IPFS 프로토콜 Kademlia 기본 모델 계층 분석
분산 시스템
기존의 라우팅 프로토콜에서는 다른 노드를 찾는 서비스를 제공하는 중앙 집중식 서버가 존재합니다. 상호 연결을 하는 경우 각 노드는 동일한 중앙 서버에 등록해야 합니다. 이러한 방식으로, 사용자의 고유 식별 정보에 기초하여 두 당사자에 대한 연결이 성립 됩니다. 분산 시스템에서는 어느 누구도 각 노드의 정보를 관리하지 못합니다. 노드와 노드는 상호 연결되어야 합니다. 특정 알고리즘과 방법을 통해 서로를 찾고, 서로를 식별하고 연결을 설정해야 합니다. 각 노드에는 온라인 네트워크 노드를 나타내는 고유의 node_id 가 있습니다.
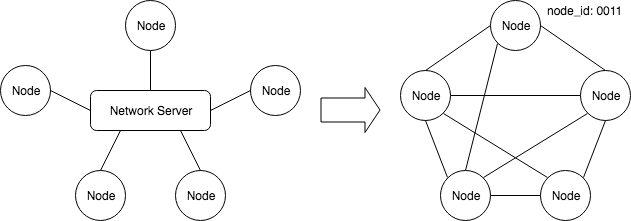
Kademlia 기본 모델
네트워크의 다른 노드를 빠르게 찾고 연결 관계를 유지하려면 현재 노드와 다른 노드 사이의 거리를 계산해야 합니다. kademlia DHT 디자인은 XOR 연산을 사용하여 거리를 계산합니다. 노드 간의 거리(XOR 연산을 통한 노드 ID 사이의 비트 거리)를 기반으로 네트워크 라우팅 정보를 유지합니다.
XOR 연산
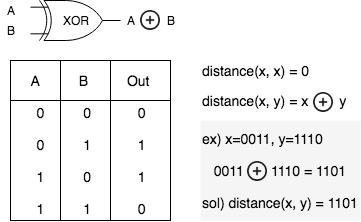
노드 거리를 계산하는 방법은 XOR 연산을 사용합니다. 두 비트의 값이 같으면 XOR 연산의 결과는 0 이고 두 비트의 값이 다른 경우 연산 결과는 1 입니다. 두 네트워크 노드의 ID를 기반으로 이와 같이 계산합니다. 아래 그림에서 노드 ID가 0011 인 A 노드에서 노드 ID가 1110 인 목적지 노드까지 거리는 1101 입니다. 이 XOR 연산을 기반으로 다음과 같은 계산을 유도합니다.

위 그림에서 A 노드 ID에서 다른 노드 ID를 찾는 과정을 간단하게 나열하면 다음과 같습니다.
- 0번째 비트가 있는 A 노드에는 1 이 있음
- 처음 세자리는 001 이며 마지막만 다른 노드 즉, ID가 0010 인 노드가 있을 수 있음
- 해당 노드는 XOR 연산에 따라 거리가 ‘1’ 임을 알 수 있음
- 1번째 비트를 위와 같이 바라보면 노드와 다른 ID를 가진 노드는 2가지가 있을 수 있음
- 0000, 0001 임을 알 수 있음
- 즉, 노드 ID가 00 으로 시작하는 노드가 있음을 알 수 있음
- 2번째 비트를 위와 같이 바라보면 노드와 다른 ID를 가진 노드는 4가지가 있을 수 있음
- 0100, 0101, 0110, 0111 임을 알 수 있음
- 즉, 노드 ID가 0 으로 시작하는 노드가 있음을 알 수 있음
- 3번째 비트를 위와 같이 바라보면 노드와 다른 ID를 가진 노드는 8가지가 있을 수 있음
- 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111 임을 알 수 있음
- 즉, 노드 ID가 1 로 시작하며 노드 ID와 공통 시작점을 가지고 있지 않음
- 이러한 계산을 통하여 A 노드 0011 과의 거리에 따라 다른 카테고리로 나눌 수 있음
- 0번째 비트와의 거리는 ‘1’
- 1번째 비트와의 거리는 ‘2~3’
- 2번째 비트와의 거리는 ‘4~7’
- 3번째 비트와의 거리는 ‘8~15’
즉, i 번째부터 시작하는 노드와의 거리는 현재 노드의 [2^i, 2^(i+1)-1] 입니다. 이를 이진트리 형식으로 표현하면 다음과 같습니다.
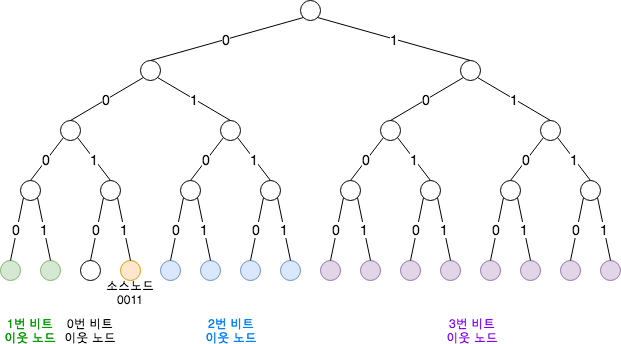
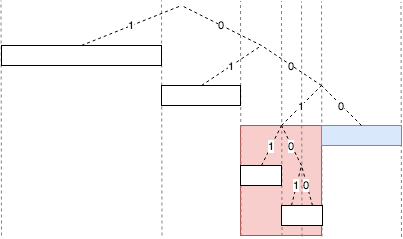
위 그림의 각 색상으로 표현된 그룹은 0, 1, 2, 3 번째 비트에서 소스노드 0011 의 ID와 다른 노드 그룹입니다. 이진트리의 경로는 노드 번호의 각 비트의 값으로 나타냅니다. 리프 노드는 네트워크 노드 번호이며 그 값은 루트 노드에서 리프 노드까지의 경로입니다.
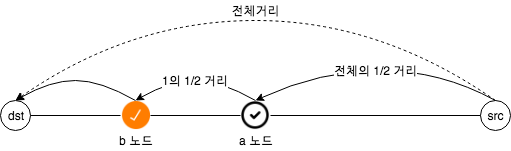
위의 디자인 다이어그램에서 src 노드에서 dst 노드를 찾을 때 위와 같이 src 노드와 dst 노드 사이의 거리를 계산 한 다음 거리와 일치하는 노드 그룹을 찾습니다. 자신의 하프 존에 없는 노드 그룹을 찾고 dst 노드로 부터 절반 거리에 위치한 중계노드인 a 노드를 찾습니다. a 노드는 자신의 라우팅 거리 테이블에서 dst 노드까지 거리보다 절반 짧은 중계노드인 b 노드를 찾습니다. 이런 반복을 통하여 dst 노드를 찾을 수 있도록 합니다.
이 방법으로 경로를 찾으면 전체 네트워크에 n개의 노드가 있는 경우 최악 검색 속도는 n의 2 로그입니다. 이 알고리즘은 매우 빠른 검색 알고리즘입니다. 노드가 100만 개이면 검색은 최대 20회만에 대상 노드를 찾을 수 있습니다.
즉, 0011 노드가 1100 노드를 찾는 경우 ‘1’ 로 시작되는 모든 노드 정보를 알 필요 없이 ‘1’로 시작되는 노드 하나만 알면되고, 그 노드를 통해 1100 의 행방을 수소문 하면 되는 것입니다. 결론적으로 Kademlia는 모든 정보를 가지고 있을 수 없는 거대한 집합군에서 특정 노드를 빠르게 O(log2(n)) 찾기 위한 방식입니다.
k-bucket
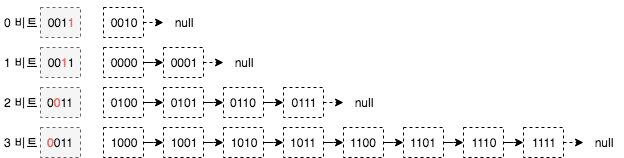
ID가 0011 인 네트워크 노드의 경우 라우팅 테이블에 저장된 정보는 위 그림과 같습니다. 위 그림은 네트워크 ID에 대하여 4가지 비트를 비교하고 모든 노드 정보를 저장하고 있습니다. 그러나 네트워크의 ID가 160 비트까지 늘어나는 경우를 생각한다면 각 노드에 대한 정확한 정보를 저장하는 것은 중복성 및 정확성에 있어 문제가 됩니다. ID의 모든 노드가 항상 온라인 상태가 아니므로 많은 데이터 일관성 문제가 발생합니다.
IPFS는 이러한 문제를 해결하기 위해 k-buckets 디자인을 적용하였습니다. 이 디자인의 원칙은 로컬 노드와의 거리에 따라 다른 ID 공간의 노드를 그룹화하고, 각 그룹은 최대 K 개의 노드 정보를 저장할 수 있습니다. 예를들어 4비트 ID 공간 주소라면 K = 3 인 경우, 노드는 아래 그림과 같이 라우팅 정보를 저장합니다.
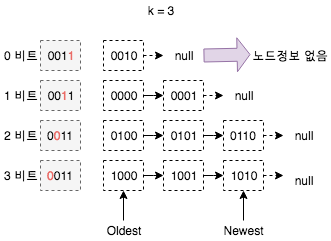
위 그림에서 비트로 나뉜 각 그룹은 최대 K 개의 노드 정보를 저장합니다. k-buckets 디자인을 적용하면 각 노드가 저장할 정보의 양을 줄일 수 있습니다. 유효거리가 가까운 노드인 경우 (온라인이 아니거나 노드 정보가 작성되지 않는 경우) 정보를 저장하지 않습니다. 위 그림에서는 그룹 ‘0’ 번이 이에 해당됩니다. ‘3’ 번 그룹의 경우 전체 네트워크 노드 ID 공간의 절반을 담당하기 때문에 온라인 노드 정보를 사용할 수 있습니다.
노드를 찾을 때 적절한 그룹으로 이동하여 노드를 선택하여 대상 노드에 대한 정보를 요청합니다. 예를들어 a 노드 그룹이 K 보다 작거나 같은 경우 a 노드는 목적지 노드를 찾는데 도움이 됩니다. 검색 프로세스에서 a 노드가 응답하지 않으면 노드 정보를 그룹에서 제거합니다. 응답이 있는 경우 그룹의 k-buckets 큐 끝에 노드를 추가합니다. 즉, 마지막에 저장된 정보는 최근에 사용 가능함을 확인한 노드 정보 입니다. 네트워크 라우팅 과정에서 노드가 사용 가능한 것으로 판명(자신의 k-buckets 대기열 중 하나에 속함)되면 다음 노드 정보가 큐의 끝에 추가됩니다. 만약 큐에 K 개 이상의 노드가 있는 경우 큐의 시작 노드가 사용 가능한지 확인합니다. 연결되어 있는 경우라면 새로 발견된 노드는 추가할 수 없으므로 삭제합니다. 연결되어있지 않다면 큐에서 사용할 수 없는 노드를 제거한 뒤 새로 발견된 노드 정보를 큐 마지막에 추가합니다.
이를 테스트하면 다음과 같은 그래프를 얻을 수 있습니다.
위 그래프에서 x 축은 시간을 의미하고 y 축은 한 시간전에 온라인 상태인 노드가 온라인 상태를 유지하는 확률을 나타냅니다. 즉, 노드는 온라인 시간이 길수록 상태를 유지하는 경향이 있습니다. 따라서 새로 발견 된 노드를 버리고 오래된 온라인 상태의 노드를 업데이트 합니다. 업데이트 방식의 또 다른 장점은 DOS 공격에 대한 강력한 방어 수단이 있다는 것입니다. DOS 공격이 발생하면 새로운 공격 노드가 이전 온라인 노드의 상태를 대신할 수 없습니다. 또한 새로운 공격 노드의 링크 요청이나 라우팅 정보를 삭제할 수 있습니다.
IPFS에서 Kademlia 활용
Kedamlia 프로토콜은 PING, STORE, FIND_NODE, FIND_VALUE 네 가지 유형의 명령을 지원합니다.
PING은 ID에 대한 노드가 온라인인지 여부를 확인하고 STORE는 이러한 데이터를 저장 노드로 전달합니다. FIND_NODE는 ID에 대한 네트워크 노드 정보를 조회하는 것으로, 실제 네트워크 환경에서는 검색된 노드의 ID가 온라인이 아니거나 생성되지 않는 경우가 발생할 수 있기 때문에 노드를 찾는 명령이 검색으로 진화합니다. 검색중인 ID와 가장 가까운 K 노드를 찾습니다. K 노드는 동일한 k-buckets 리스트에서 찾을 수 있거나, k-buckets가 가득 차있는 경우 가장 가까운 k-buckets 리스트를 검색합니다. 모든 k-buckets 리스트의 노드 정보의 숫자가 충분하지 않으면 정보 숫자가 얼마나 되는지를 반환합니다.
FIND_VALUE는 FIND_NODE와 유사하지만 검색 과정에서 K 노드가 발견되기 전에 값(value)을 찾았을 가능성이 있습니다. 일부 값은 캐시되기 때문에 VALUE를 저장하는 노드는 직접 내용을 반환하고 프로세스가 종료됩니다.
위의 네 가지 명령처리에서 모든 메시지 수신자는 네트워크 주소 스푸핑을 방지하기 위해 임의의 RPC ID를 반환합니다.
특정 노드 ID에 가장 근접한 K 개의 노드를 찾을 때, K 목표 노드를 찾기 위해 반복 접근법이 사용됩니다. 우선, 라우팅 테이블로부터, 자신에게 가장 가까운 k-buckets 리스트에 있는 노드를 찾은 후 동시에 조회 요청을 시작합니다. 상기 k-buckets의 예에서 K = 3 이기 때문에 a의 값은 1, 2, 3 입니다. 그러므로 같은 k-bucket을 가지고 물어 보는 것이 가장 좋습니다. a = 1 일 때, 룩업 프로토콜은 Chord 네트워크로 진화합니다. 노드의 정보를 질의함으로써, 검색자는 수용된 질의 결과에 따라 가장 가까운 거리를 갖는 새로 발견 된 노드에 검색 명령을 재전송 할 수 있습니다. K 개의 거리 타겟 탐색 노드들에 가장 가까운 노드들로부터, 탐색 정보를 전송하지 않은 노드를 연속적으로 찾고, 이들에게 탐색 명령을 전송합니다. 이러한 노드가 올바르게 응답하지 않거나 오프라인 상태이면 라우팅 정보 테이블에서 노드 정보가 삭제됩니다. 이 프로세스에서 현재 K 노드보다 대상 노드에 더 가까운 노드가 발견되지 않으면 K 노드로 계속 진행하며 조회 명령을 전송하지 않은 나머지 노드는 계속 조회 명령을 전송합니다. 검색 프로세스는 룩업 노드가 타겟 노드에 가장 근접하게 접촉 할 수 있는 K 노드 정보를 찾으면 종료합니다.
데이터를 저장할 때 가장 가까운 K 개의 거리 키가 있는 노드를 찾고 저장 명령을 보내면 저장된 발신자는 라우팅 데이터의 견고성을 보장하기 위해 24 시간마다 저장 명령을 브로드캐스트합니다.
데이터를 검색하는 과정에서 캐시를 만날 것이고, K 개의 가장 가까운 노드를 찾기 전에 키의 값을 찾을 것 입니다. 그러면 매우 빨리 데이터를 찾을 수 있습니다. 그러나 데이터 과열 즉, 대상 노드에서 캐시까지의 거리에 따라 많은 사람들이 데이터를 캐시하는 것을 막기위헤 주기적으로 캐시 내용이 삭제됩니다. 물론 대상 노드로부터 더 먼 캐시가 더 빨리 삭제됩니다.
전달 된 노드의 모든 요청 및 데이터는 노드가 로컬 라우팅 정보를 업데이트하는 것을 도울 수 있습니다. 그러나 인기없는 라우팅 정보 중 아무도 액세스하지 못하면 데이터가 매우 냉각됩니다. 라우팅 정보가 너무 냉각되는 것을 방지하기 위해 노드는 ID를 하나씩 무작위로 선택하고 그에 대한 검색 요청을 시작합니다. 이것은 노드의 따뜻함을 보장할 수 있습니다. 이 검색 프로세스는 조회되는 ID에 대해 자신과 다른 해당 노드를 업데이트 할 수 있습니다.
네트워크에 새로 결합 된 노드는 이미 네트워크에서 실행중인 노드 하나 이상을 알고 있어야 합니다. 새로운 노드는 먼저 자신의 k-buckets 큐에 알고있는 노드를 추가하고 ID에 대한 조회 요청을 시작합니다. 이런 과정에서 다른 노드가 응답하게 됩니다. 새 노드는 전체 네트워크의 토폴로지를 업데이트하고 다른 노드가 이 최신 노드에 대한 라우팅 정보를 업데이트 합니다.
Kademlia 라우팅 트리 생성 프로세스
k-buckets 라우팅 정보는 이진트리 형식으로 저장됩니다. 이진트리의 생성은 동적이며 이진트리 데이터 구조는 발견된 노드의 ID에 따라 동적으로 조정됩니다. 다음은 동적 생성 프로세스를 설명하기 위한 노드 번호가 0000 인 비어있는 이진트리의 예입니다.
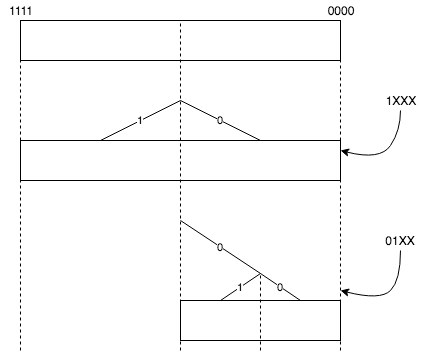
예 1) 새롭게 발견 된 첫 번째 노드 ID 번호의 첫 번째 비트가 1이면, 두 번째 k-buckets가 생성되고, 첫 번째 비트가 ‘1’인 노드 ID의 정보를 저장합니다. 첫 번째 비트가 ‘0’을 갖는 다른 ID, 이 k-buckets ID의 공간은 현재 노드 0000 을 포함합니다.
예 2) 첫 번째 노드의 ID 번호가 새로 발견되면 첫 번째 비트는 ‘0’이고 현재 노드 ID 번호는 0000 의 첫 번째 비트와 같습니다. 하지만 두 번째 비트는 1이며 현재 노드 ID 비트의 두 번째 값이 다릅니다. 이런경우 두 개의 k-buckets이 생성되고 ‘00’ 및 ‘01’로 시작하는 ID 정보를 나타냅니다.
위 내용은 두가지 예로 설명할 수 있습니다.
- 이진트리에서 새롭게 추가된 노드의 ID가 현재 노드 ID를 커버하는 k-buckets 범위 내에 있으면 현재 노드 ID가 있는 영역을 두개의 k-buckets 으로 분할하고 규칙에 따라 새로운 k-buckets 그룹에 가입됩니다.
- 새로 추가된 노드 ID가 현재 노드 ID가 위치한 k-buckets 공간과 다른 경우, 자신에 속한 k-buckets 이진트리에 따라 검색되고, 큐가 가득 찼으면 추가되거나 삭제됩니다.
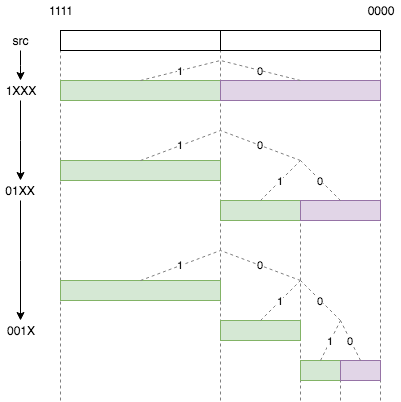
위의 그림은 세 개의 노드가 특정 순서로 추가 될 때 이진트리의 간단한 동적 생성 프로세스를 보여줍니다. 녹색 k-buckets는 노드 ID가 없는 ID 공간을 나타내며 보라색 k-buckets는 노드 ID가 있는 ID 공간을 나타냅니다. 신규 노드의 ID가 현재 ID가 위치하는 ID 공간과 일치하는 경우, 분할 노드의 ID 공간은 2 개의 리프 노드가 됩니다.
네트워크에있는 모든 노드의 ID가 001 로 시작하는 경우 000 을 이 노드에 추가하면 이진트리의 원래 구조는 논리에 따라 삭제해야 합니다. 원래 논리는 k-buckets에서 각 그룹화 노드의 총 수는 K를 초과 할 수 없습니다. 위의 그림에서 노드 0000 의 경우 빨간색 상자의 노드는 k-buckets 통합 표현이어야 하며 버킷이 K 노드를 초과 할 수 없다는 한계를 충족 시키지 몇몇 노드는 삭제해야 합니다. 하지만 이런 경우 라우팅 정보가 손실됩니다. 이 문제를 해결하기 위해 kademlia는 원래의 첫 번째 노드와 새 노드가 생성 된 새로운 이진트리를 생성합니다. 이렇게 하면 새로운 노드 조인 전에 라우팅 구조를 유지 할 수 있습니다.
Key-Value 데이터 저장 장치의 유효성과 장기적인 성질을 보장하기 위해 노드는 주기적으로 키 정보를 브로드캐스팅해야 합니다. 정보가 정기적으로 업데이트되지 않으면 1) Key-Value를 수락하는 노드가 정보를 저장한 후 노드가 오프라인 상태가 되거나 2) 새로운 노드가 온라인 상태이고 ID 값이 현재 K 노드보다 데이터 게시자에 더 가깝지만 데이터에 대한 정보가 없을 수 있습니다. 위의 두 가지 조건으로 인해 데이터가 검색되지 않을 수 있습니다.
이 문제를 해결하기 위해 매시간마다 최신 온라인 상태를 얻기위한 조회 명령을 수행하지 않고 간단한 모델을 사용하여 최적화 프로세스를 훨씬 저렴하게 만들 수 있습니다. 노드가 룩업 명령을 수신하면, 다른 K-1 노드가 동일한 명령을 수신 하였으므로, 명령을 수신 한 노드는 자신의 시간을 업데이트하고 다음 시간에 탐색을 수신하지 않도록 타이밍을 설정합니다. 명령어의 경우에는 실제로 룩업 명령어를 발행하므로 실제로 동일한 시간 내에 특정 데이터 쌍의 룩업 명령어에 대해 하나의 노드만 발행됩니다. 이렇게하면 시스템의 메시지 수가 크게 줄어 듭니다.
또 다른 메커니즘은 k-buckets가 분할 될 때 특정 ID 값의 마지막 K 개 노드의 라우팅 정보를 다시 정렬하고 업데이트하는 것입니다. 이 프로세스는 타이밍 검색의 명령을 어느 정도 완화합니다.
Kademlia 보안
k-buckets가 가득차면 노드를 삭제하기 위하여 큐에서 가장 최신의 링크가 유효한지 확인합니다. 유효한 링크인 경우 새로 추가할 노드를 삭제합니다. 유효한 링크가 아닌 경우 이전의 노드가 삭제되고 새로운 노드가 큐 마지막에 추가됩니다. 그러나 이러한 경우 특정 응용 프로그램이 많은 메시지를 생성하여 네트워크에 문제를 발생하게 할 수 있습니다. 새로 추가된 노드는 실제 대기큐에 추가됩니다. 노드에게 검색 명령을 활용하여 응답여부를 확인하고 응답하지 않은 노드는 삭제되고 대기큐에서 k-buckets에 참가할 노드를 선택하게 됩니다. 이를 위하여 대기큐의 노드를 시간대별로 정하는 전략을 사용합니다. 즉, 시간이 가장 짧은 노드가 가장 빨리 교체되는 것 입니다.
Kademlia는 UDP를 프로토콜로 사용하기 때문에 패킷 손실이나 네트워크 정체로 인한 패킷 지연이 있으며 노드가 제 시간에 응답하지 않으면 RPC 상태 검사가 계속 전송되지 않습니다. RPC 상태 검사에 대한 올바른 응답이 연속 5회 수행되지 않으면 노드는 k-buckets 에서 삭제되지 않지만 관찰 대상으로 표시됩니다. 자체 네트워크의 플래싱으로 인해 노드의 모든 라우팅 정보가 삭제되는 것을 방지하기 위함입니다. 네트워크가 복원되면 라우팅 정보가 업데이트되어야 합니다.
Kademlia는 검색 속도를 높이기 위하여 이진트리를 사용하지 않고 2^b 크기로 분기되는 트리를 사용하여 트리 높이를 줄이고 검색속도를 높입니다. 그러나 이를 위해서는 k-buckets 라우팅 테이블 크기를 늘려야 합니다.
S/Kademlia
S/Kademlia는 악의적 공격에 대비해 두가지 중요한 방식으로 Kademlia를 확장한 디자인입니다. S/Kademlia는 노드ID 생성을 지킬 수 있는 스키마를 제공하여 sybill 공격을 예방합니다. PKI Key-Pair를 생성하기 위해서 노드를 요구하고 이 키에서 아이디를 찾아 서로의 메세지에 서명 할 수 있습니다. 한가지 스키마에는 sybills 를 어렵게 만들기 위한 proof of work 암호화 퍼즐이 포함되어있습니다. S/Kademlia노드는 정직한 노드들이 네트워크 상의 큰 부분의 상대방에게 접속 할 수 있도록 disjoint path에서 값을 탐색합니다. S/Kademlia는 연결에 적대적인 노드가 절반이어도 성공률 0.85정도를 보이고 있다고 합니다.
노드ID 생성을 지킬 수 있는 스키마란 참여노드의 ID를 랜덤 방식을 사용하여 안전하게 생성함을 의미합니다. 공격자는 이러한 ID 생성 규칙을 통과하지 않는한 공격할 수 없습니다. 또한 주변 노드의 ID를 알 수 있는 방법도 없습니다.
서명은 약한서명과 강한서명으로 나뉩니다.
-
약한서명: 노드의 IP 주소, 포트, 타임 스탬프와 같은 메시지 일부를 서명하는 것 입니다. 타임 스탬프 서명에는 유효시간이 지정되어 동적 IP 릴레이 공격 문제를 해결합니다. 약한서명은 메시지 무결성 요구 사항이 요구되지 않는
PING명령에 사용됩니다. -
강한서명: 메시지의 전체 유효성을 보장하고 man-in-the-middle 공격에 효과적으로 대처할 수있는 노드 간 전체 메시지의 서명이며 메시지에 임의의 숫자를 추가하여 릴레이 공격 문제를 해결합니다.
공격에 대비하기 위하여 노드 ID는 랜덤 방식을 이용하고 공개키를 해싱한 ID를 사용하게 되는데 이를 위한 두가지 방식이 존재합니다. 1) 중앙집중식 인증기관을 통한 방식 과 2) 암호화 퍼즐을 통한 노드 ID 생성 방식 입니다.
흔히 CA라고 이야기하는 중앙집중식 인증서 방식은 노드가 거의 없거나, 초기 단계에 사용됩니다. 최초 공개 체인에서 초기 노드의 숫자를 파악하고 이 방식을 채택할지 결정합니다.
완전 분산된 네트워크에서 노드 ID는 매우 어려운 문제를 해결하여야 생성되도록 합니다. 일종의 수수께끼를 풀어야하는 방식인데 크게 두가지 방법이 제공되고 있습니다.
- 첫번째 방법
- 먼저 비대칭 키 쌍을 생성
- 다음 공개 키에 대한 두 가지 해시 작업을 수행
- 생성 된 해시 값보다 C1 비트가 0인지 확인
-
1에서 다시 시작하여 조건이 충족되면 노드의 ID 번호를 공개 키의 기본 해시 값으로 설정
- 두번째 방법
- 노드 ID가 생성 된 후
- 난수 생성
- 노드와 난수 간의 거리를 계산 한 다음 해시 계산
- 만족하지 않으면 해시 값의 c2 비트가 0인지 확인 (조건은 난수를 계속 선택하고 조건이 충족되면 노드 ID와 난수 X가 표시)
- 악의적인 공격자가 NodeId와 난수 x를 만족하는 많은 양의 정보를 생성하기를 원한다면 엄청난 컴퓨터 자원을 소비합니다. 이 기능은 돌이킬 수 없기 때문에 마이닝 프로세스와 비슷한 값을 찾는 것은 매우 리소스 집약적
S/Kademlia 는 아직 IPFS의 Main project에 속해있지 않습니다. 하지만 Locality 와 Security 는 매우 중요한 이슈이며 이를 해결할 수 있는 방안은 반드시 필요합니다.
