정보를 조회하는 것으로, 실제 네트워크 환경에서는 검색된 노드의 ID가 온라인이 아니거나 생성되지 않는 경우가 발생할 수 있기 때문에 노드를 찾는 명령이 검색으로 진화합니다. 검색중인 ID와 가장 가까운 K 노드를 찾습니다. K 노드는 동일한 k-buckets 리스트에서 찾을 수 있거나, k-buckets가 가득 차있는 경우 가장 가까운 k-buckets 리스트를 검색합니다. 모든 k-buckets 리스트의 노드 정보의 숫자가 충분하지 않으면 정보 숫자가 얼마나 되는지를 반환합니다.
FIND_VALUE는 FIND_NODE와 유사하지만 검색 과정에서 K 노드가 발견되기 전에 값(value)을 찾았을 가능성이 있습니다. 일부 값은 캐시되기 때문에 VALUE를 저장하는 노드는 직접 내용을 반환하고 프로세스가 종료됩니다.
위의 네 가지 명령처리에서 모든 메시지 수신자는 네트워크 주소 스푸핑을 방지하기 위해 임의의 RPC ID를 반환합니다.
특정 노드 ID에 가장 근접한 K 개의 노드를 찾을 때, K 목표 노드를 찾기 위해 반복 접근법이 사용됩니다. 우선, 라우팅 테이블로부터, 자신에게 가장 가까운 k-buckets 리스트에 있는 노드를 찾은 후 동시에 조회 요청을 시작합니다. 상기 k-buckets의 예에서 K = 3 이기 때문에 a의 값은 1, 2, 3 입니다. 그러므로 같은 k-bucket을 가지고 물어 보는 것이 가장 좋습니다. a = 1 일 때, 룩업 프로토콜은 Chord 네트워크로 진화합니다. 노드의 정보를 질의함으로써, 검색자는 수용된 질의 결과에 따라 가장 가까운 거리를 갖는 새로 발견 된 노드에 검색 명령을 재전송 할 수 있습니다. K 개의 거리 타겟 탐색 노드들에 가장 가까운 노드들로부터, 탐색 정보를 전송하지 않은 노드를 연속적으로 찾고, 이들에게 탐색 명령을 전송합니다. 이러한 노드가 올바르게 응답하지 않거나 오프라인 상태이면 라우팅 정보 테이블에서 노드 정보가 삭제됩니다. 이 프로세스에서 현재 K 노드보다 대상 노드에 더 가까운 노드가 발견되지 않으면 K 노드로 계속 진행하며 조회 명령을 전송하지 않은 나머지 노드는 계속 조회 명령을 전송합니다. 검색 프로세스는 룩업 노드가 타겟 노드에 가장 근접하게 접촉 할 수 있는 K 노드 정보를 찾으면 종료합니다.
데이터를 저장할 때 가장 가까운 K 개의 거리 키가 있는 노드를 찾고 저장 명령을 보내면 저장된 발신자는 라우팅 데이터의 견고성을 보장하기 위해 24 시간마다 저장 명령을 브로드캐스트합니다.
데이터를 검색하는 과정에서 캐시를 만날 것이고, K 개의 가장 가까운 노드를 찾기 전에 키의 값을 찾을 것 입니다. 그러면 매우 빨리 데이터를 찾을 수 있습니다. 그러나 데이터 과열 즉, 대상 노드에서 캐시까지의 거리에 따라 많은 사람들이 데이터를 캐시하는 것을 막기위헤 주기적으로 캐시 내용이 삭제됩니다. 물론 대상 노드로부터 더 먼 캐시가 더 빨리 삭제됩니다.
전달 된 노드의 모든 요청 및 데이터는 노드가 로컬 라우팅 정보를 업데이트하는 것을 도울 수 있습니다. 그러나 인기없는 라우팅 정보 중 아무도 액세스하지 못하면 데이터가 매우 냉각됩니다. 라우팅 정보가 너무 냉각되는 것을 방지하기 위해 노드는 ID를 하나씩 무작위로 선택하고 그에 대한 검색 요청을 시작합니다. 이것은 노드의 따뜻함을 보장할 수 있습니다. 이 검색 프로세스는 조회되는 ID에 대해 자신과 다른 해당 노드를 업데이트 할 수 있습니다.
네트워크에 새로 결합 된 노드는 이미 네트워크에서 실행중인 노드 하나 이상을 알고 있어야 합니다. 새로운 노드는 먼저 자신의 k-buckets 큐에 알고있는 노드를 추가하고 ID에 대한 조회 요청을 시작합니다. 이런 과정에서 다른 노드가 응답하게 됩니다. 새 노드는 전체 네트워크의 토폴로지를 업데이트하고 다른 노드가 이 최신 노드에 대한 라우팅 정보를 업데이트 합니다.
Kademlia 라우팅 트리 생성 프로세스
k-buckets 라우팅 정보는 이진트리 형식으로 저장됩니다. 이진트리의 생성은 동적이며 이진트리 데이터 구조는 발견된 노드의 ID에 따라 동적으로 조정됩니다. 다음은 동적 생성 프로세스를 설명하기 위한 노드 번호가 0000 인 비어있는 이진트리의 예입니다.
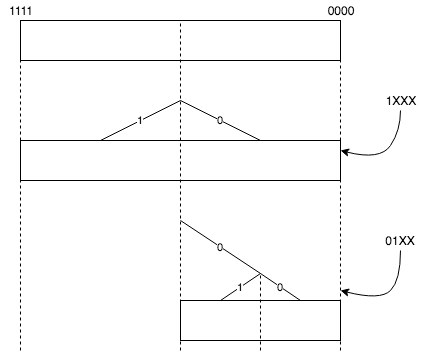
예 1) 새롭게 발견 된 첫 번째 노드 ID 번호의 첫 번째 비트가 1이면, 두 번째 k-buckets가 생성되고, 첫 번째 비트가 ‘1’인 노드 ID의 정보를 저장합니다. 첫 번째 비트가 ‘0’을 갖는 다른 ID, 이 k-buckets ID의 공간은 현재 노드 0000 을 포함합니다.
예 2) 첫 번째 노드의 ID 번호가 새로 발견되면 첫 번째 비트는 ‘0’이고 현재 노드 ID 번호는 0000 의 첫 번째 비트와 같습니다. 하지만 두 번째 비트는 1이며 현재 노드 ID 비트의 두 번째 값이 다릅니다. 이런경우 두 개의 k-buckets이 생성되고 ‘00’ 및 ‘01’로 시작하는 ID 정보를 나타냅니다.
위 내용은 두가지 예로 설명할 수 있습니다.
- 이진트리에서 새롭게 추가된 노드의 ID가 현재 노드 ID를 커버하는 k-buckets 범위 내에 있으면 현재 노드 ID가 있는 영역을 두개의 k-buckets 으로 분할하고 규칙에 따라 새로운 k-buckets 그룹에 가입됩니다.
- 새로 추가된 노드 ID가 현재 노드 ID가 위치한 k-buckets 공간과 다른 경우, 자신에 속한 k-buckets 이진트리에 따라 검색되고, 큐가 가득 찼으면 추가되거나 삭제됩니다.
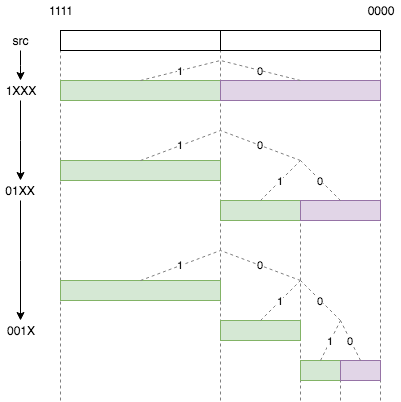
위의 그림은 세 개의 노드가 특정 순서로 추가 될 때 이진트리의 간단한 동적 생성 프로세스를 보여줍니다. 녹색 k-buckets는 노드 ID가 없는 ID 공간을 나타내며 보라색 k-buckets는 노드 ID가 있는 ID 공간을 나타냅니다. 신규 노드의 ID가 현재 ID가 위치하는 ID 공간과 일치하는 경우, 분할 노드의 ID 공간은 2 개의 리프 노드가 됩니다.
네트워크에있는 모든 노드의 ID가 001 로 시작하는 경우 000 을 이 노드에 추가하면 이진트리의 원래 구조는 논리에 따라 삭제해야 합니다. 원래 논리는 k-buckets에서 각 그룹화 노드의 총 수는 K를 초과 할 수 없습니다. 위의 그림에서 노드 0000 의 경우 빨간색 상자의 노드는 k-buckets 통합 표현이어야 하며 버킷이 K 노드를 초과 할 수 없다는 한계를 충족 시키지 몇몇 노드는 삭제해야 합니다. 하지만 이런 경우 라우팅 정보가 손실됩니다. 이 문제를 해결하기 위해 kademlia는 원래의 첫 번째 노드와 새 노드가 생성 된 새로운 이진트리를 생성합니다. 이렇게 하면 새로운 노드 조인 전에 라우팅 구조를 유지 할 수 있습니다.
Key-Value 데이터 저장 장치의 유효성과 장기적인 성질을 보장하기 위해 노드는 주기적으로 키 정보를 브로드캐스팅해야 합니다. 정보가 정기적으로 업데이트되지 않으면 1) Key-Value를 수락하는 노드가 정보를 저장한 후 노드가 오프라인 상태가 되거나 2) 새로운 노드가 온라인 상태이고 ID 값이 현재 K 노드보다 데이터 게시자에 더 가깝지만 데이터에 대한 정보가 없을 수 있습니다. 위의 두 가지 조건으로 인해 데이터가 검색되지 않을 수 있습니다.
이 문제를 해결하기 위해 매시간마다 최신 온라인 상태를 얻기위한 조회 명령을 수행하지 않고 간단한 모델을 사용하여 최적화 프로세스를 훨씬 저렴하게 만들 수 있습니다. 노드가 룩업 명령을 수신하면, 다른 K-1 노드가 동일한 명령을 수신 하였으므로, 명령을 수신 한 노드는 자신의 시간을 업데이트하고 다음 시간에 탐색을 수신하지 않도록 타이밍을 설정합니다. 명령어의 경우에는 실제로 룩업 명령어를 발행하므로 실제로 동일한 시간 내에 특정 데이터 쌍의 룩업 명령어에 대해 하나의 노드만 발행됩니다. 이렇게하면 시스템의 메시지 수가 크게 줄어 듭니다.
또 다른 메커니즘은 k-buckets가 분할 될 때 특정 ID 값의 마지막 K 개 노드의 라우팅 정보를 다시 정렬하고 업데이트하는 것입니다. 이 프로세스는 타이밍 검색의 명령을 어느 정도 완화합니다.
Kademlia 보안
k-buckets가 가득차면 노드를 삭제하기 위하여 큐에서 가장 최신의 링크가 유효한지 확인합니다. 유효한 링크인 경우 새로 추가할 노드를 삭제합니다. 유효한 링크가 아닌 경우 이전의 노드가 삭제되고 새로운 노드가 큐 마지막에 추가됩니다. 그러나 이러한 경우 특정 응용 프로그램이 많은 메시지를 생성하여 네트워크에 문제를 발생하게 할 수 있습니다. 새로 추가된 노드는 실제 대기큐에 추가됩니다. 노드에게 검색 명령을 활용하여 응답여부를 확인하고 응답하지 않은 노드는 삭제되고 대기큐에서 k-buckets에 참가할 노드를 선택하게 됩니다. 이를 위하여 대기큐의 노드를 시간대별로 정하는 전략을 사용합니다. 즉, 시간이 가장 짧은 노드가 가장 빨리 교체되는 것 입니다.
Kademlia는 UDP를 프로토콜로 사용하기 때문에 패킷 손실이나 네트워크 정체로 인한 패킷 지연이 있으며 노드가 제 시간에 응답하지 않으면 RPC 상태 검사가 계속 전송되지 않습니다. RPC 상태 검사에 대한 올바른 응답이 연속 5회 수행되지 않으면 노드는 k-buckets 에서 삭제되지 않지만 관찰 대상으로 표시됩니다. 자체 네트워크의 플래싱으로 인해 노드의 모든 라우팅 정보가 삭제되는 것을 방지하기 위함입니다. 네트워크가 복원되면 라우팅 정보가 업데이트되어야 합니다.
Kademlia는 검색 속도를 높이기 위하여 이진트리를 사용하지 않고 2^b 크기로 분기되는 트리를 사용하여 트리 높이를 줄이고 검색속도를 높입니다. 그러나 이를 위해서는 k-buckets 라우팅 테이블 크기를 늘려야 합니다.
S/Kademlia
S/Kademlia는 악의적 공격에 대비해 두가지 중요한 방식으로 Kademlia를 확장한 디자인입니다. S/Kademlia는 노드ID 생성을 지킬 수 있는 스키마를 제공하여 sybill 공격을 예방합니다. PKI Key-Pair를 생성하기 위해서 노드를 요구하고 이 키에서 아이디를 찾아 서로의 메세지에 서명 할 수 있습니다. 한가지 스키마에는 sybills 를 어렵게 만들기 위한 proof of work 암호화 퍼즐이 포함되어있습니다. S/Kademlia노드는 정직한 노드들이 네트워크 상의 큰 부분의 상대방에게 접속 할 수 있도록 disjoint path에서 값을 탐색합니다. S/Kademlia는 연결에 적대적인 노드가 절반이어도 성공률 0.85정도를 보이고 있다고 합니다.
노드ID 생성을 지킬 수 있는 스키마란 참여노드의 ID를 랜덤 방식을 사용하여 안전하게 생성함을 의미합니다. 공격자는 이러한 ID 생성 규칙을 통과하지 않는한 공격할 수 없습니다. 또한 주변 노드의 ID를 알 수 있는 방법도 없습니다.
서명은 약한서명과 강한서명으로 나뉩니다.
-
약한서명: 노드의 IP 주소, 포트, 타임 스탬프와 같은 메시지 일부를 서명하는 것 입니다. 타임 스탬프 서명에는 유효시간이 지정되어 동적 IP 릴레이 공격 문제를 해결합니다. 약한서명은 메시지 무결성 요구 사항이 요구되지 않는
PING명령에 사용됩니다. -
강한서명: 메시지의 전체 유효성을 보장하고 man-in-the-middle 공격에 효과적으로 대처할 수있는 노드 간 전체 메시지의 서명이며 메시지에 임의의 숫자를 추가하여 릴레이 공격 문제를 해결합니다.
공격에 대비하기 위하여 노드 ID는 랜덤 방식을 이용하고 공개키를 해싱한 ID를 사용하게 되는데 이를 위한 두가지 방식이 존재합니다. 1) 중앙집중식 인증기관을 통한 방식 과 2) 암호화 퍼즐을 통한 노드 ID 생성 방식 입니다.
흔히 CA라고 이야기하는 중앙집중식 인증서 방식은 노드가 거의 없거나, 초기 단계에 사용됩니다. 최초 공개 체인에서 초기 노드의 숫자를 파악하고 이 방식을 채택할지 결정합니다.
완전 분산된 네트워크에서 노드 ID는 매우 어려운 문제를 해결하여야 생성되도록 합니다. 일종의 수수께끼를 풀어야하는 방식인데 크게 두가지 방법이 제공되고 있습니다.
- 첫번째 방법
- 먼저 비대칭 키 쌍을 생성
- 다음 공개 키에 대한 두 가지 해시 작업을 수행
- 생성 된 해시 값보다 C1 비트가 0인지 확인
-
1에서 다시 시작하여 조건이 충족되면 노드의 ID 번호를 공개 키의 기본 해시 값으로 설정
- 두번째 방법
- 노드 ID가 생성 된 후
- 난수 생성
- 노드와 난수 간의 거리를 계산 한 다음 해시 계산
- 만족하지 않으면 해시 값의 c2 비트가 0인지 확인 (조건은 난수를 계속 선택하고 조건이 충족되면 노드 ID와 난수 X가 표시)
- 악의적인 공격자가 NodeId와 난수 x를 만족하는 많은 양의 정보를 생성하기를 원한다면 엄청난 컴퓨터 자원을 소비합니다. 이 기능은 돌이킬 수 없기 때문에 마이닝 프로세스와 비슷한 값을 찾는 것은 매우 리소스 집약적
S/Kademlia 는 아직 IPFS의 Main project에 속해있지 않습니다. 하지만 Locality 와 Security 는 매우 중요한 이슈이며 이를 해결할 수 있는 방안은 반드시 필요합니다.
IPFS 프로토콜 라우팅 계층 분석
IPFS 프로토콜 계층 심층 분석
IPFS는 아키텍처를 6 개의 레이어로 추상화합니다. 각 레이어는 기술 구현 또는 특정 기술 솔루션을 가지고 있습니다. 프로토콜로서 IPFS는 인터페이스 형태로 레이어 간의 기능 및 상호 호출 관계를 정의합니다.

라우팅 계층 프로토콜
두 번째 레이어인 라우팅 레이어부터 시작하고자 하는데, 디자인의 첫 번째 레이어인 네트워크 레이어는 기본적인 네트워크 장비 또는 네트워크 기능으로 이해할 수 있습니다. 또한 암호화 전송, 다중 링크 혼합 및 기타 기술을 추가하는 지점 간 링크를 구축 할 수 있습니다. 다음 그림은 IPFS 스택에 대한 기반 기술을 표현한 그림입니다.
IPFS 라우팅
라우팅 레이어가 인터페이스 형태로 제공하는 기능을 정의합니다. 라우팅 레이어는 저장된 콘텐츠 검색 및 IPFS 노드의 경로 조회를 지원합니다. 이를 위해 DHTS, mdns, snr 또는 DNS 프로토콜을 사용할 수 있습니다. 네트워크에서 라우팅 프로토콜의 구성은 노드 및 라우팅 데이터를 찾은 다음 init으로 실행되는 IPFS 초기화를 실행합니다. local-discovery를 통하여, IPFS 시스템은 mdns를 라우팅 계층을 로드합니다.
라우팅 레이어 프로토콜의 함수 정의입니다. 다음과 같이 인터페이스 형식으로 표현합니다.
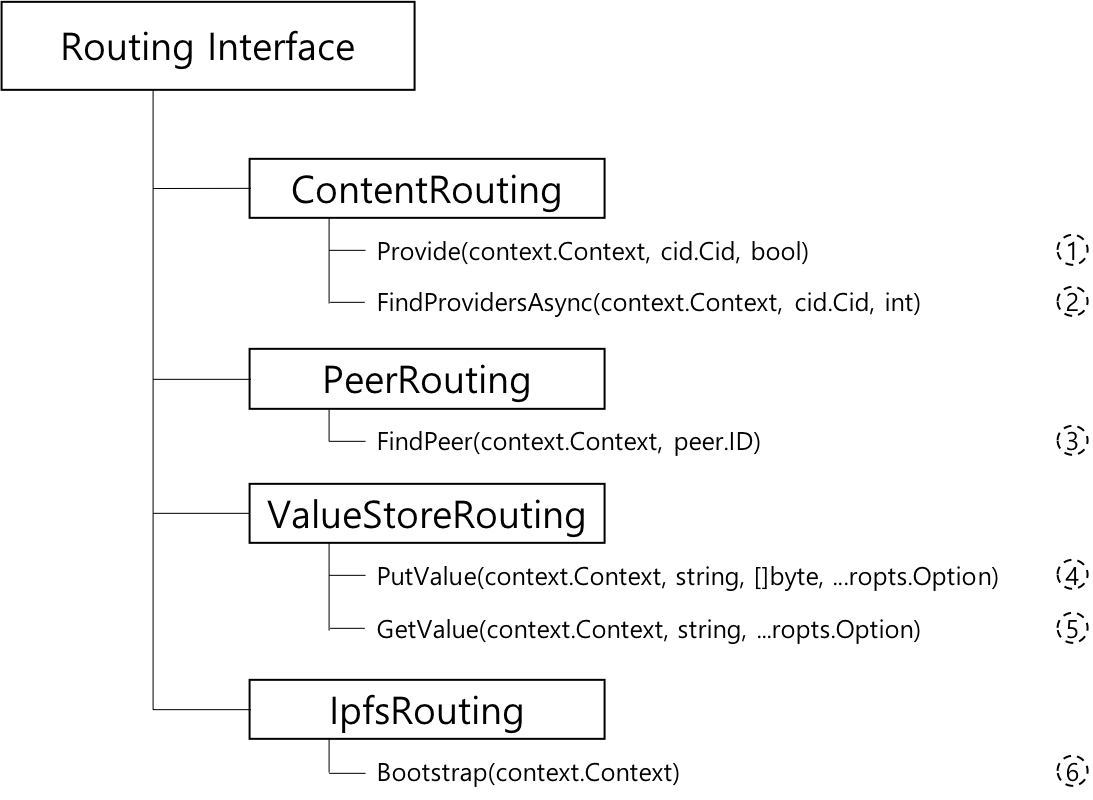
위 그림은 IPFS 라우팅 계층 프로토콜이 가져야하는 기본 기능을 나타냅니다.
- ContentRouting: ContentRouting은 간접적인 가치 제공자 계층으로 누가 어떤 컨텐츠를 가지고 있는지에 대한 정보를 찾는 데 사용됩니다.
Provide: 특정 키에 따라 현재 노드가 키에 해당하는 값의 저장 위치를 찾고 필요한 경우 브로드캐스트 방식으로 가장 가까운 IPFS 노드에 정보를 브로드캐스팅 할지 여부를 결정합니다. 자신의 IPFS 노드는 키에 해당하는 내용의 저장 경로를 기록하고 상황에 따라 다른 노드에 브로드캐스트하여 다른 사람에게이 노드가 키에 대한 라우팅 정보를 알고 있음을 알립니다.FindProvidersAsync: 키의 라우팅 정보를 알고있는 노드 정보를 획득 할 수 있는 노드의 최대 수를 제한 할 수 있습니다.
- PeerRouting: PeerRouting은 은 특정 피어에 대한 정보를 찾는 방법입니다. 이것은 간단한 룩업 테이블, 트래킹 서버 또는 DHT를 통해 구현될 수 있습니다.
FindPeer: 노드의 ID에 따라 노드에 대한 네트워크 서비스 정보를 얻을 수 있습니다. 키는 IPFS 노드의 ID를 나타내고 반환 정보는 노드에 대한 네트워크 계층 데이터 (예: 포트 번호 및 서비스를 제공하기 위한 프로토콜 유형) 입니다.
- ValueStore: ValueStore는 기본 Put/Get 인터페이스입니다.
PutValue: 라우팅 레이어가 키의 저장 경로뿐만 아니라 키에 대한 특정 콘텐츠를 캐시 할 수 있으며 키에 가장 가까운 라우팅 노드에 콘텐츠를 브로드캐스트 합니다. 정보를 받은 후, 다른 라우팅 테이블은 자신의 라우팅 테이블에 정보를 저장해야 합니다.GetValue: 주어진 키에 따라 라우팅 테이블에 직접 저장된 키에 해당하는 콘텐츠를 얻습니다.
- IpfsRouting: IpfsRouting은 ipfs가 사용하는 서로 다른 라우팅 유형의 조합입니다. 단일 항목(예: DHT) 또는 각 작업에 더 최적화된 여러 개의 다른 부분으로 만족될 수 있습니다.
Bootstrap: 주기적으로 라우팅 테이블 정보를 업데이트하는 타이밍 기능입니다. 분산 라우팅 프로토콜이기 때문에 라우팅 테이블 타이밍에 따라 노드의 업 링크 및 오프라인 정보를 동기화하고 업데이트해야 합니다. Bootstrap 을 통해 호출자는 라우팅 시스템에 힌트를 표시하여 Boostrapped 상태가됩니다.
IPFS의 라우팅 관련 내용은 다음에서 확인가능 합니다.
- go-ipfs-routing
go-ipfs-routing은go-ipfs에 사용되는go-libp2p-routing구현
- go-libp2p-routing
아래는 IPFS에서 사용되는 go-libp2p 패키지중 go-libp2p-routing/routing.go 코드의 일부입니다.
// package routing defines the interface for a routing system used by ipfs.
package routing
import ...
// ErrNotFound is returned when the router fails to find the requested record.
var ErrNotFound = errors.New("routing: not found")
// ErrNotSupported is returned when the router does not support the given record
// type/operation.
var ErrNotSupported = errors.New("routing: operation or key not supported")
// ContentRouting is a value provider layer of indirection. It is used to find
// information about who has what content.
type ContentRouting interface {
// Provide adds the given cid to the content routing system. If 'true' is
// passed, it also announces it, otherwise it is just kept in the local
// accounting of which objects are being provided.
Provide(context.Context, cid.Cid, bool) error
// Search for peers who are able to provide a given key
FindProvidersAsync(context.Context, cid.Cid, int) <-chan pstore.PeerInfo
}
// PeerRouting is a way to find information about certain peers.
// This can be implemented by a simple lookup table, a tracking server,
// or even a DHT.
type PeerRouting interface {
// Find specific Peer
// FindPeer searches for a peer with given ID, returns a pstore.PeerInfo
// with relevant addresses.
FindPeer(context.Context, peer.ID) (pstore.PeerInfo, error)
}
// ValueStore is a basic Put/Get interface.
type ValueStore interface {
// PutValue adds value corresponding to given Key.
PutValue(context.Context, string, []byte, ...ropts.Option) error
// GetValue searches for the value corresponding to given Key.
GetValue(context.Context, string, ...ropts.Option) ([]byte, error)
// TODO
// SearchValue searches for better and better values from this value
// store corresponding to the given Key. Implementations may halt the
// search after a period of time or may continue searching indefinitely.
//
// Useful when you want a result *now* but still want to hear about
// better/newer results.
//SearchValue(context.Context, string, ...ropts.Option) (<-chan []byte, error)
}
// IpfsRouting is the combination of different routing types that ipfs
// uses. It can be satisfied by a single item (such as a DHT) or multiple
// different pieces that are more optimized to each task.
type IpfsRouting interface {
ContentRouting
PeerRouting
ValueStore
// Bootstrap allows callers to hint to the routing system to get into a
// Boostrapped state
Bootstrap(context.Context) error
// TODO expose io.Closer or plain-old Close error
}
...
