opensource serverless-overview
opensource serverless
종류
오픈소스 기반 서버리스 (serverless) 프레임워크는 대표적으로 apache OpenWhisk, OpenFaaS, Ignazio Nuclio, Platform9 Fission, bitnami Kubeless, Fn Project 등이 있다.
이 중 다양한 서비스까지 소개되고 있고 나름 든든한 지원군이 많이 편성된 것이 apache OpenWhisk (IBM Cloud Functions 에 활용) 과 Fn Project (Oracle Fn 에 활용) 이다.
serverless 란 대부분 Event Trigger, Runtime Engine, BackEnd Service 를 구성하고 있으며 docker 또는 Kubernetes 에서 Runtime 및 CLI 를 지원한다.
| 지원 platform | 지원 Runtime Engine | |
|---|---|---|
| OpenWhisk | Kubernetes, MESOS, docker compose, OpenShift | python, go, Java, NodeJS, PHP, Ruby, Scala, Swift |
| OpenFaaS | docker, Swarm, Kubernetes | anything |
| Nuclio | docker, Kubernetes, Azure Container, Google Container | python, go, Java, .NET, NodeJS |
| Fission | kubernetes | python, go, .NET, NodeJS, PHP |
| Kubeless | kubernetes | python, go, .NET, NodeJS, Ruby, PHP, Ballerina |
| FN Project | docker, Swarm, Kubernetes | python, go, Java, NodeJS, Ruby |
1) apache OpenWhisk (https://openwhisk.apache.org)

위의 그림으로 대표되는 OpenWhisk 는 docker 기반 serverless 플랫폼으로 NginX, CouchDB, Kafka, docker container 로 구성된다. 오픈소스 서버리스 중에서 가장 넓은 지원군을 가지고 있다고 생각된다. 그만큼 넓은 프로젝트로서 필요한 구성 요소들을 선택하여 사용할 수 있다. (https://openwhisk.apache.org/documentation.html#project-structure)
2) iguazio Nuclio (https://nuclio.io)
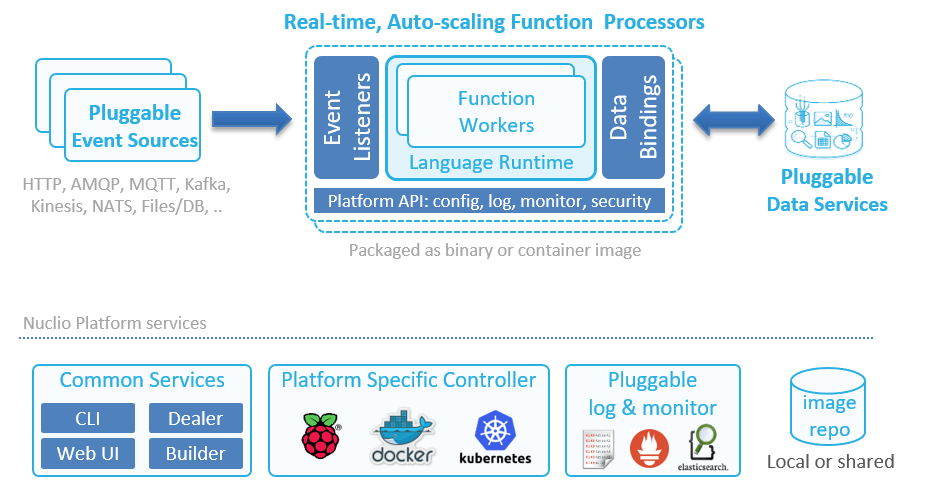
Nuclio 는 HTTP, MQ, Kafka, Kinesis 등 다양한 Event Trigger, RunTime Engine, Pluggable DataBinder 를 제공하는 특징을 가지고 있다. 그 외에 docker, Swarm, Kubernetes, Raspberry Pi 플랫폼을 지원하며 CLI Tool, UI 를 제공하는 서버리스 플랫폼이다.
3) OpenFaaS (https://www.openfaas.com)

OpenFaaS 는 docker, Kubernetes 플랫폼을 지원하고 CLI, Runtime Engine 을 제공하며 Event Trigger 로 API Gateway/Watchdog 을 지원하고, 모니터링을 위한 Prometheus 로 구성된다.
4) bitnami Kubeless (https://kubeless.io)
Kubeless 는 이름처럼 Kubernetes Less 가 아닌 Kubernetes-Native 서버리스 프레임워크의 의미를 가진다. CLI, UI, Runtime Engine, Event Tigger 로 구성되며 Kubernetes 환경에서 쉽게 설치가 가능하고 K8s 명령어를 그대로 활용할 수 있다.
5) Fn Project (http://www.fnproject.io)
Fn Project 도 다른 프레임워크와 마찬가지로 Trigger 에 해당하는 Fn LB, Runtime Engine 인 Fn Server, 데이터 처리를 위한 DataStore, MQ 등으로 구성되어 있다. 구동 환경은 docker 를 이용하고 CLI, FDK (Function Development Kit) 을 제공한다. 별도로 https://github.com/fnproject 에서도 확인가능하다.
6) Platform9 fission (https://fission.io)
Fission 은 Kubernetes-native 서버리스 프레임워크로서 CLI, HTTP/MQ/Timer 등의 Trigger, Runtime Engine 구성으로 이루어지며 Kubernetes 상에서 pod 로 구동된다.
unikernel-overview
unikernel overview
docker 가 세상을 집어삼키듯 거대한 파도가 되었다. openstack 으로 인한 cloud 세상은 점차 container 화 되어가고 있으며 그 정점에 docker 가 있다.
그렇다면 다음 파도는 무엇이될 것인가? 수많은 후보들이 저마다 특색과 장점을 말하고 있으나 unikernel 에 대하여 이야기 하고자 한다.
unikernel 이란?
google 에서 unikernel 이라는 키워드로 검색을 하면 아마도 ‘docker 사의 unikernel systems 인수’ 라는 기사에 가장 먼저 눈이 갈 것이다. 기술적인 내용으로는 2013년에 발표된 논문 Unikernels: Library Operating Systems for the Cloud 또는 Unikernels: Rise of the Virtual Library Operating System 이 매우 유명하다.
unikernel 을 정의한 내용만 뽑아보면 다음과 같다.
특정 application program 을 구동하기 위한 작은 OS, 설정 파일을 하나로 묶은 것
일반적인 application 서비스는 하나의 OS 를 설치한 뒤 그 OS 상에서 복수의 application 또는 service 를 작동시키는 것이 정석이다. unikernel 에서는 복수의 application 또는 service 를 작동시킬 때 OS 와 1 대 1 로 묶여있기 때문에 각 application 또는 service 만 동작시킬 각각의 작은 OS 가 동작한다.
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
|app| |app| |app| |app| |app| |app| |app| |app|
+---+---+---+---+---+---+---+ +---+ +---+ +---+ +---+
| OS | |OS | |OS | | OS| | OS|
+---------------------------+ +---+---+---+---+---+---+---+
| HW | | Hypervisor |
+---------------------------+ +---------------------------+
| HW |
+---------------------------+
<일반적 application 및 OS> <unikernel 상에서 application>
unikernel 의 OS 이미지 파일의 크기는 매우 작다. 예를 들면 50 개의 unikernel OS 가 필요한 상황이 되어도 최대 500mb 정도가 될 수 있다. (Hypervisor 영역을 잡아도 1~2GB)
unikernel 장점
unikernel 공식 페이지를 참조하면 unikernel 의 장점은 4가지로 강조하고 있다.
- Imporved security
- Small footprint
- Highly optimized
- Fast boot
1. Improved security
Small footprint 와 관계가 있다. unikernel 의 OS 이미지 사이즈가 작은 이유는 소스코드 크기 (양) 와 관련있다.
application 만 동작할 수 있는 크기의 작은 OS 를 사용하기 때문이다. 이렇게 되면 외부로 부터 공격받는 부분이 줄어들게 된다. 또한 특정 application 기동을 위한 것으로 보통 OS 레이어에 위치하여 user 라는 개념이 존재하지 않는다. 즉, root 와 같은 슈퍼 유저도 존재하지 않기 때문에 권한에 대한 문제가 없다.
execve() 나 system() 등과 같은 함수도 없기 때문에 CPU 의 NX bit 와 조합해 스택 영역에서 코드 실행을 막으면 Shellcode 와 같은 의도하지 않은 코드 실행이 어려워진다.
하지만 unikernel 실장이 버그에 의해 버퍼 오버플로를 발생시키므로 주의가 필요하다.
2. Small footprint
문장 그대로 unikernel 의 OS 이미지가 작다는 것이다.
이것으로 인해
i) 이용 가능 디바이스 종을 제한 (물리 서버 상에서 직접 동작을 중지하고 특정 하이퍼바이저 상에서 동작하게 함)
ii) application 동작에 필요없는 OS 기능을 OS 이미지에 포함시키지 않음 (Linux kernel module 과 같은 동적 OS 구성 변경)
소형 IoT 디바이스의 OS 로서 unikernel 의 사용 가능성이 높다.
3. Highly optimized
상호 관계가 깊은 코드 양이 적어서 application 레이어에서 OS 레이어에 걸치 폭넓은 최적화를 적용할 수 있다.
4. Fast boot
문장 그대로 기동시간이 매우 짧다. 하이퍼바이저 상에서 움직이는 unikernel 이라고 하여도 BIOS 초기화를 필요로 하지 않는 OS/VM 레이처의 실장이라면 통상의 application 처럼 빠르게 작동된다.
가상 머신에서 격리된 안전한 function 을 동작시켜 FaaS (Function as a Service) 를 실현하기 위한 방법으로 사용될 수 있다.
unikernel 단점
우선 자료도 매우 부족하다. (매뉴얼, git, 튜토리얼 등의 정보 부족) 또한 하이퍼바이저 상에서 동작시키는 unikernel 의 디버깅과 튜닝이 매우 복잡하다.
unikernel 종류
application/service 레이어의 언어, 용도, 플랫폼도 서로 다르다.
언어별
Clive: Go 언어로 작성된 application 으로 베어메탈 환경에서 동작
HaLVM: Haskell 언어로 작성된 application 으로 Xen 환경에서 동작
IncludeOS: C++ 언어로 작성된 application 으로 KVM 환경에서 동작 LING: Erlang/OTP 언어로 작성된 application 으로 Xen 환경에서 동작 MirageOS: OCaml 언어로 작성된 application 으로 베어메탈/Xen/KVM 환경에서 동작 OSv: C/Java/Ruby/Node.js 언어로 작성된 application 으로 Xen/KVM/Virtualbox/VMware 환경에서 동작 runtime.js: Javascript 언어로 작성된 application 으로 KVM 환경에서 동작
용도별
ClickOS: NFV 용도로 사용되며 Xen 환경에서 동작
Hermitcore: HPC 용도로 사용되며 베어메탈/KVM 환경에서 동작
호환성
Rumprun: POSIX application 으로 베어메탈/Xen/KVM 환경에서 동작
Linux
UKL: boston university & RedHat 에 의한 Linux 앱을 위한 unikernel
UniLinux: Linux 와 Ring0 싱글 프로세스에서 동작
Windows
Drawbridge: 윈도우 application, 베어메탈 환경에서 동작
주목할 내용
Unikraft: 라이브러리화 된 기능 모듈을 바탕으로 Konfig 를 이용해 unikernel 작성
자작 application 을 unikernel 로 작성하고 싶다면 언어별 unikernel 을 시험하는 것이 가장 좋다. NFV 혹은 HPC 라는 특정 용도를 목적으로 한다면 ClickOS/Hermitcore 를 사용하는 것이 좋다.
기존의 application 을 unikernel 로 동작하고 싶다면 호환성을 장점으로 가진 Rumprun 이 선택사항이 된다. (이미 Apache Cassandra 예가 있다)
UKL 은 RedHat 이 관여하고 있는 프로젝트이며 기존 프로그램의 쉬운 unikernel 화 라는 장점을 가지고 있다.
아직 시작한지 얼마되지 않은 단계이지만 논문 제목에도 있듯 ‘The Next Stage of Linux’s Dominance’ 가 될지 매우 기대된다.
소개된 위의 종류에서 활발한 활동을 보이는 unikernel 이 있는 반면 활동이 거의 없는 unikernel 이 있으니 실제 사용에는 주의가 필요하다. (홈페이지나 github 의 갱신 상태로 추측이 가능하다.)
Microsoft Research 의 Drawbridge 는 그 자체가 공개적으로 available 되지 않지만 Windows Subsystem for Linux (Window 상에서 Linux 프로그램 동작) 에서 동작한다. SQL Server on Linux (SQL Server 를 Linux 상에서 동작) 에 활용되고 있다.
보안 측면에서 application 레이어에 OCaml (함수형 언어) 이 활발하게 활동하고 있으며 unikernel 은 MirageOS 의 개발 커뮤니티가 활발하게 활동하고 있다.
unikernel 관련 업체
- Docker
- unikernel system 매수 업체, 함께 MirageOS 개발
- Tarides
- 프랑스 업체로 docker 사에서 MirageOS 나 MAC/Windows 에서의 docker 등에 특화
- MirageOS core 개발과 사용 업체를 위한 서포트/개발
- robur
- MirageOS 를 기반으로 SW 를 개발하고 있는 비영리 조직
- nanovms
- Deferpanic 이라는 이름으로 설립된 스타트업으로 Unikernel IaaS 플랫폼 제공
- Zededa
- IoT 용 플랫폼에 Unikernel 적용 (sdxcentral)
- ARM
- MirageOS 는 ARM 아키텍처에서의 동작을 서포트하고 있거나 Unikernel 전용 가상 머신 모니터인 hvt 의 ARM 프로세서 대응에 ARM 사의 엔지니어가 종사
- NEC Laboratories Europe
- ClickOS 나 Unikraft, Uniprof 의 연구
- EMC
- Unik 이라는 Unikernel 개발/관리 툴 개발
- VMWare
- 중국 R&D 팀이 UniLinux 소속으로 개발
- Boston University & RedHat
- Collaboratory 라는 형태로 UKL 의 연구개발
- SAP
- ERP 나 HANA 로 유명한 기업
- 클라우드 앱의 콘텍스트에서 ReasonML 이라는 언어 (Javascript 와 OCaml 의 좋은 점치기 언어) 개발
unikernel 정보
unikernel 웹사이트는 unikernel.org 이다. 또, Unikernel 에 대한 논의는 Unikernel Devel 에서 이루어진다.
Linuxkit
Docker 컨테이너 이미지의 footprint 를 작게 하고 그 컨테이너를 움직이기 위한 작은 LinuxOS 가 포함된 VM 이미지를 작성하는 Linuxkit 이라는 툴이 Moby project (특정 용도의 컨테이너를 낭비하지 않고 개발하기 위한 프레임워크) 에서 개발되고 있다.
DockerCon17 에서 Redis 의 컨테이너가 동작하는 VM 이미지를 작성하고 있는 예가 있다. (SlideShare)
앞으로
다소 생소한 단어이지만 웬지 모두들 생각하고 있었을 unikernel 에 대해 차츰 알아보고자 한다.
GIT - Directory
git directory
1. directory
1.1 Object
object 는 git을 구성하는 데이터파일 같은 것이다. 즉, working directory 파일 정보를 object 형식으로 변환하여 object database ({working directory}/.git/object) 에 저장한다.
각 object 파일은 Zlib을 이용하여 압축며 파일의 내용과 헤더를 40자의 SHA-1 해시값으로 저장한다.
object는 blob, tree, commit, tag 로 세분화 된다.
1.1.1 blob
working directory 파일 즉, 내용이 저장되는 object 이다. blob 에는 파일의 이름이나 형식은 저장되지 않고 파일의 내용 만 저장된다. 쉽게 말하면 이름이 다른 2개의 파일이 프로젝트에 있어도 내용이 같으면 git 은 blob 을 하나만 저장한다는 것을 뜻한다. (물론, clone 이나 fetch 등을 할 경우에도 파일은 하나만 전송된다.)
$ cd .git/objects/
$ ls -al
81/
info/
pack/
$ cd 81/
$ ls -al
78c76d627cade75005b40711b92f4177bc6cfc
.git/objects/ 디렉토리를 확인하면 하위 3개의 디렉토리를 확인할 수 있다. {info}, {pack} 은 git init 할 때 git 이 생성해주는 디렉토리이며 {81} 디렉토리 내부로 들어가 확인하면 파일_(38자리 파일명)_ 이 생성된 것을 확인할 수 있다. git은 40자리 해시를 생성할 때 앞의 2자리를 디렉토리명으로 만들어 파일을 생성한다.
즉, 실제로 생성된 blob의 이름은 8178c76d627cade75005b40711b92f4177bc6cfc 이다.
git 에서 제공하는 cat-file 명령으로 데이터를 확인할 수 있다.
$ git cat-file -p 8178c76d627cade75005b40711b92f4177bc6cfc
readme
$ git cat-file -t 8178c76d627cade75005b40711b92f4177bc6cfc
blob
-p 옵션은 파일의 내용을 확인할 수 있으며 -t 옵션은 타입을 확인할 수 있다. (위 예에서는 README file 의 내용인 ‘readme’ 문자열과 object 의 타입인 ‘blob’ 이 확인됨)
1.1.2 tree
working directory 의 디렉토리 즉, 디렉토리 구조가 저장되는 object 이다. tree 의 내용은 해당 디렉토리 내부의 파일과 디렉토리 정보 (파일명, 형식, SHA-1, …) 를 담은 blob 과 tree object 의 리스트이다.
$ git commit -m 'first commit'
# On branch master
#
# Initial commit
#
1 file changed, 1 insertions(+), 0 deletions(-)
create mode 100644 README
$ cd /home/test/git_example/.git/objects
$ ls -al
72/
81/
b7/
info/
pack/
tree object 를 확인하기 위해서 현재까지 staging area 를 commit 후 object 디렉토리에는 최초 ‘81/’ 디렉토리외에 2개의 디렉토리가 더 생성된 것을 확인할 수 있다.
$ cd b7/
$ ls
7313d7be366609dd2e77aa96d7fd73f4e27853
$ git cat-file -t b77313d7be366609dd2e77aa96d7fd73f4e27853
tree
$ git cat-file -p b77313d7be366609dd2e77aa96d7fd73f4e27853
100644 blob 8178c76d627cade75005b40711b92f4177bc6cfc README
tree object 를 살펴본 위의 예에서 type 은 tree 이며, 내용은 README 파일의 정보를 담고 있음을 확인할 수 있다. 이는 working directory 의 루트 디렉토리 정보를 가지고 있는 tree object 임을 의미한다.
1.1.3 commit
commit history를 저장하고 있는 object 이다.
$ git cat-file -t 721350e7569afabfee7c544c57daf6997f21efba
commit
$ git cat-file -p 721350e7569afabfee7c544c57daf6997f21efba
tree b77313d7be366609dd2e77aa96d7fd73f4e27853
author uni2u <uni2u@mail.address> 1463649969 +0900
committer uni2u <uni2u@mail.address> 1463649969 +0900
first commit
파일 내용을 위의 예와 같이 살펴볼 수 있다. author, committer, commit message 를 포함하고 있으며 내용의 가장 첫번째 줄에 tree object 에 대한 정보가 포함된다. 이 tree object 정보는 해당 commit 스냅샷의 최상단 tree 를 가리키는 포인터 이다. (tree object 즉, 루트의 SHA-1 값을 가리키고 있음을 확인함)
$ echo "test" > test.txt
$ git add *
$ git commit -m 'second'
[master de55b98] second
1 files changed, 1 insertions(+), 0 deletions (-)
create mode 100644 test.txt
$ git cat-file -p de55b98c4a4ce69f04faecd3ffd8bee4983ffb05
tree 8b7d9f48e5f99cce57911e37e88b8fe5b07310dc
parent 721350e7569afabfee7c544c57daf6997f21efba
author uni2u <uni2u@mail.address> 1463652360 +0900
committer uni2u <uni2u@mail.address> 1463652360 +0900
second
위 예와 같이 test.txt 파일을 생성 및 commit 후 해당 commit object 를 찾아서 내용을 보면 parent 가 추가된 것을 볼 수 있다. 이는 현재 commit 바로 직전 commit SHA-1 값을 가리키는 포인터이다. 이 포인터를 통해 git 은 commit 의 부모를 참조할 수 있다.
1.1.4 tag
git 의 특정 commit 에 tag 를 달면 tag object 가 생성된다. tag 는 Lightweight 와 Annotated 로 나뉘는데 Lightweight 는 단순히 특정 commit 에 대한 포인터로 동작하는 반면, Annotated 는 tag 의 작성자, 메일, 날짜, 메시지 등을 저장하고 있으며 보안을 위해 GPG 서명을 포함할 수 있다.
1.2 References
git object 는 한번 생성되면 그 값을 변화할 수 없다. 즉, 파일이 수정되면 새로운 object 가 생성되는 구조이다. 또한 40자리의 SHA-1 코드는 접근하기 어렵다. 이러한 이유로 reference 가 존재한다. 이는 특정 commit 을 가리키는 포인터라는 점에서 tag object 와 유사하지만 reference 는 그 값을 변화할 수 있다. (우리가 이미 git 에서 사용하고 있는 branch, remote, HEAD 같은 요소를 reference 라고 함)
1.3 Data Model
+------+
| HEAD |
+------+
|
V
+------+
|master|
+------+
|
V
+------+ +------+
|commit|<---------|commit|
|721350| |de55b9|
+------+ +------+
| |
V V
+----------+ +----------+
|tree(root)| |tree(root)|
| b77313 | | 8b7d9f |
+----------+ +----------+
| | |
V +---+ V
+------------+ | +--------------+
|blob(README)|<-+ |blob(test.txt)|
| 8178c7 | | 9daeaf |
+------------+ +--------------+
상기 모든 예를 도식화 하면 위의 그림과 같다. 최초 README 파일은 최초 commit 이후 변화가 없기 때문에 두번째 commit 최상의 tree 가 첫번째와 같은 blob 을 가리키고 있고 두번째 commit 에서 새로 생성된 test.txt 만 추가됨을 알 수 있다. 두번째 commit 을 master branch reference 가 가리키고 있고 그 reference 를 다시 HEAD reference 가 바라보고 있다.
이 상태에서 /dir/test.txt/ 가 추가되고, README 파일이 수정된다면 다음과 같다.
+--------+
| HEAD |
+--------+
|
V
+--------+
| master |
+--------+
|
V
+--------+ +--------+ +--------+
| commit |<----------| commit |<--------| commit |
| 721350 | | de55b9 | | bc8aaa |
+--------+ +--------+ +--------+
| | |
V V V
+----------+ +----------+ +----------+
|tree(root)| |tree(root)| |tree(root)|
| b77313 | | 8b7d9f | | d5e2fb |
+----------+ +----------+ +----------+
| | | | | |
V +------+ V +---+ V +------+
+------------+ | +--------------+ | +------------+ | +---------+
|blob(README)|<-+ |blob(test.txt)|<-+ |blob(README)| +->|tree(dir)|
| 8178c7 | | 9daeaf | | c1102f | | 2a6469 |
+------------+ +--------------+ +------------+ +---------+
|
V
+------------------+
|blob(dir/test.txt)|
| dec2cb |
+------------------+
commit object, root tree object 가 생성되어 신규 생성된 dir tree object, README, dir/text blob object 들을 바라보고 있다. git 은 이런 방식으로 commit 이 될 때 마다 비순환 그래프 (DAG: Directed Acyclic Graph) 를 만든다.
1.3.1 branch
위와 같은 저장소에서 branch 를 만들었을 때 git 모델을 보면 다음과 같다. (dev branch 를 git branch dev 명령을 통하여 만들고 checkout 후 README 파일을 수정, commit 했다고 가정)
+--------+
| master |
+--------+
|
V
+------+ +------+ +------+
|commit|<------------|commit|<----------|commit|<---------------------------+
|721350| |de55b9| |bc8aaa| |
+------+ +------+ +------+ |
| | | |
V V V |
+----------+ +----------+ +----------+ |
|tree(root)| |tree(root)| |tree(root)|<---------------------+ |
| b77313 | | 8b7d9f | | d5e2fb | | |
+----------+ +----------+ +----------+ | |
| | | | | | | |
V +------+ V +---+ V +------+ | |
+------------+ | +--------------+ | +------------+ | +---------+ | |
|blob(README)|<-+ |blob(test.txt)|<-+ |blob(README)| +->|tree(dir)| | |
| 8178c7 | | 9daeaf | | c1102f | | 2a6469 | | |
+------------+ +--------------+ +------------+ +---------+ | |
^ | | |
| V | |
| +------------------+ | |
| |blob(dir/test.txt)| | |
| | dec2cb | | |
| +------------------+ | |
| +--------+ |
+--------------------------------+ | |
| V V
+------------+ +----------+ +------+
|blob(README)|<-----|tree(root)|<-----|commit|
| f3aad0 | | 430b43 | |5f6682|
+------------+ +----------+ +------+
^
|
+---+ +----+
|dev|<---|HEAD|
+---+ +----+
commit 하나 추가로 인해 발생한 일련의 도식이다. 새로운 commit object 와 tree object 가 추가되었고, README 파일 내용이 수정되었기 때문에 README blob object 도 새로 생성되었다. 나머지는 변함이 없기 때문에 포인터들이 그대로 가리키고 있다.
1.3.2 merge
이 상태에서 master branch 로 돌아와 dev 를 merge 하면 다음과 같다.
+------+
| HEAD |
+------+
|
V
+------+ +---+
|master| |dev|
+------+ +---+
| |
+---+ +---+
V V
+------+ +------+ +------+ +------+
|commit|<---|commit|<---|commit|<---|commit|
|721350| |de55b9| |bc8aaa| |5f6682|
+------+ +------+ +------+ +------+
새로운 commit object 를 생성하지 않고 master branch 의 포인터만 원래 생성된 commit object 의 SHA-1 값으로 변화하였다. 이는 merge 하기 전의 dev branch 가 가리키는 commit object 가 master branch 가 가리키는 commit object 와 같기 때문이다. 즉, master branch 의 바로 다음 진행이 되어도 무방한 commit 이기 때문에 단순히 branch 의 포인터만 바꾼것으로 merge 가 완료된다. 이를 fast forward 라고 한다.
+------+ +------+ +------+ +------+ +----+
|commit|<---|commit|<---|commit|<---|master|<---|HEAD|
|bc8aaa| |5f6682|<-+ |6e65b4| +------+ +----+
+------+ +------+ | +------+
|
| +------+ +---+
+-|commit|<---|dev|
|946f20| +---+
+------+
위와 같이 dev branch 의 부모 commit 이 master branch 가 아니고 분리가 된 상황에서 다시 merge 를 진행하면 다음과 같다.
+------+ +------+ +------+ +------+ +------+ +----+
|commit|<----|commit|<----|commit|<----|commit|<----|master|<----|HEAD|
|bc8aaa| |5f6682|<-+ |6e65b4| +--|946f20| +------+ +----+
+------+ +------+ | +------+ | +------+
+---+ +---+
| |
V V
+------+ +---+
|commit|<----|dev|
|946f20| +---+
+------+
이 경우는 fast forward 가 되지 않고 새로운 commit 이 하나 생성된 후 master branch 가 해당 commit 으로 옮겨진다. 새로 생성된 commit 은 parent 를 2개 가지고 있는것을 확인할 수 있다. git 의 merge 는 기본적으로 이런 모델로 동작한다.
GIT - Contribute
distribute git
1. contribute
1.1 project contribute
git의 컨트리뷰트 방식은 매우 다양하다. git이 무척 유연하게 설계되었기 때문에 여러 방식으로 사용할 수 있다. 또한 프로젝트 환경에 따라 컨트리뷰트 방식을 다르게 가져갈 수 있기 때문에 이를 간단하게 설명하기에 어려움이 따를 수 있다. 컨트리뷰트 방식에 영향을 미치는 변수를 확인하자면 활발히 컨트리뷰트 하는 개발자의 수, 선택한 워크플로가 무엇인지, 개발자에게 접근 권한을 어떻게 부여하는지, 외부에서 기여할 수 있는지 등이 변수이다.
- 활발히 활동하는 개발자의 수: 얼마나 자주 코드를 생성하는지에 대한 것이 활발한 개발자의 기준이다. 개발자가 많으면 많을수록 코드를 깔끔하게 적용하거나 merge 하기 어려워진다. 어떻해야 코드를 최신으로 유지하면서 원하는 수정을 할 수 있는지 고민하여야 한다.
- 프로젝트에서 선택한 워크플로: 개발자 모두가 메인 저장소에 쓰기 권한을 갖는 중앙집중형, 프로젝트의 모든 patch 를 검사하고 통합하는 관리자가 따로 존재하는 형, 모든 수정사항을 개발자끼리 검토하고 승인하는 형 등
- 접근 권한: 쓰기 권한 및 읽기 권한에 따라 컨트리뷰트 방식이 달라짐 (쓰기 권한이 없다면 수정사항을 어떻게 반영할 수 있는지, 수정사항을 적용하는 정책이 프로젝트에 존재하는지 등)
1.2 commit guide-line
git 프로젝트의 Documentation/SubmittingPatches 문서를 참고하는 것이 좋다.
최우선적으로 공백 문자를 정리하고 commit 하는 것이 좋다. git 은 공백문자를 검사해볼 수 있는 간단한 명령을 제공한다. commit 하기전에 git diff --check 명령으로 공백문자에 대한 오류를 확인할 수 있다.
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)##red maker##
lib/simplegit.rb:7: trailing whitespace.
+##red maker##
lib/simplegit.rb:20: trailing whitespace.
+end##red maker##
(END)
commit 을 하기 전에 공백문자에 대해 검사를 하면 공백으로 불필요하게 commit 되는 것을 막고 불필요하게 다른 개발자들이 신경 쓰는 일을 방지할 수 있다.
commit 은 논리적으로 구분되는 changeset 이다. 최대한 수정사항을 한 주제로 요약할 수 있어야 하고 여러 이슈에 대한 수정사항을 하나의 commit 에 담지 않아야 한다. 여러 이슈를 한꺼번에 수정했다고 하더라도 Staging Area 를 이용하여 한 commit 에 이슈 하나만 담기도록 한다. 작업 내용을 분할하고, 각 commit 마다 적절한 메시지를 작성한다. 같은 파일의 다른 부분을 수정하는 경우에는 git add -patch 명령을 써서 한 부분씩 나누어 Staging Area에 저장해야 한다. 결과적으로 최종 프로젝트의 모습은 한 번에 commit 을 하든 다섯 번에 나누어 commit 을 하든 똑같다.
여러 번 나누어 commit 하는 것이 다른 동료가 수정한 부분을 확인할 때나 각 commit 의 시점으로 복원해서 검토할 때 이해하기 훨씬 쉽다.
마지막으로 commit 메시지를 잘 작성하여야 한다. 메시지의 첫 라인에 50자가 넘지 않는 아주 간략한 메시지를 적어 해당 commit 을 요약한다. 다음 한 라인은 비우고 그다음 라인부터 커밋을 자세히 설명한다. git 개발 프로젝트에서는 개발 동기와 구현 상황의 제약 조건이나 상황 등을 자세하게 요구한다. 이런 점은 따를 만한 좋은 가이드라인이다. 그리고 현재형 표현을 사용하는 것이 좋다. 명령문으로 시작하는 것도 좋은 방법이다. 예를 들어 “I added tests for (테스트를 추가함)” 보다는 “Add tests for (테스트 추가)” 와 같은 메시지를 작성한다.
영문 50글자 이하의 간략한 수정 요약
자세한 설명. 영문 72글자 이상이 되면
라인 바꿈을 하고 이어지는 내용을 작성한다.
특정 상황에서는 첫 번째 라인이 이메일
메시지의 제목이 되고 나머지는 메일
내용이 된다. 빈 라인은 본문과 요약을
구별해주기에 중요하다(본문 전체를 생략하지 않는 한).
이어지는 내용도 한 라인 띄우고 쓴다.
- 목록 표시도 사용할 수 있다.
- 보통 '-' 나 '*' 표시를 사용해서 목록을 표현하고
표시 앞에 공백 하나, 각 목록 사이에는 빈 라인
하나를 넣는데, 이건 상황에 따라 다르다.
1.3 비공개 소규모 팀
두세명으로 이루어진 비공개 프로젝트가 가장 간단한 프로젝트 형태이다. “비공개” 라고 함은 소스 코드가 공개되지 않는 것을 말하는 것이지 외부에서 접근할 수 없는 것을 의미하는 것이 아니다.
이런 환경은 보통 Subversion 같은 중앙집중형 버전 관리 시스템에서 사용하던 방식을 사용한다. 물론 git 이 가진 오프라인 commit 기능이나 브랜치 merge 기능을 이용하긴 하지만 크게 다르지 않다. 가장 큰 차이점은 서버가 아닌 클라이언트 쪽에서 merge 한다는 점이다. 예를들어 두 개발자가 저장소를 공유하는 시나리오를 살펴보면 다음과 같다. 개발자인 John 은 저장소를 clone 하고 파일을 수정하고 나서 로컬에 commit 한다.
# John's Machine
$ git clone john@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'remove invalid default value'
[master 738ee87] remove invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)
개발자인 Jessica 도 저장소를 clone 하고 파일을 하나 추가하고 commit 한다.
# Jessica's Machine
$git clone jessica@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)
Jessica 는 서버에 commit 을 push 한다.
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> master
push 명령을 실행하고 난 결과 중 가장 마지막 줄은 유용한 정보를 보여주고 있다. 마지막 줄의 기본적인 형태는 <oldref>..<newref> fromref -> toref 이다. oldref 는 이전 레퍼런스를, newref는 새 레퍼런스를, fromref 는 push 명령에서 사용한 로컬 레퍼런스의 이름을, toref 는 push 로 업데이트한 리모트 레퍼런스를 나타낸다. 이어지는 내용에서 지금과 비슷한 push 명령 출력 결과는 여러번 등장한다. 이 출력 메시지의 내용을 이해하고 있으면 다양한 상태에서 정확하게 어떤일이 벌어지는가를 좀 더 쉽게 이해할 수 있다. 자세한 내용을 좀 더 살펴보려면 Git 문서 git-push 를 참고한다.
이제 John 도 내용을 변경하고 commit 을 만든 후 서버로 commit 을 push 하려고 한다.
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'
Jessica 의 push 한 내용으로 인해, John 의 commit 은 서버에서 거절된다. Subversion에서는 서로 다른 파일을 수정하는 이런 merge 작업은 자동으로 서버가 처리한다. 하지만 git 은 로컬에서 먼저 merge 해야 한다. 다시 말해 John 은 push 하기 전에 Jessica 가 수정한 commit 을 fetch 하고 merge 해야 한다는 말이다.
이를 위해 우선 John 은 Jessica 의 작업 내용을 아래와 같이 fetch 한다. (아래 명령은 Jessica 의 작업 내용을 내려받긴 하지만 merge 까지 하지는 않는 작업이다)
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master
fetch 하고 나면 John 의 로컬 저장소는 다음과 같이 된다.
+------+
|master|
+---|--+
+-----+ +-----+ +--V--+
|4b078<--|1edee<--|738ee|
+-----+ +--^--+ +-----+
| +-----+
+-----|fbff5|
+--^--+
+------|------+
|origin/master|
+-------------+
이제 John은 Fetch하여 가져 온 Jessica의 작업 내용을 merge 할 수 있다.
$ git merge origin/master
Merge made by the 'recursive' strategy.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
merge 가 잘 이루어지면 John 의 저장소는 아래와 같이 된다.
+------+
|master|
+---|--+
+-----+ +-----+ +-----+ +--V--+
|4b078<--|1edee<--|738ee<--|72bbc|
+-----+ +--^--+ +-----+ +-|-^-+
| +-+ |
| +-----+ | +-------------+
+-----|fbff5<--+ |origin/master|
+-----+ +-------------+
동시에 Jessica 는 토픽 브랜치를 하나 만든다. issue54 브랜치를 만들고 세 번에 걸쳐서 commit 한다. 아직 John의 commit 을 fetch 하지 않은 상황이기 때문에 아래와 같은 상황이 된다.
+------+ +-------+
|master| |issue54|
+---|--+ +----|--+
+-----+ +-----+ +--V--+ +-----+ +-----+ +--V--+
|4b078<--|1edee<--|fbff5<--|8149a<--|23ac6<--|4af42|
+-----+ +-----+ +--^--+ +-----+ +-----+ +-----+
+------|------+
|origin/master|
+-------------+
Jessica 는 John 이 새로 push 했다는 것을 알게 되어 하던 작업을 멈추고 John 의 작업 내용을 살펴보려고 한다. 하지만 아직 Jessica 는 John 의 변경사항을 가지고 있지 않은 상태이다.
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master
위 명령으로 John 이 push 한 commit 을 모두 내려받는다. 그러면 Jessica 의 저장소는 아래와 같은 상태가 된다.
+------+ +-------+
|master| |issue54|
+---|--+ +----|--+
+-----+ +-----+ +--V--+ +-----+ +-----+ +--V--+
|4b078<--|1edee<--|fbff5<--|8149a<--|23ac6<--|4af42|
+-----+ +--^--+ +--^--+ +-----+ +-----+ +-----+
| |
| +--------+
| +-----+ +--|--+
+-----|738ee<--|72bbc|
+-----+ +--^--+
+------|------+
|origin/master|
+-------------+
이제 orgin/master 와 merge 한다. Jessica 는 토픽 브랜치에서의 작업을 마치고 어떤 내용이 merge 되는지 git log 명령으로 확인한다.
$ git log --no-merges issue54..origin/master
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
remove invalid default value
issue54..origin/master 문법은 히스토리를 검색할 때 뒤의 브랜치(origin/master)에 속한 commit 중 앞의 브랜치(issue54)에 속하지 않은 commit 을 검색하는 것이다.
앞의 명령에 따라 히스토리를 검색한 결과 John 이 생성하고 Jessica 가 merge 하지 않은 commit 을 하나 찾았다. origin/master 브랜치를 merge 하게 되면 검색된 commit 하나가 로컬 작업에 merge 될 것이다.
merge 할 내용을 확인한 Jessica 는 자신이 작업한 내용과 John 이 push 한 작업(origin/master)을 master 브랜치에 merge 하고 push 한다.
issue54 토픽 브랜치에 쌓은 모든 내용을 합치려면, 우선 master 브랜치를 checkout 해야 한다.
$ git checkout master
Switched to branch 'master'
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
origin/master, issue54 모두 Upstream 브랜치이기 때문에 둘 중에 무엇을 먼저 merge 하든 상관이 없다. 물론 어떤 것을 먼저 merge 하느냐에 따라 히스토리 순서는 달라지지만, 최종 결과는 똑같다. Jessica 는 먼저 issue54 브랜치를 merge 한다.
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
보다시피 Fast-forward merge 이기 때문에 명령 실행 결과는 별 문제가 없다. origin/master 에 쌓여있던 John 의 작업 내용을 다음과 같이 실행하여 Jessica는 merge 작업을 완료할 수 있다.
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
위와 같이 merge 가 잘 된다면 아래의 상태가 된다.
+-------+ +------+
|issue54| |master|
+---|---+ +----|-+
+-----+ +-----+ +-----+ +-----+ +-----+ +--V--+ |
|4b078<--|1edee<--|fbff5<--|8149a<--|23ac6<--|4af42<---+ |
+-----+ +---^-+ +---^-+ +-----+ +-----+ +-----+ | |
| | | |
+-----+ +-----+ | |
+|----+ +|----+ +|---V+
|738ee<--|72bbc|<-------------------|8059c|
+-----+ +--^--+ +-----+
+------|------+
|origin/master|
+-------------+
origin/master 브랜치가 Jessica 의 master 브랜치로 나아갈 (reachable) 수 있기 때문에 push 는 성공한다. (물론 John 이 그 사이에 push 하지 않았다면)
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
두 개발자의 commit 을 성공적으로 merge 하고 나면 결과는 아래와 같다.
+-------+ +------+
|issue54| |master|
+---|---+ +----|-+
+-----+ +-----+ +-----+ +-----+ +-----+ +--V--+ |
|4b078<--|1edee<--|fbff5<--|8149a<--|23ac6<--|4af42<---+ |
+-----+ +---^-+ +---^-+ +-----+ +-----+ +-----+ | |
| | | |
+-----+ +-----+ | |
+|----+ +|----+ +|---V+
|738ee<--|72bbc|<-------------------|8059c|
+-----+ +-----+ +--^--+
+------|------+
|origin/master|
+-------------+
토픽 브랜치에서 수정하고 로컬의 master 브랜치에 merge 한다. 작업한 내용을 프로젝트의 공유 저장소에 push 하고자 할 때는 우선 origin/master 브랜치를 fetch 하고 merge 한다. 그리고 나서 merge 한 결과를 다시 서버로 push 한다. 이런 워크플로가 일반적이며 아래와 같이 나타낼 수 있다.
+-------+ +------+ +----+
|Jessica| |Server| |John|
+-------+ +------+ +----+
| | |
| | git clone |
| |----------->|
| | |----+
| | | |
| | | git commit
| | | |
| git clone | |<---+
|<-----------| |
+----| | |
| | | |
git commit | | |
| | | |
+--->| | |
| git push | |
|----------->| git fetch |
| |----------->|
| | |----+
| | | |
| | | git merge
| | | |
| | |<---+
| | git push |
| git fetch |<-----------|
|<-----------| |
+----| | |
| | | |
git merge | | |
| | | |
+--->| git push | |
|----------->| git fetch |
| |----------->|
| | |
+-------+ +------+ +----+
|Jessica| |Server| |John|
+-------+ +------+ +----+
1.4 비공개 대규모 팀
비공개 대규모 팀에서는 각각의 작은 팀이 서로 어떻게 merge 하는지가 핵심이다.
John과 Jessica는 “featureA” 기능을 함께 작업하게 됐다. Jessica는 Josie와 함께 “featureB” 기능도 작업하고 있다. 이런 상황이라면 회사는 Integration-manager 워크플로를 선택하는 게 좋다. 작은 팀이 수행한 결과물은 Integration-Manager가 merge 하고 공유 저장소의 master 브랜치를 업데이트한다. 팀마다 브랜치를 하나씩 만들고 Integration-Manager는 그 브랜치를 pull 해서 merge 한다.
두 팀에 모두 속한 Jessica 의 작업 순서를 살펴보자. 우선 Jessica 는 저장소를 clone 하고 featureA작업을 먼저 한다. featureA 브랜치를 만들고 수정하고 commit 한다.
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch 'featureA'
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)
이 수정한 부분을 John 과 공유해야 한다. 공유하려면 우선 featureA 브랜치를 서버로 push 한다. Integration-Manager 만 master 브랜치를 업데이트할 수 있기 때문에 master 브랜치로 push 를 할 수 없고 다른 브랜치로 John 과 공유한다.
$ git push -u origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureA
Jessica 는 자신이 한 일을 featureA 라는 브랜치로 push 했다는 이메일을 John 에게 보낸다. John 의 피드백을 기다리는 동안 Jessica 는 Josie 와 함께 하는 featureB 작업을 하기로 한다. 서버의 master브랜치를 기반으로 새로운 브랜치를 하나 만든다.
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch 'featureB'
몇 가지 작업을 하고 featureB 브랜치에 commit 한다.
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
그럼 Jessica 의 저장소는 그림 아래와 같다.
+------+ +--------+
|master| |featureA|
+---|--+ +--|-----+
+-----+ +--V--+ +--V--+
|4b078<--|1edee<--|33009|
+-----+ +--^--+ +-----+
+--|--+ +-----+
|e5b0f<--|85127|
+-----+ +--^--+
+--|-----+
|featureB|
+--------+
작업을 마치고 push 하려고 하는데 Jesie 가 이미 “featureB” 작업을 하고 서버에 featureBee 브랜치로 push 했다는 이메일을 보내왔다. Jessica는 Jesie 의 작업을 먼저 merge 해야만 push 할 수 있다. merge 하기 위해서 우선 git fetch 로 fetch 한다.
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBee
Jessica 가 앞서 checkout 한 featureB 브랜치에서 작업중일 때, fetch 해 온 브랜치를 git merge 명령으로 merge 한다.
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)
이 시점에서 Jessica 는 merge 한 “featureB” 작업을 서버로 push 할 때 서버의 featureB 브랜치로 push 하지 않고자 한다. 이미 Josie 가 생성한 featureBee로 작업 내용을 push 하러면 아래와 같이 실행한다.
$ git push -u origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBee
명령에서 사용한 -u옵션은 --set-upstream 옵션의 짧은 표현인데 브랜치를 추적하도록 설정해서 이후 Push 나 Pull 할 때 좀 더 편하게 사용할 수 있다.
John 이 몇 가지 작업을 하고 나서 featureA 에 push 했고 확인해 달라는 내용의 이메일을 보내왔다. Jessica 는 John 의 작업 내용을 확인하기 위해 다시 한 번 git fetch 로 push 된 작업을 fetch 한다.
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureA
Jessica 의 로컬 featureA 브랜치와 fetch 해 온 John 의 작업내용이 같은 featureA 브랜치 상에서 어떤 것이 업데이트됐는지 git log 명령으로 확인한다.
$ git log featureA..origin/featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25
확인을 마치면 로컬의 featureA 브랜치로 John 의 작업 내용을 다음과 같이 merge 한다.
$ git checkout featureA
Switched to branch 'featureA'
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Jessica 는 일부 수정하고, featureA 브랜치에 commit 하고, 수정한 내용을 다시 서버로 push 한다.
$ git commit -am 'small tweak'
[featureA 774b3ed] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureA
위와 같은 작업을 마치고 나면 Jessica 의 저장소는 아래와 같은 모습이 된다.
+---------------+
|origin/featureA|
+------------|--+
+------+ +-----V--+
|master| |featureA|
+---|--+ +-----|--+
+-----+ +--V--+ +-----+ +-----+ +--V--+
|4b078<--|1edee<--|33009<--|aad88<--|774b3|
+-----+ +-^-^-+ +-----+ +-----+ +-----+
| | +-----+ +-----+ +-----+
| +----|e5b0f<--|85127<--|cd685|
| +-----+ +-----+ +-|-^-+
| +-----+ | |
+----------|fba9a<---------+ |
+-----+ +------|-+
|featureB|
+------|-+
+---------------|-+
|origin/featureBee|
+-----------------+
그럼 featureA 와 featureBee 브랜치가 프로젝트의 메인 브랜치로 merge 할 준비가 되었다고 Integration-Manager에게 알려준다. Integration-Manager가 두 브랜치를 모두 merge 하고 난 후에 메인 브랜치를 fetch 하면 아래와 같은 모양이 된다.
+---------------+
|origin/featureA|
+------------|--+
+------+ +-----V--+ +-------------+
|master| |featureA| |origin/master|
+---|--+ +-----|--+ +--|----------+
+-----+ +--V--+ +-----+ +-----+ +--V--+ +--V--+
|4b078<--|1edee<--|33009<--|aad88<--|774b3<--|5399e|
+-----+ +-^-^-+ +-----+ +-----+ +-----+ +--|--+
| | +-----+ +-----+ +-----+ |
| +----|e5b0f<--|85127<--|cd685<-----+
| +-----+ +-----+ +-|-^-+
| +-----+ | |
+----------|fba9a<---------+ |
+-----+ +------|-+
|featureB|
+------|-+
+---------------|-+
|origin/featureBee|
+-----------------+
수많은 팀의 작업을 동시에 진행하고 나중에 merge 하는 기능을 사용하려고 다른 버전 관리 시스템에서 git 으로 바꾸는 조직들이 많아지고 있다. 팀은 자신의 브랜치로 작업하지만, 메인 브랜치에 영향을 끼치지 않는다는 점이 git 의 장점이다. 아래는 이런 워크플로를 나타내고 있다.
+-------+ +-----+ +----+ +--------+ +----------+
|Jessica| |Josie| |John| |server: | |server: |
| | | | | | |featureA| |featureBee|
+---|---+ +--|--+ +--|-+ +---|----+ +-----|----+
| | | | |
+---| | | | |
(A) | | | | | |
git commit | | | | |
| | | | | |
+-->| git push origin featureA | |
|----------------------------------->| |
| +---| | | |
| (A) | | | | |
| git commit | | | |
| | | | | |
| +-->| git fetch origin | |
| |<----------------------| |
| +---| | | |
| (A) | | | | |
| git merge | | | |
| | | | | |
| +-->| git push origin featureA |
| |---------------------->| |
| | +---| | |
| | (B) | | | |
| | git commit| | |
| | | | | |
| | +-->| git push origin featureBee |
| | |--------------------------->|
+---| | | | |
(B) | | | | | |
git commit | | | | |
| | | | | |
+-->| git fetch origin |
|<----------------------------------------------------|
+---| | | | |
(B) | | | | | |
git merge | | | | |
| | | | | |
+-->| git push origin featureB:featureBee |
|---------------------------------------------------->|
| git fetch origin | |
|<-----------------------------------| |
+---| | | | |
(A) | | | | | |
git marge | | | | |
| | | | | |
+-->| | | | |
+---| | | | |
(A) | | | | | |
git commit | | | | |
| | | | | |
+-->| git push origin featureA | |
|----------------------------------->| |
| | | | |
+---|---+ +--|--+ +--|-+ +---|----+ +-----|----+
|Jessica| |Josie| |John| |server: | |server: |
| | | | | | |featureA| |featureBee|
+-------+ +-----+ +----+ +--------+ +----------+
1.5 공개 프로젝트 Fork
공개 팀을 운영할 때는 모든 개발자가 프로젝트의 공유 저장소에 직접적으로 쓰기 권한을 가지지는 않는다. git 호스팅에서 fork 를 통해 프로젝트에 contribute 한다.
우선 처음 할 일은 메인 저장소를 clone 하는 것이다. 그리고 나서 토픽 브랜치를 만들고 일정 부분 기여한다. 그 순서는 아래와 같다.
$ git clone <url>
$ cd project
$ git checkout -b featureA
... work ...
$ git commit
... work ...
$ git commit
일단 프로젝트의 웹사이트로 가서 Fork 버튼을 누르면 원래 프로젝트 저장소에서 갈라져 나온, 쓰기 권한이 있는 저장소가 하나 만들어진다. 그러면 로컬에서 수정한 commit 을 원래 저장소에 push 할 수 있다. 그 저장소를 로컬 저장소의 리모트 저장소로 등록한다. 예를 들어 myfork로 등록한다.
$ git remote add myfork <url>
등록한 리모트 저장소에 push 한다. 작업하던 것을 로컬 저장소의 master 브랜치에 merge 한 후 push 하는 것보다 리모트 브랜치에 바로 push 하는 방식이 훨씬 간단하다. 이렇게 하는 이유는 관리자가 토픽 브랜치를 프로젝트에 포함시키고 싶지 않을 때 토픽 브랜치를 merge 하기 이전 상태로 master 브랜치를 되돌릴 필요가 없기 때문이다. 관리자가 토픽 브랜치를 merge 하든 rebase 하든 Cherry-Pick 하든지 간에 결국 다시 관리자의 저장소를 pull 할 때는 토픽 브랜치의 내용이 들어 있을 것이다.
어떤 경우라도 다음과 같이 작업 내용을 push 할 수 있다.
$ git push -u myfork featureA
fork 한 저장소에 push 하고 나면 프로젝트 관리자에게 이 내용을 알려야 한다. 이것을 Pull Request 라고 한다. git 호스팅 사이트에서 관리자에게 보낼 메시지를 생성하거나 git request-pull명령으로 이메일을 수동으로 만들 수 있다.
git request-pull 명령은 아규먼트를 두 개 입력받는다. 첫 번째 아규먼트는 작업한 토픽 브랜치의 Base 브랜치이다. 두 번째는 토픽 브랜치가 위치한 저장소 URL인데 위에서 등록한 리모트 저장소 이름을 적을 수 있다. 이 명령은 토픽 브랜치 수정사항을 요약한 내용을 결과로 보여준다. 예를 들어 Jessica 가 John 에게 pull 요청을 보내는 상황을 살펴보자. Jessica 는 토픽 브랜치에 두 번 commit 을 하고 fork 한 저장소에 push 했다. 그리고 아래와 같이 실행한다.
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
Jessica Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
관리자에게 이 내용을 보낸다. 이 내용에는 토픽 브랜치가 어느 시점에 갈라져 나온 것인지, 어떤 commit 이 있는지, pull 하려면 어떤 저장소에 접근해야 하는지에 대한 내용이 들어 있다.
프로젝트 관리자가 아니라고 해도 보통 origin/master 를 추적하는 master 브랜치는 가지고 있다. 그래도 토픽 브랜치를 만들고 일을 하면 관리자가 수정 내용을 거부할 때 쉽게 버릴 수 있다. 토픽 브랜치를 만들어서 주제별로 독립적으로 일을 하는 동안에도 주 저장소의 master 브랜치는 계속 수정된다. 하지만 주 저장소의 브랜치의 최근 commit 이후로 rebase 하면 깨끗하게 merge 할 수 있다. 그리고 다른 주제의 일을 하려고 할 때는 앞서 push 한 토픽 브랜치에서 시작하지 말고 주 저장소의 master 브랜치로부터 만들어야 한다.
$ git checkout -b featureB origin/master
... work ...
$ git commit
$ git push myfork featureB
$ git request-pull origin/master myfork
... email generated request pull to maintainer ...
$ git fetch origin
각 토픽은 일종의 실험실이라고 할 수 있다. 각 토픽은 서로 방해하지 않고 독립적으로 수정하고 rebase 할 수 있다.
+------+ +-------------+
|master| |origin/master|
+---|--+ +---|---------+
V V
+-----+ +-----+ +-----+
|4b078<--|1edee<--|33009|
+-----+ +-^-^-+ +-----+
| | +-----+ +-----+ +--------+
| +----|a2de3<--|0d708<--|featureA|
| +-----+ +-----+ +--------+
| +-----+ +--------+
+------|e5b0f<--|featureB|
+-----+ +--------+
프로젝트 관리자가 사람들의 수정 사항을 merge 하고 나서 Jessica 의 브랜치를 merge 하려고 할 때 충돌이 날 수도 있다. 그러면 Jessica 가 자신의 브랜치를 origin/master 에 rebase 해서 충돌을 해결하고 다시 pull request 를 보낸다.
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureA
위 명령들을 실행하고 나면 히스토리는 아래와 같아진다.
+------+ +-------------+
|master| |origin/master|
+---|--+ +---|---------+
V V
+-----+ +-----+ +-----+
|4b078<--|1edee<--|33009<-----+
+-----+ +--^--+ +-----+ +--|--+ +-----+ +--------+
| |dee6b<--|5399e<--|featureA|
| +-----+ +-----+ +--------+
| +-----+ +--------+
+-----|e5b0f<--|featureB|
+-----+ +--------+
브랜치를 rebase 해 버렸기 때문에 push 할 때 -f 옵션을 주고 강제로 기존 서버에 있던 featureA브랜치의 내용을 덮어 써야 한다. 아니면 새로운 브랜치를(예를 들어 featureAv2) 서버에 push 해도 된다.
또 다른 시나리오를 하나 더 살펴보자. 프로젝트 관리자는 featureB 브랜치의 내용은 좋지만, 상세 구현은 다르게 하고 싶다. 관리자는 featureB 담당자에게 상세 구현을 다르게 해달라고 요청한다.featureB 담당자는 하는 김에 featureB 브랜치를 프로젝트의 최신 master 브랜치 기반으로 옮긴다. 먼저 origin/master 브랜치에서 featureBv2 브랜치를 새로 하나 만들고, featureB 의 commit 들을 모두 squash 해서 merge 하고, 만약 충돌이 나면 해결하고, 상세 구현을 수정하고, 새 브랜치를 push 한다.
$ git checkout -b featureBv2 origin/master
$ git merge --squash featureB
... change implementation ...
$ git commit
$ git push myfork featureBv2
--squash 옵션은 현재 브랜치에 merge 할 때 해당 브랜치의 commit 을 모두 commit 하나로 합쳐서 merge 한다. 이 때 merge commit 은 만들지 않는다. 다른 브랜치에서 수정한 사항을 전부 가져오는 것은 똑같다. 하지만 새로 만들어지는 commit 은 부모가 하나이고 commit 을 기록하기 전에 좀 더 수정할 기회도 있다. 다른 브랜치에서 수정한 사항을 전부 가져오면서 그전에 추가적으로 수정할 게 있으면 수정하고 merge 할 수 있다. 게다가 새로 만들어지는 commit 은 부모가 하나다. --no-commit 옵션을 추가하면 commit 을 합쳐 놓고 자동으로 commit 하지 않는다.
수정을 마치면 관리자에게 featureBv2 브랜치를 확인해 보라고 메시지를 보낸다.
+------+ +-------------+
|master| |origin/master|
+---|--+ +--|----------+
| | +-----+ +----------+
V V |17f4d<--|featureBv2|
+-----+ +-----+ +-----+ +-|---+ +----------+
|4b078<--|1edee<--|33009<----+
+-----+ +--^--+ +--^--+
| | +-----+ +-----+ +--------+
| +-----|dee6b<--|5399e<--|featureA|
| +-----+ +-----+ +--------+
| +-----+ +--------+
+-----|e5b0f<--|featureB|
+-----+ +--------+
NDN - Tutorial
NDN Tutorial
1. How NDN works
1.1 An example scenario: smart homes
- 온도, 카메라, 조명 등 조절
- IP solution
- 정보를 얻기 위한 주소(address)를 알아야 함
- 온도 조절기, 카메라, 홈 컨트롤러
- 특정 주소로 request 를 보냄
- 정보를 얻기 위한 주소(address)를 알아야 함
- NDN solution
- 대상을 지정하지 않고 명시적으로 데이터 요청을 보냄
1.2 Data Packet
- NDN 아키텍처의 가장 핵심적인 구성 요소
+------------------+ 콘텐츠를 고유하게 식별
| NAME | eq) /UCLA/BH234/temperature/timestamp
| |
+------------------+ info to help common data consumtion
| MetaInfo | eq) FreshnessPeriod
| |
+------------------+
| Content | Can be anything
| |
+------------------+
| Signature | Signed by the data producer
| |
+------------------+
- 데이터는 변경 불가능한 객체
- 내용이 변경되면 서명뿐만 아니라 이름도 변경되어야 함
1.3 Interest Packets
- 데이터를 검색하기 위해 interest 전송
+----------------------+ interest에 대한 data는 무엇인가
| NAME | eq) /UCLA/BH234/temperature
| |
+----------------------+ 데이터 선택 범위를 좁힘
| Selectors (optional) | (narrow down data selection)
| |
+----------------------+ 동일한 name을 가진
| Nance | interest를 구별하는 난수
| |
+----------------------+
|InterestLifeTime, etc.|
| (optional) |
+----------------------+
1.4 Basic communication
- 소비자(Consumer)는 데이터(Data)를 Pull
- one interest for one data packet
- interest 와 data name은 반드시 match
- 속도 제어, 데이터 검증, 손실 탐지 및 복구, 다른 네트워크 인터페이스 탐색 등
- 데이터(Data) 생산자(production)
- Naming
- Signing
- 필요한 경우 Segmentation
1.5 It’s all about names
- Data 와 Interest는 name을 가지고 있음 (no address; no port)
- Name이 모든 차이점을 만든다: benefits & challenges.
- Name은 application 별로 각 패킷에 할당, eq)
- /UCLA/RoyceHall/ARFeed/FrontView/mp4/_frame=12/_chunk=20
- Name은 계층적(hierarchical) 구성
- name aggregation이 용이함
- 데이터 소비를 위한 application 컨텍스트 보존 (eq: security)
- 충돌을 피하고 communication을 원활하게하기 위한 Naming 규칙
1.6 The role of names
- Name은 여러 레이어에서 디멀티플렉서로 사용
- 각 레이어가 자체 식별자 (eq: address, port), 관리 및 상호 간의 식별자를 가질 필요가 없음
- 다중 인터페이스 및 이동성의 경우 특정 주소 또는 포트에 바인딩되지 않음
- Auto-configuration 및 auto-discovery
- /_ThisRoom/Projector/command/TurnOn/…
- Naming은 application 프로토콜 설계의 주요 부분
- Naming 규칙을 알고 나면 모든 application에서 이 규칙을 사용하여 프로젝터에 액세스
1.7 Name Discovery
- 소비자 application은 data name에 대해 어떻게 알 수 있는가?
- 일반적으로 name prefix는 알고 있지만 완전한 name을 아는 것이 아님
- In-network name discovery
- 선택자(Selection)를 사용하여 선택 범위를 좁힐 수도 있음
+-------------+ /UCLA/BH234/temp +-------------+
| | -----------------------------------> | |
| application | /UCLA/BH234/temp/2017082109/_chunk=0 | producer |
| | <----------------------------------- | |
| | /UCLA/BH234/temp/2017082109/_chunk=1 | |
+-------------+ -----------------------------------> +-------------+
- 특정 시나리오에 대한 기타 검색 메커니즘
- eq) 관련 데이터의 알려진 name을 나열된 Manifest
1.8 Data-centric security
- internet 환경에서 connection 보안을 아무리 설정하여도 서버 해킹의 위험성이 남아있음
- NDN에서 생산자는 데이터에 서명하여 소비자가 불량 데이터를 얻는 시점을 알 수 있음
1.9 Authentication of NDN Data
+---------------------+
| /UCLA/RoyceHall/... |
| <data> |
| |
| +----------------------------+
| |KeyLocator: |
| |/UCLA/RoyceHall/Manager/KEY |
| +----------------------------+
+---------------------+
|
|
+--<Signed by>--+
|
V
+------------------+
| /UCLA/RoyceHall/ |
| Manager/KEY |
| |
| +-------------------------+
| |KeyLocator: |
| |/UCLA/Campus/Manager/KEY |
| +-------------------------+
+------------------+
- Key는 Named 데이터이며 다른 데이터와 마찬가지로 검색되고 보호
1.10 Name-based trust relationship and policy
+--------------------------------+
| /UCLA/Campus/Manager/Key |
+---------------^----------------+
|
| valid if signed by
|
+--------------------------------+
| /UCLA/RoyceHall/Manager/Key |
+---------------^----------------+
|
| valid if signed by
|
+--------------------------------+
| /UCLA/RoyceHall/CameraFeed/... |
+--------------------------------+
- 데이터가 유효하려면 특정 키로 서명
- 체인은 application의 신뢰 앵커로 연결
1.11 Trust Schema: Name-Based Definition of Trust Model
- 데이터의 이름과 서명 키의 이름 사이의 관계를 체계화하여 신뢰 모델 구성
<> <CONST>
token* token?
[func]
(:group:token)
+-----------------------+
| Local trust anchor(s) |
+-----------------------+
|
V +-----+
+-----------+ |
| Key1 Rule | <--+
+-----------+
| |
+-----+ +-----+
| |
V V
+-----------+ +-----------+
| Key2 Rule | <---- | Key3 Rule |
+-----------+ +-----------+
| |
V V
+---------------+ +---------------+
| Interest Rule | | Data Rule |
+---------------+ +---------------+
1.12 Trust Schema as a Bag of Bits
- 기본 NDN 메커니즘을 사용하여 배포
- 다른 모든 데이터 패킷도 보안
- 신뢰 스키마 데이터 성능
- 휴대 전화는 수신 비디오 피드 데이터를 안정적으로 확인
- 카메라가 비디오 피드 데이터에 서명
- 카메라는 휴대 전화에서 command 유효성 검사
- 라우터는 데이터 유효성 검사하고 요청을 인증
1.13 From a single node’s point of view
Traditional Networks
+-----------------------------+
| Accept |
| ^ |
| | |
| +---------+ X +-----+ |
Packets ----> | Dest? | ----> | FIB | ---->
| +---------+ +-----+ |
+-----------------------------+
----------------------------------------------------
NDN Networks
+-------------------------------+
| Return Data |
| ^ |
| | |
| +-----------+ X +-----+ |
Interests ----> | Got Data? | ----> | FIB | ---->
| +-----------+ +-----+ |
+-------------------------------+
+-------------------------------+
| +-----------------------+ |
<----- | Pending Interest? | <----- Data
| +-----------------------+ |
+-------------------------------+
1.14 Forwarding Table (FIB)
- name-prefixes 와 해당하는 next-hops 저장(stored)
- e.g., /UCLA
- incoming Interest’s name 과 longest prefix 매치 수행
- e.g., /UCLA/RoyceHall/…
- 다른 데이터 소스로 이어질 수 있는 여러 개의 next-hops
- 특정 목적지가 아닌 데이터를 향해 전달
- NDN은 루프에 대해 걱정할 필요가 없으므로 더 많은 forwarding
1.15 Building FIB
- application은 데이터의 name-prefix를 로컬 노드에 등록
- 전통 라우팅 알고리즘
- 네트워크에 name-prefix를 어나운스
- e.g., link state
- “비 전통적인” 라우팅 알고리즘
- 기본 NDN 네트워크 활용
- e.g., Hyperbolic Routing
- Flooding-based learning
- Flood initial interest, 데이터 출처 관찰 및 FIB 항목 추가
- local, ad-hoc 환경에 적합
1.16 Content Store (CS)
- 모든 노드는 NDN에 의해 데이터 캐시
- Transparent
- In-Network
- On-path
- 장점
- ISP의 중복 트래픽 줄임
- 제작자의 서버 부하 줄임 (특히 공격하는 동안)
- 소비자의 응답 시간을 줄임
- RTT의 시간 규모에서도 손실 복구 및 이동성 지원
- 데이터 생산과 데이터 소비 분리
- 자연스럽게 DTN 유형의 통신 지원
1.17 Pending Interest Table (PIT)
+---+
| A | <----DATA----+
+---+ |
| |
+--INTEREST--+ | +--------DATA-------+
V | V |
+-----------+ +---+
| PIT | | |
+-----------+ +---+
^ | | ^
+--INTEREST--+ | +------INTEREST-----+
| |
+---+ |
| B | <----DATA----+
+---+
- 소비자에게 Data를 보내기 위한 NDN
- 각 항목 기록 (name, nonce, incoming faces)
- 새로운 interest가 전송 될 때 생성
- 동일한 Name을 가진 interest가 더 많이 도착하면 업데이트
- 일치하는 데이터가 반환되면 삭제
1.18 Benefits of PIT
- Native multicast
- 멀티 캐스트와 유니 캐스트 작업간에 차이가 없음
- 중복 패킷 억제 e.g) forwarding loops로 인해 발생
- mobile, ad hoc communication에 중요
- 모든 홉에서 데이터 검색의 success/performance에 대한 closed-loop로 피드백 제공
+---+ +---+ +---+ +---+
| | --INTEREST--> | | --INTEREST--> | | --INTEREST--> | |
| | | R | X | R | | |
| | <----DATA---- | | <----DATA---- | | <----DATA---- | |
+---+ +---+ +---+ +---+
-------------------------------------------------------------------
+---+ +---+ X +---+ +---+
| | ---Packet---> | | ---Packet---> | | ---Packet---> | |
+---+ +---+ +---+ +---+
1.19 Forwarding Strategy
- FIB는 여러 Forwarding 옵션 제공
- PIT는 오류 감지 및 성능 피드백을 가능하게함
- 위의 내용을 토대로 Forwarding Strategies는 데이터 검색에 가장 적합한 전달 결정
- e.g., 경로 변경을 최소화하거나 최단 지연을 찾거나 높은 처리량을 찾거나 항상 multicast/broadcast 등
+---+
+----INTEREST----> | R |
| +---+
| |
+---+ <------DATA------+
----INTEREST---> | R |
+---+
| +---+
+--X--INTEREST --> | R |
+---+
1.20 Summary of how NDN works
- 데이터는 Name으로 식별(identified)되고 생산자가 서명(signed)
- interest는 일치하는 데이터를 검색하기 위해 Name을 포함
- 데이터 중심 보안 및 Name 기반 신뢰 스키마
- in-network caching, native multicast, 다목적 forwarding 전략(strategies)을 지원하는 상태 저장(stateful) data-plane
2. Open Research Problems
2.1 NDN Research
- NDN은 새로운 네트워크 아키텍처
- 기존의 point-to-point conversation 에서 분산 데이터(distributed data) 생성, 검색(retrieval) 및 소비(consumption)에 이르기까지
- 내장 보안(built-in security)과 함께 응용 프로그램과 네트워크에 대한 재고(rethinking)가 필요
- 특정 네트워크 환경에서 NDN 작동?
- NDN의 기능을 최대한 활용하는 방법?
- NDN의 성능을 최적화하는 방법?
- 응용 프로그램, 보안 및 네트워크의 주요 연구 문제
2.2 Applications
- NDN은 네트워크 의미론(network semantics)을 응용 프로그램 의미론에 가깝게 함
- 데이터 중심의 앱 디자인이 NDN을 최대한 활용
- 우리는 응용 프로그램을 작성하여 네트워크 아키텍처 연구를 추진
- 특히, 분산 컴퓨팅을 위한 현재 cloud-centric 패러다임 (동적 대기 시간이 적은 모바일 앱을 지원하지 못하고 있는) 에 대한 클라우드 지원 대안
2.3 Namespace Design
- Data Namespace 디자인은 앱 디자인의 핵심 요소
- 데이터 액세스, 전달, 보안 및 이름에 대한 다른 요구 사항 수집
- Home IoT 사례
- Name data, 작동 포인트, 장치, keys/certificates, 액세스 제어 정책
- 종종 네 부분으로 된 이름: /A/B/C/D
- A: 데이터 도달 방법 (e.g., localhop, home-guid, /edu/ucla 등)
- B: 상위 수준 식별자 (e.g., living_room/temperature)
- C: 파생 또는 관련 데이터 식별자 (e.g., KEY, _mimetype)
- D: 유형별 접미사(suffixes) (e.g., 세그먼트 또는 일련 번호, 버전 등)
- 데이터 패킷의 Keylocator: 신뢰와 관련된 또 다른 Name
2.4 Application APIs
- API 및 앱 개념 변화:
- 소비자 중심: 데이터 push 보다 pull
- client/server 가 아닌 비동기 다중 노드 (Asynchronous multi-node) 데이터 보급
- 로컬 및 글로벌 통신에 동일한 메커니즘 사용
- Home IoT 사례
- 기본 프리미티브로 검색(retrieval) 및 활성화(actuation) 가능
- Discovery & bootstrapping은 기본 프리미티브(basic primitives) + 이름 규칙(name conventions) 을 사용하여 구현할 수도 있음
- 계층 구조 이름(hierarchical name) 은 다른 계층에서도 공통적
- Layer3 의 NDN
2.5 Usable Security
-
앱 데이터 보안은 근본부터 구축 될 수 있지만 접근 방식과 도구는 새롭고 쉽게 사용할 수 있어야 함
-
Home IoT 사례
- 체계화된 신뢰(schematized trust): 사용하기 쉬운 규칙과 더 많은 예제가 필요함
- Name-based access control: 많은 옵션으로 이름만으로 개념화하기 어려움
2.6 Research problems & approaches
- 네트워크가 응용 프로그램에 제공하는 공개 질문
- Network storage (e.g: repo)
- Indirection (e.g: NDNS)
- Handling mobile publishers
- Home IoT 사례
- “Memory content cache”는 영구 튜플 저장소로 쉽게 확장
- Certificate storage, name redirection, could는 인프라에 포함될 수 있음
- 홈 네트워킹에서 차량 네트워킹에 이르기까지
- 멀티 홈, 모바일
- Local, neighborhood, global data
2.7 Data Access Control
- 데이터 검색(retrieval)과 데이터 액세스 제어 분리
- 누구든지 검색 할 수 있는 데이터를 암호화
- 암호 해독 키에 대한 액세스 제어
- 정확한 메커니즘 설계는 네트워크 환경 (e.g., resource constrained devices) 에 따라 다양한 옵션이 있을 수 있음
2.8 DDoS and Content Poisoning
- NDN 아키텍처는 IP보다 DDoS 공격에 탄력적
- 피해자가 기존 데이터에 대한 interest를 가진다면 효과적이지 않음
- 공격 할 수있는 유일한 방법은 라우팅 가능하지만 존재하지 않는 데이터에 대해 interest flooding 하는 것이지만 PIT 행동에서 탐지
- Content Poisoning
- 기본적으로 라우터는 성능상의 이유로 데이터를 확인하지 않음
- 소비자가 위조 된 데이터를 수신하고 라우터가 데이터를 검색하는 경우 문제가 발생할 수 있음
2.9 Infrastructure-less environments
- 신뢰할 수 있는 고정 인프라가 없는 네트워크 환경
- Mobile, ad hoc, wireless device-to-device, delay-tolerant network, 재난 복구 등
- NDN 장점이 활용될 수 있는 환경
- 모바일 노드에서 데이터 Fetching vs. chasing 또는 동시에 온라인에 있지 않은 두 노드 사이에 연결을 설정하거나 로컬 통신을 위해 클라우드를 거치는 것 등
- Research issues
- Auto-configuration, auto-discovery, device-to-device communication
- Security models 및 mechanism
- 이동성(mobility) 기반의 Routing, forwarding strategy 및 동시에 여러 인터페이스 사용
2.10 Forwarding Strategy
- 데이터 플레인(data-plane)을 스마트하게 만드는 강력한 메커니즘
-
서로 다른 유형의 데이터, 서로 다른 네트워크에 각각의 전략 적용
- example
- large scientific data movement, VR/AR data, IoT data을 위한 각각의 전략
- vehicular networks, smart homes, sensor networks, delay-tolerant networks, data-center networks 등을 위한 각각의 전략
- 유연한 전략 구성 지원
2.11 Sync
- 공유 데이터 세트의 다중 사용자(multi-party) 동기화(synchronization)
- 각 당사자는 다른 하위 집합(subset)으로 시작할 수 있음
- 시간이 지남에 따라 데이터 세트가 변경 될 수 있음
- NDN 전송을 위한 추상화(abstraction)
- TCP와 같은 안정적인 전송은 특별한 경우
- 발신자(sender)가 전체 집합을 가지고 수신자(receiver)는 가지고 있지 않음
- Basic approach
- 서브셋의 효율적인 표현 및 교환, 데이터를 공유하고 중복을 제거(redundancy)하기 위해 multicast/broadcast를 활용
- 제안된 다수의 해결책
- 데이터 naming, 상태 표시(state representation), 변경 알림(change notification) 및 업데이트 검색(update retrieval)이 서로 다름
2.12 Congestion Control
- NDN을 위한 다른 스토리
- 단일 기본 RTT와 point-to-point 세션이 더이상 필요하지 않음
- multipath, multi-source data 전송
- congestion control을 위해 interest rate 규제
- 어디에서나 hop-by-hop solutions 필요
- 경로의 모든 노드 참여
- 여러 경로(multiple path)와 여러 소스(multiple source)를 사용할 수 있어야 함
- 전반적인 네트워크 동작에 미치는 영향
2.13 Routing, Forwarding, and Caching
- NDN에서 Routing, Forwarding, Caching은 모두 관련
- 예를 들어, 포워딩 결정은 캐시 가용성에 영향을 미치며, 이는 향후 포워딩 결정에 영향이 있음
- 다른 네트워크 환경에서 이들을 공동으로 최적화
- 데이터 센터, ISP 네트워크, 모바일 에지 네트워크 등
- 새로운 라우팅 프로토콜 탐색(Explore new routing protocols)
- 스마트 데이터 플레인을 사용하여 컨트롤 플레인의 요구 사항 완화
- Routing Scalability
- Table size
- Routing churns
2.14 Scalable forwarding engine
- 테이블 조회 및 업데이트 (FIB, PIT, CS)
- Name 길이는 가변적(variable-length)
- Table 크기가 클 수 있으며 내용(content)이 동적 일 수 있음
- matching rule은 각 table 마다 다름
- 많은 연구에서 다양한 데이터 구조를 제안
- Hash tables, tries, bloom filter
- 주로 FIB에 중점
- CS와 PIT에 대한 더 나은 디자인이 필요
3. What we have been doing
3.1 Application-driven architecture development
- 현재 포커스하고 있는 영역:
- Mobile edge computing
- Internet of Things
- Navigable media
- 다른 applications
- Open mHealth (mobile health)
- 빌딩 자동화 및 관리
- Scientific “big data” (e.g., climate change)
- 실시간(real time) 회의
- Neighborhood solar
- File sharing, chat, etc.
3.2 Protocol and Mechanism Design
- 디자인 원칙을 명시하고 패킷 형식 및 프로토콜 사양 개발
- Routing protocols
- Forwarding Strategies
- 테이블 구조 및 알고리즘
- Name-based authentication, trust, access control
- Sync protocols
- Congestion control
- …
3.3 Running Code and Evaluation Platforms
- Network forwarder, libraries, tools
- 기존 플랫폼 및 IoT 장치에서
- Simulator, emulator, global testbed
- All code is open sourced
3.4 Research Community
- NDNCommunication
- 2017 at Memphis, 73 people from 36 institutions
- 2015 at UCLA, 116 people from 49 institutions
- 2014 at UCLA, 87 people from 31 institutions
- ACM ICN conference and ICN-related workshops
- IRTF ICN RG
- Both academia and industry
