IPFS - BitTorrent
BitTorrent Protocol 의 동작
BitTorrent (BT for short) 는 다운로드하는 동안 각 다운로더가 다른 다운로더에 다운로드 한 데이터를 제공하는 파일 배포 프로토콜 입니다. 일반적인 FTP 및 HTTP 프로토콜에서 모든 다운로더는 중앙 서버에서 데이터를 요청하며 다양한 다운로더 간에는 상호 작용이 없습니다. 많은 수의 다운로더가 동일한 데이터를 동시에 다운로드하면 중앙 서버의 처리 성능 및 대역폭 제한으로 인해 다운로드 데이터가 매우 느려지고 일부 사용자는 서버에 연결할 수 없습니다. BT 다운로드는 다운로드 파일 공유 다운로드 기능이 더 빠르게 다운로드 합니다.
1. BitTorrent 구성
BitTorrent 프로토콜을 기반으로하는 파일 배포 시스템은 다음 구성 요소로 이루어져 있습니다. (1) 웹 서버, (2) 시드 파일, (3) 트래커 서버, (4) 원본 문서 제공자, (5) 웹 브라우저, (6) 다운로더 입니다.
시드 파일은 웹 서버에 저장되며 다운로더는 먼저 웹 서버에서 시드 파일을 다운로드해야 합니다. 시드 파일은 메타 파일이라고도하며 파일 이름, 파일 크기 및 트래커 서버의 주소와 같은 공유 파일에 대한 정보를 저장합니다. 시드 파일은 매우 작으며 일반적으로 1GB 공유 파일의 시드 파일은 100KB 미만이며 시드 파일에는 .torrent 접미사가 붙습니다. 시드 파일의 트래커 서버 주소는 파일을 기록하는 모든 노드의 IP 및 포트입니다. 시드 파일은 원본 파일 제공자가 만듭니다.
제작 프로세스: 먼저 BT 클라이언트를 다운로드 한 다음 새 BT 시드 작업을 만들고 공유 할 파일을 선택한 다음 제작 과정을 클릭하여 시드 파일을 완성합니다. 사용자는 시드 파일을 네트워크에 업로드하고 다른 사용자는 시드 파일을 통해 해당 파일 내용을 가져올 수 있습니다.
사용자가 시드 파일을 다운로드하는 프로세스: 사용자는 먼저 BT 시드 파일을 다운로드 한 다음 다른 다운로드 클라이언트에 새 BT 작업을 만들고 시드 파일을 선택하고 클릭하여 다운로드를 시작합니다. 원칙적으로 클라이언트는 먼저 시드 파일을 구문 분석하고 트래커 서버의 주소를 포함하여 다운로드 할 공유 파일에 대한 정보를 얻습니다. 클라이언트는 트래커에 연결하여 현재 파일을 다운로드하는 모든 다운로더의 IP 및 포트를 가져옵니다. 그런 다음 클라이언트는 IP 및 포트를 기반으로 다른 다운로더에 연결하고 다운로드 합니다.
공유 파일은 일반적으로 크기가 256KB 인 조각이라고하는 동일한 크기의 블록으로 논리적으로 나뉩니다. 공유 파일의 경우 파일의 첫 번째 바이트부터 256K (즉 262144) 바이트가 첫 번째 파일이며 두 번째 파일은 256K + 1 바이트에서 512K 번째 바이트까지 입니다. 해시 파일에는 각 조각의 해시 값이 들어 있습니다. BT 프로토콜은 Sha1 알고리즘을 사용하여 각 조각에 대해 각 조각의 지문으로 20 바이트 해시 값을 생성하도록 지정합니다. 클라이언트가 조각을 다운로드 할 때마다 Peice 는 Sha1 알고리즘을 사용하여 해시 값을 계산하고 시드 파일에 저장된 조각의 해시 값과 비교합니다. 일치하면 완료되고 올바른 조각이 다운로드 됩니다. 조각이 다운로드되면 다른 조각에 다운로드 할 수 있습니다. 실제 업로드 및 다운로드에서 각 조각은 동일한 크기의 조각으로 분할되며 각 조각은 16KB (16384 바이트)로 고정됩니다. 피어 간의 각 전송은 슬라이스 단위입니다.
위 설명으로부터 알 수 있는 바와 같이 BT 클라이언트는 주로 다운로드 할 파일의 일부 정보를 얻기 위해 시드 파일을 파싱하고 피어의 IP 주소 및 포트를 얻기 위해 트래커를 연결하고 피어를 연결하여 데이터를 수행하는 기능을 포함하고 있습니다. 게시할 제공된 공유 파일의 시드 파일을 업로드 및 다운로드하고 생성합니다. 시드 파일과 트래커의 반환 정보는 모두 B 인코딩이라는 간단하고 효율적 방법으로 인코딩됩니다. 클라이언트는 HTTP 프로토콜을 기반으로 추적기와 정보를 교환하며 트래커 자체는 웹 서버로 존재합니다. 클라이언트는 연결 지향적이고 안정적인 전송 프로토콜인 TCP 를 사용하여 다른 피어와 통신합니다.
2. B 인코딩
시드 파일과 트래커에서 반환 한 정보는 모두 B 인코딩 입니다. 시드 파일과 트래커의 반환 정보를 구문 분석하고 처리하려면 먼저 B 인코딩 규칙을 숙지해야합니다. B 인코딩에는 4 가지 유형이 있습니다.
- 정수: 인코딩 형식은 i<십진수>e 입니다. 예를 들어, 10 진수 정수는 8이며 B 코딩 후에는 i8e 이고 -6이 인코딩 된 후에는 i-6e 입니다.
- 문자열 유형: 인코딩 형식은 <길이의 문자열="">:<문자열> 입니다. 예를 들어 hello 문자열은 B:5:hello 로 인코딩 됩니다.
- 목록 유형: 인코딩 형식은 l<모든 B="" 형="" 인코딩="" 조합="">e입니다. l은 목록의 첫 글자입니다. 두 개의 문자열 목록과 같은 문자열은 B 인코딩이 l5:chain5:blocke 이고 B 가 인코딩 된 후 문자열의 정수 목록 3과 문자열 hi 가 li3e2:hie 인 경우 chain, block 입니다.
3. 시드 파일의 구조
시드 파일의 키워드는 다음과 같습니다.
| 이름 | 유형 | 의미 |
|---|---|---|
| announce | string | TrackerServer 주소 |
| announce-list | List of list | TrackerServer 그룹 목록 |
| info | Dict (k/v 컬렉션) | 이 키워드에 해당하는 값은 사전이며이 키워드에 해당하는 값은 사전이며 “singel file”과 “multiple file”의 두 가지 모드, 파일 모드 및 다중 파일 모드가 있습니다. 단일 파일 모드는 공유 할 파일이 하나만 있다는 것을 의미하며 다중 파일 모드는 공유를 위해 둘 이상의 파일을 제공하지만 두 개 이상을 제공하는 것을 의미합니다. BT 소프트웨어를 사용하여 영화를 다운로드하면 영화의 상단과 하단이 별도의 파일에 배치 될 수 있습니다. |
| publisher | string | 시드 게시자 이름 |
| publisher-url | string | 시드 게시자 URL |
| nodes | list | DHT (분산 해시 테이블) 노드 목록 |
| encoding | string | 시드 파일의 문자 인코딩 (예: UTF-8) |
seed 파일에서 가장 중요한 키워드는 info 입니다. 단일 파일 모드, 다중 파일 모드 상관없이 사전에는 다음 표와 같은 키워드가 들어 있습니다.
| 키워드 | 의미 |
|---|---|
| piece length | 각 조각의 길이는 B 코드의 정수이며 일반적으로 256K 또는 512K 또는 128K 인 i262144e 입니다. |
| pieces | 해당 값은 각 조각의 해시 값을 저장하는 문자열이며 이 문자열의 길이는 각 조각의 해시 값이 20 바이트이기 때문에 20의 배수여야 합니다. |
| private | 값이 1이면 클라이언트가 트래커, 즉 피어의 IP 주소와 포트 번호를 연결하여 다른 다운로더를 가져와야 함을 나타내며, 0이면 클라이언트가 다른 방법을 통해 피어의 IP 주소와 포트를 얻을 수 있습니다. DHT는 피어를 분산 방식으로 얻는 방법인 분산 해시 테이블 (Distribute Hash Tabel)입니다. 많은 BT 클라이언트는 이제 피어를 얻기 위해 트래커를 연결하거나 DHT 를 모두 지원합니다. 시드 파일에 개인 키워드가 없으면 트래커를 연결하여 피어를 가져와야 함을 의미합니다. |
단일 파일 모드 시드 파일의 경우 info 값은 다음 표에 표시된 키워드도 포함합니다.
| 키워드 | 의미 |
|---|---|
| name | 공유 파일의 파일 이름, 즉 다운로드 할 파일의 파일 이름 |
| length | 공유 파일의 길이 (바이트) |
| md5sum | 선택적으로 공유 파일의 md5 값입니다.이 값은 BT 프로토콜에서 전혀 사용되지 않습니다. |
다중 파일 모드 시드 파일의 경우 정보 값은 다음 표에 표시된 키워드도 포함합니다.
| 키워드 | 의미 |
|---|---|
| name | 모든 공유 파일이 저장된 폴더 이름 |
| files | 이 값은 여러 개의 사전이있는 목록으로 각 공유 파일은 사전입니다. 사전에는 3 개의 키워드가 포함되어 있습니다. |
Files 의 각 공유 파일의 키워드는 다음 표에 표시된 사전입니다.
| 키워드 | 의미 |
|---|---|
| length | 공유 파일의 길이 (바이트) |
| md5sum | 선택적 |
| path | 공유 파일의 경로와 파일 이름을 저장 |
4. 트래커와 상호 작용
시드 파일을 구문 분석하고 트래커 서버의 URL 을 얻으면 트래커와 상호 작용할 수 있습니다. 트래커와 상호 작용에는 두 가지 주요 목적이 있습니다. 하나는 트래커가 관련 통계를 수행 할 수 있도록 트래커에게 다운로드 진행 상황을 알리는 것이며 다른 하나는 현재 동일한 공유 파일을 다운로드하는 피어의 IP 주소와 포트 번호를 얻는 것입니다. 클라이언트는 HTTP 프로토콜을 사용하여 트래커와 통신합니다. 트래커는 HTTP GET 메소드를 통해 요청을 받고 요청 구성에는 트래커의 URL 이 옵니다. 예) http://tk.greedland.net/announce?param1=value1¶m2=value2. 트래커에 클라이언트가 보낸 GET 요청에서 매개 변수는 일반적으로 아래 표와 같습니다.
| 매개변수 | 의미 |
|---|---|
| info_hash | seed 파일의 info 키워드에 해당하는 값은 Sha1 알고리즘에 의해 계산되며 해시 값은 info_hash 매개 변수에 해당하는 값이며 해시 값의 길이는 20 바이트로 고정 |
| peer_id | 자체를 식별하는 데 사용되는 파일을 다운로드하기 전에 임의의 방식으로 각 클라이언트가 생성 한 20 바이트 식별자 및 길이도 고정 |
| port | 다른 피어의 연결 요청을 수신하는 데 사용되는 수신 포트 번호 |
| uploaded | 현재 총 업로드 (바이트) |
| downloaded | 현재 총 다운로드 (바이트) |
| left | 다운로드 할 바이트 수 (바이트) |
| compact | 매개 변수의 값은 일반적으로 1 |
| event | 시작, 완료, 중지 중 하나입니다. 클라이언트가 Tracker와 처음으로 통신하면 값이 시작됩니다. 다운로드가 완료되면 값이 완료되고 클라이언트가 닫으려고하면 값이 중지됩니다. |
| ip | 선택적으로 클라이언트의 IP 주소가 트래커에 통지됩니다. 트래커는 클라이언트가 트래커에 보내는 IP 데이터 패킷을 분석하여 클라이언트의 IP 주소를 얻을 수 있으므로 선택적입니다. 일반적으로 클라이언트의 IP 는 지정되지 않습니다. |
| numwant | 선택적으로 트래커에 의해 반환 될 피어 IP 주소 및 포트 번호의 수. 이 매개 변수가 기본값이면 50 개의 피어의 IP 주소와 포트 번호가 기본적으로 반환됩니다. |
| key | 선택적으로 이 값은 클라이언트 식별에 사용되는 임의의 숫자입니다. 클라이언트가 peer_id 에 의해 식별 되었기 때문에이 매개 변수는 일반적으로 사용되지 않습니다. |
| trackerid | 선택 사항, 일반적으로 사용되지 않음 |
트래커 서버의 반환 정보는 B-인코딩 된 사전입니다. 아래 표와 같이 키워드가 포함되어 있습니다.
| 키워드 | 의미 |
|---|---|
| failure reason | 키워드에 해당하는 값은 GET 요청 실패의 이유를 나타내는 읽을 수있는 문자열이며, 반환 메시지에이 키워드가 포함되어 있으면 다른 키워드가 포함되지 않습니다. |
| warnging message | 이 키워드에 해당하는 값은 읽을 수있는 경고 문자열입니다. |
| interval | 다음 번에 트래커에 연결하기 전에 클라이언트가 대기하는 시간 (초)을 나타냅니다. |
| min interval | 클라이언트가 다음에 트래커에 연결하기 전에 대기하는 최소 시간 (초)을 나타냅니다. |
| tracker id | 트래커 ID 표시 |
| complete | 현재 얼마나 많은 피어가 전체 공유 파일을 다운로드하고 있는지를 나타내는 정수 |
| incomplete | 공유 파일을 현재 다운로드하지 않은 피어 수를 나타내는 정수 |
| peers | 각 피어의 IP 와 포트 번호를 반환하며, 값은 문자열입니다. 첫 번째는 첫 번째 피어의 IP 주소, 그 다음 포트 번호, 두 번째 피어의 IP 주소, 포트 번호 등입니다. |
다음은 Tracker 서버에 전송 된 HTTP GET 요청의 예입니다: http://tk.greedland.net/announce?info_hash=01234567890123456789&peer_id=01234567890123456789&port=3210&compact=1&uploaded=0&downloaded=0&left=8000000&event=started
다음은 추적기 서버 응답의 예입니다: d8:completei100e10:incompletei200e8:intervali1800e5:peers300:......e
여기서 “…” 은 50 개의 피어의 IP 주소 및 포트 번호가 포함 된 길이 300 의 문자열 입니다. IP 주소는 4 바이트를 차지하며 포트 번호는 2 바이트를 차지합니다. 즉, 한 피어가 6 바이트를 차지합니다.
5. 피어 간의 통신 프로토콜
피어 간의 통신 프로토콜은 피어 연결 프로토콜 (peer wire protocal) 이라고도하며 TCP 프로토콜을 기반으로 한 응용 프로그램 계층 프로토콜 입니다. 일부 피어가 다운로드하지 않고 업로드하지 못하도록하기 위해 BitTorrent 프로토콜은 클라이언트가 가장 빠른 다운로드 속도를 제공하는 4 명의 피어에게만 데이터를 업로드한다고 제안합니다. 간단히 말해, 누가 다운로드를 제공하고, 다운로드 할 데이터를 제공하며, 다운로드 할 데이터를 제공하지 않는 사람은 내 데이터를 업로드하지 않습니다. 클라이언트는 각 피어로부터 10 초와 같은 일정한 간격으로 데이터를 다운로드하는 속도를 재 계산하고 가장 빠른 다운로드 속도로 4 명의 피어의 차단을 해제하여 4 명의 피어가 클라이언트에서 데이터를 다운로드하고 다른 피어를 차단할 수 있게합니다. 예외적으로, 다운로드 속도가 더 빠른 피어를 찾으려면 언제든지 클라이언트가 최적화 된 비 차단 피어를 유지한다는 것, 즉 피어가 다운로드를 위해 클라이언트에 데이터를 제공하는지 여부를 클라이언트가 알 수 있다는 점도 예외입니다. 클라이언트가 여기에서 데이터를 다운로드합니다. 클라이언트가 피어에 데이터를 업로드하기 때문에 피어는 클라이언트가 피어에서 데이터를 다운로드 할 수있게하고 네 개의 논 블로킹 피어 중 하나보다 빠르게 다운로드합니다. 클라이언트는 30 초와 같은 규칙적인 간격으로 최적화 된 비 차단 피어를 다시 선택합니다. 클라이언트가 피어와 TCP 연결을 설정하면 클라이언트가 유지 관리해야하는 몇 가지 상태 변수가 다음 표에 표시됩니다.
| 상태변수 | 의미 |
|---|---|
| am_chocking | 값이 1이면 클라이언트가 원격 피어를 차단 함을 나타냅니다. 이 시점에서 피어가 클라이언트에 데이터 요청을 보내면 클라이언트는이를 무시합니다. 다시 말해 피어가 차단되면 피어는 클라이언트에서 데이터를 다운로드 할 수 없으며 값이 0이면 피어가 차단되지 않았 음을 나타내며 피어가 클라이언트에서 데이터를 다운로드 할 수 있음을 나타냅니다. |
| am_interested | 클라이언트가 원격 피어에 관심이 있음을 나타내는 값 1입니다. 피어가 작품을 소유하고 있고 클라이언트가 그렇지 않은 경우 클라이언트는 피어에 관심이 있다는 것 입니다. |
| peer_chocking | 값이 1 이면 피어가 클라이언트를 차단 함을 나타냅니다. 이 시점에서 클라이언트는 피어에서 데이터를 다운로드 할 수 없습니다. 값이 0 이면 클라이언트가 피어에 데이터 요청을 보내고 클라이언트가 응답합니다. |
| peer_interested | 값이 1 이면 피어가 클라이언트에 관심이 있음을 나타냅니다. 즉, 클라이언트는 조각을 소유하고 있으며 피어는 조각을 소유하지 않습니다. 값이 0이면 피어는 클라이언트에 관심이 없습니다. |
클라이언트가 피어와 TCP 연결을 설정하면 클라이언트는 이 변수의 값을 다음으로 설정합니다. Am_chocking = 1. Am_interested = 0. Peer_chocking = 1. Peer_interested = 0. 클라이언트가 피어에 관심이 있고 피어가 클라이언트를 차단하지 않으면 클라이언트는 피어에서 데이터를 다운로드 할 수 있습니다. 피어가 클라이언트에 관심이 있고 클라이언트가 피어를 차단하지 않으면 클라이언트는 데이터를 피어에 업로드합니다. 달리 명시되지 않는 한, 모든 정수 유형은 핸드 셰이크 이후의 모든 정보의 길이 프리픽스를 포함하여 4 바이트 값 (상위 우선 순위 및 최하위 순위) 으로 이 프로토콜에 인코딩됩니다.
6. BT 다운로드 구현을위한 핵심 알고리즘 및 전략
6.1 파이프 라인 운영
네트워크 프로토콜은 일반적으로 높은 전송 효율을 요구하고, BT 프로토콜은 전송 효율을 제공하기 위해 파이프 라인 동작을 사용한다. 클라이언트가 피어에게 데이터 요청을 보내면 (즉, 요청 메시지를 보내는 경우) 한 번에 여러 슬라이스가 요청됩니다 (즉, 한 패킷이 여러 슬라이스를 요청하기 위해 여러 요청 메시지를 보냅니다). 클라이언트가 한 번에 하나의 슬라이스 요청 만 보내는 경우, 피어는 클라이언트가 데이터 조각을 보내기를 기다리고 클라이언트가 새 데이터 요청을 보내주기를 기다립니다. 한 번에 둘 이상의 슬라이스 요청이 전송되면 피어는 슬라이스를 전송 한 후 다음 슬라이스를 전송하므로 데이터 전송의 효율성을 높이기 위해 대기하지 않습니다. 1.1 버전의 HTTP 프로토콜은 파이프 라인 작업 개념을 널리 사용하여 브라우저와 웹 서버 간의 전송 효율성을 크게 향상시킵니다.
6.2 단편 선택 알고리즘
세그먼트 선택에는 4 가지 전략이 있으며 다운로드 속도를 높이려면 좋은 전략이 중요합니다.
- 한 조각의 조각에 대한 요청이 피어에게 전송되면 조각의 다른 조각도 피어에서 다운로드되므로 가능한 한 빨리 조각으로 다운로드 할 수 있습니다. 피어는 조각에 조각을 소유하기 때문에 조각의 다른 조각을 가져야하며, 피어가 클라이언트에게 조각을 보내려고한다면 조각에있는 다른 조각을 클라이언트에게 보내야합니다.
- 우선 순위. 즉, 피어가 모든 피어 중에서 가장 낮은 소유율을 갖는다면, 피스가 우선적으로 다운로드된다. 이렇게하면이 피스가있는 피어가 갑자기 떠나서 피스가 손실되는 것을 방지 할 수 있으므로 현재 다운로드에 참여한 피어는 완전한 파일을 다운로드 할 수 없으므로 소유권이 낮은 피스를 다운로드하면 다른 피어를 다운로드하면 많은 피어는 클라이언트로 부터 데이터를 요청할 것이고, 클라이언트로 부터 데이터를 다운로드하기 위해, 피어는 다운로드 할 클라이언트에 데이터를 제공 할 것이고, 이것은 또한 클라이언트의 다운로드 속도를 향상 시키는데 도움이 될 것이다. 이 공유 시스템의 경우 소유율이 낮은 부분의 다운로드 우선 순위 지정을 통해 전체 시스템이 각 부분의 소유권을 향상시킬 수 있으며 전체 시스템이 최적의 경향이 있습니다. 모든 피어가 우선적으로 더 높은 소유율로 조각을 다운로드하면 조각 소유율이 낮아져 많은 동료가 전체 파일을받지 못할 수 있습니다.
- 무작위로 다운로드 할 첫 번째 조각 선택. 최소 우선 순위 정책은 다운로드를 시작할 때 사용할 수 없습니다. 조각의 소유권이 매우 낮으면 이 조각으로 다운로드하는 것이 상대적으로 어렵습니다. 당신이 다음 작품을 선택하는 경우 더 쉽게 작품에 다운로드 클라이언트가 완전한 조각에 다운로드되면, 그것은 다른 피어 다운로드에 사용할 수 있으며, 다른 피어 클라이언트 업로드 데이터 때문에, 출시 다른 피어 클라이언트에 빠지게됩니다 블로킹은 초기 단계에서 더 높은 다운로드 속도를 달성하는 데 도움이됩니다. 일부를 다운로드 할 때 클라이언트는 데이터를 다운로드하기 위해 우선 순위가 가장 낮은 전략을 사용해야하며, 이로 인해 단기간에 클라이언트의 다운로드 속도가 감소하지만 다운로드 속도가 크게 향상됩니다.
- 최종 스테이지 모드. 때로는 전송 속도가 느린 피어에서 곡을 다운로드하는 데 시간이 오래 걸릴 수 있습니다. 다운로드 프로세스 중에 큰 문제는 아니지만 다운로드가 거의 완료되면 클라이언트가 지연됩니다. 다운로드가 완료되었습니다. 이 문제를 해결하기 위해 최종 단계에서 클라이언트는 모든 피어에게 피어에게 일부 슬라이스 요청을 보냅니다. 피어에서 보낸 슬라이스가 수신되면 다른 피어로 취소 메시지가 전송되고 현재 피어 만 다운로드됩니다.
6.3 차단 알고리즘
BT 는 리소스를 중앙 집중식으로 할당하지 않으며, 각 피어는 가능한 한 다운로드 속도를 향상시킬 책임이 있습니다. 피어는 연결할 수있는 피어에서 파일을 다운로드하고 상대방이 제공 한 다운로드 속도에 따라 동일한 업로드 보상을 제공합니다. 협력자의 경우 업로드 서비스가 제공되고 협업이 아닌 경우 상대방은 차단됩니다. 차단은 일시적으로 업로드를 거부하는 정책입니다. 업로드가 중지되지만 다운로드는 계속됩니다. 차단을 해제하면 연결을 다시 설정할 필요가 없습니다. 블록 프로세스가 조각 메시지를 전송하는 것을 거부하기 때문에 메시지가있는 것과 같은 다른 메시지는 여전히 수신 된 메시지를 전송할 수 있습니다. 블로킹 알고리즘은 BT 프로토콜의 일부가 아니지만 성능을 향상시킬 필요가 있습니다.
각 클라이언트는 고정 된 수의 피어 (대개 4 개)로 명확하게 유지되므로 피어와 함께 어떤 식으로 명확하게 결정할 수 있습니까? 통상적 인 방법은 현재의 다운로드 속도를 기반으로 어느 피어가 명확하게 유지되어야 하는지를 결정하는 것입니다. 그러나 현재 다운로드 속도를 계산하는 것은 큰 문제입니다. 현재 구현은 대개 지난 10 초 동안 각 피어에서 데이터를 다운로드하는 속도를 계산합니다. 클리어 (즉, 차단 해제) 된 피어는 빈번하게 블로킹 및 블로킹을 피하기 위해 10 초 간격으로 재 선택되므로 자원 낭비가 발생합니다. 연습을 통해 다운로드 속도를 최대화하는 데 10 초가 충분하다는 사실이 입증되었습니다.
가장 높은 다운로드 속도를 제공하는 4 명의 동료에게 업로드 서비스를 제공하면 무료 연결의 다운로드 속도가 더 빨라지는 것을 알 수있는 방법이 없습니다. 이 문제를 해결하기 위해 언제든지 각 피어는 “optimistic unchoking” 피어를 가지고 있으며 연결 속도는 다운로드 속도에 관계없이 항상 명확하게 유지됩니다. 30 초마다 피어를 최적화 된 비 차단 피어로 다시 선택합니다. 30 초는 피어의 업로드 기능을 최대화하기에 충분합니다.
피어가 다운로드를 완료하면 더 이상 다운로드 속도를 통해 업로드 할 피어를 결정할 수 없습니다 (다운로드 속도가 이미 0이기 때문에). 현재의 솔루션은보다 나은 다운로드 속도를 얻은 동료를 우선시하여 명확하게 유지하는 것입니다. 그 이유는 업로드 대역폭을 최대한 활용하기 위해서 입니다. 피어가 다운로드를 완료하면 시드가 됩니다. 시드에는 파일의 전체 복사본이 있으며 다른 피어에게 다운로드 할 수 있습니다. 전체 시스템의 성능을 위해, 각 피어는 전체 시스템에 대한 보상으로 다운로드가 완료된 후에 일정 기간 동안 시드로 존재해야합니다. 원본 시드, 즉 공유를 위해 처음에 제공된 파일이며 시드 파일이 생성되고 시드 파일이 웹 서버에 게시됩니다. 시스템에 다른 시드가 생성 될 때까지 존재해야합니다. 그렇지 않으면 현재 다운로드에 참여하는 모든 피어가 있어야합니다 어느 쪽도 파일의 완전한 복사본을 얻을 수 없습니다.
IPFS - SFS
자체 명명 시스템 SFS
1. SFS 란?
SFS 는 SAN 및 하드웨어와 소프트웨어의 조합에 설치된 파일 시스템 입니다.
다양한 운영 체제 플랫폼을 위한 통합 파일 스토리지 환경을 제공하여 여러 독립 파일 시스템을 공유 파일 시스템으로 추상화함으로써 기존 SAN 아키텍처의 파일 및 데이터 관리 문제를 해결하고 파일 수준을 달성합니다. 데이터 공유, 스토리지 할당 및 Serverless 데이터 백업, SVC 와 마찬가지로 스토리지 장치 구성, 투명 마이그레이션 데이터 및 기타 가상 스토리지 SAN 컨트롤러를 정책에 따라 동적으로 조정하는 기능이 있으며 모든 기능이 파일 주위에 있습니다. 레벨 스토리지 서비스가 배치됩니다. 뿐만 아니라 SFS 는 분산 파일 시스템의 설계 개념과 시스템 아키텍처를 한 단계 더 발전시킵니다. 일반 분산 파일 시스템의 특성 외에도 SAN 을 전체 파일 시스템의 데이터 저장 및 전송 경로로 사용합니다. 이들은 대역외 (out-of-band) 아키텍처를 사용하여 고속 이더넷을 통해 파일 시스템 원시 데이터를 전송하고 이를 전용 원시 데이터 서버로 처리 및 저장합니다. SAN File System 은 시스템 리소스를 효과적으로 활용하고 성능을 향상시키며 비용을 절감 할 수있는 정책 기반 파일 데이터 위치 선택 방법을 채택합니다.
자기 검증 파일 시스템은 David Mazieres 와 그의 스승 인 M. Frans Kaashoek 이 박사 학위 논문에서 제안했습니다. SFS (Self-Certifying File System) 는 인터넷 전체가 공유하는 파일 시스템을 설계하도록 설계되었으며 전역 SFS 시스템은 모두 동일한 네임 스페이스에 있습니다. SFS 에서 파일 공유는 매우 간단 할 수 있습니다. 파일 이름만 입력하면 됩니다. 누구나 웹과 같은 SFS 서버를 구축 할 수 있으며 모든 클라이언트는 네트워크의 모든 서버에 연결할 수 있습니다.
직관적으로 글로벌 공유 파일 시스템을 구현하는데 있어 가장 큰 장애물은 서버가 클라이언트에 인증을 제공하는 방법입니다. 파일 시스템을 사용할 때 사용자는 서버를 익명으로 입력 할 수 있으며 모든 클라이언트는 언제든지 서버를 입력 할 수 있습니다. 그렇다면 문제는 합리적으로 핵심을 관리하는 방법입니다. 우리가 생각할 수있는 한 가지 생각은 각 서버가 비대칭 암호화를 사용하여 개인 키와 공개 키를 생성한다는 것입니다. 클라이언트는 서버의 공개 키를 사용하여 서버의 보안 연결을 확인합니다. 그렇다면 새로운 문제가 있습니다. 클라이언트가 처음에 서버의 공개 키를 얻게하려면 어떻게해야 합니까? 다른 요구 시나리오의 경우 키 관리에 대한 요구 사항이 다르며 키 관리의 확장 성을 달성하는 방법은 무엇입니까?
SFS 는 공개 키 정보를 파일 이름에 포함시키고 ‘자체 검증 파일 이름’ 을 명명하는 새로운 방법을 사용합니다. 따라서 파일 시스템 내에 키 관리를 구현할 필요가 없습니다. 키 관리 기능은 파일 명명에 대한 사용자의 규칙에 추가 될 수 있습니다. 이것은 사용자의 암호화 방법에 많은 편의를 제공하며 사용자는 자신의 필요에 따라 필요한 암호화 방법을 선택할 수 있습니다.
SFS 의 핵심 아이디어는 다음과 같습니다.
SFS 파일 시스템에는 자체 인증 경로 이름이 있으며 파일 시스템 내에서 키 관리가 필요하지 않습니다. 다양한 조합을 포함하여 SFS 에서 다양한 키 관리 메커니즘을 쉽게 설정할 수 있습니다. SFS 는 키 배포에서 키 해지를 분리하고 키 복구를 방지합니다.
2. SFS 디자인
2.1 보안
SFS 시스템의 경우 보안은 두 부분으로 정의 할 수 있습니다. 1) 파일 시스템 자체의 보안, 2) 키 관리의 보안 입니다. 즉, 보안은 공격자가 허가없이 파일 시스템을 읽거나 수정할 수 없다는 것을 의미하며 사용자의 요청에 대해 파일 시스템은 올바른 파일을 사용자에게 반환해야 합니다.
파일 시스템 자체의 보안: 명시적으로 익명 액세스를 허용하지 않는 한 SFS 는 파일을 읽거나, 수정하거나, 삭제하거나, 변조 할 필요가 있는 경우 올바른 키가 필요합니다. 클라이언트는 항상 서버의 암호화 된 보안 채널에서 통신하며 채널은 양 당사자의 ID, 데이터 무결성 및 실시간을 보장해야 합니다. (공격자가 패킷을 가로 채서 시스템을 스푸핑하기 위해 다시 보내지 않도록하십시오. 이를 재연 공격이라고 합니다)
키 관리의 보안: 파일 시스템의 보안만으로는 사용자의 요구를 충족시키지 못합니다. 사용자는 키 관리를 사용하여 보다 높은 수준의 보안을 달성 할 수 있습니다. 사용자는 사전 구성된 개인 키를 사용하거나 다중 암호화를 사용하거나 타사에서 제공하는 파일 시스템을 사용하여 인증 된 파일 서버에 액세스 할 수 있습니다. 사용자는 유연하고 쉽게 다양한 키 관리 메커니즘을 구축 할 수 있습니다.
2.2 확장성
SFS 위치 지정은 전 세계적으로 공유되는 파일 시스템이기 때문에 확장성이 뛰어납니다. 사용자가 암호 인증을 사용하여 개인 파일을 읽거나 공개 서버에서 콘텐츠를 탐색하는 경우 SFS 가 잘 호환되어야 합니다. 새 서버를 배포 할 때 SFS 는 가능한 한 간단하고 편리해야 합니다.
SFS 시스템에서는 인터넷에 도메인 이름이나 주소가 있는 서버를 SFS 서버로 배포 할 수 있으며 등록 권한을 요청하지 않아도 프로세스가 매우 간단합니다. SFS 는 전체 네트워크에 대한 공유 네임 스페이스, 키 관리를 위한 기본 요소 세트 및 모듈 식 디자인이라는 세 가지 특성을 통해 확장된 성능을 구현합니다.
전역 네임 스페이스: 모든 클라이언트에 로그인 되어있는 SFS 는 동일한 네임 스페이스를 사용합니다. SFS 는 모든 클라이언트에서 동일한 파일을 공유하지만 아무도 전체 글로벌 네임 스페이스를 제어 할 수 없으며 모든 사용자가 네임 스페이스에 새 서버를 추가 할 수 있습니다. 키 관리를 위한 기본 세트: SFS 를 사용하면 사용자가 임의의 알고리즘을 사용하여 파일 이름 확인 중에 공개 키를 찾고 확인할 수 있습니다. 서로 다른 사용자가 서로 다른 기술로 동일한 서버를 인증 할 수 있으며 SFS 를 통해 파일 캐시를 안전하게 공유 할 수 있습니다. 모듈형 설계: 클라이언트와 서버는 모듈형으로 설계되었으며 대부분의 프로그램은 설계된 인터페이스를 사용하여 통신합니다. 이렇게하면 시스템의 모든 부분을 업데이트 하거나 새 기능을 추가하는 것이 쉽습니다.
3. 자체 확인 파일 경로
자체 검증 파일 시스템의 중요한 특징은 외부 정보에 의존하지 않고 암호화 제어 권한을 사용하는 것입니다. 이는 SFS 가 로컬 구성 파일을 사용하는 경우 전역 파일 시스템의 디자인과 분명히 상반되기 때문에 중앙 서버가 연결을 지원하는데 사용되는 경우 사용자는 신뢰할 수 없기 때문입니다. 그렇다면 외부 정보에 의존하지 않고 파일 데이터를 안전하게 얻는 방법은 무엇입니까? SFS 는 자가 인증 할 수 있는 경로 이름을 통해 이를 달성 할 수있는 새로운 방법을 제안합니다.
SFS 경로에는 네트워크 주소 및 공개 키와 같이 지정된 서버와의 연결을 형성하는데 필요한 모든 정보가 들어 있습니다. SFS 파일 경로는 세 부분으로 구성됩니다.
서버 위치: IP 주소 또는 DNS 호스트 이름이 될 수있는 파일 시스템 서버의 주소를 SFS 클라이언트에 알립니다. 호스트ID : 서버와의 보안 연결 채널을 구축하는 방법을 SFS 에 알립니다. 연결 보안을 위해 각 SFS 클라이언트에는 공개 키가 있으며 HostID 는 일반적으로 호스트 이름과 공개 키의 해시로 설정됩니다. 일반적으로 SFS 는 SHA-1 함수에 따라 계산됩니다. HostID = SHA-1 (“HostInfo”, Location, PublicKey, “HostInfo”, Location, PublicKey)
SHA-1 의 사용은 주로 계산의 용이함과 허용 가능한 보안 수준을 고려합니다. SHA-1 의 출력은 20 바이트로 고정되어 공개 키보다 훨씬 짧습니다. 동시에 SHA-1 은 SFS 에 대한 충분한 암호화 보호를 제공 할 수 있으며 요구 사항을 충족시키기 위해 한 쌍의 합법적인 서버 위치와 공개 키 쌍을 찾을 수 있습니다.
원격 서버에서 파일의 주소: 처음 두 메시지는 대상 서버를 찾고 보안 연결을 작성하는 것입니다. 마지막으로 파일의 위치를 제공하고 필요한 파일을 찾아야 합니다. 전체 자체 검증 파일 경로의 형태는 다음과 같습니다.
SFS 시스템은 인터넷 주소 또는 도메인 이름을 위치로 제공하고 공개 키 개인 키 쌍이 주어지면 해당 HostID 를 확인하고 SFS 서버 소프트웨어를 실행하며 모든 서버는 SFS 에 추가 할 수 있습니다. 등록 절차를 수행하십시오.
4. 사용자 확인
자체 유효성이 검사 된 경로 이름은 사용자가 서버의 ID 를 확인하는 데 도움을 주며 사용자 인증 모듈은 서버가 어떤 사용자가 합법적인지 확인하는 데 도움이 됩니다. 서버 인증과 마찬가지로 모든 서버에서 작동하는 사용자 인증 방법을 찾는 것도 똑같이 어렵습니다. 따라서 SFS 는 사용자 인증을 파일 시스템과 구분합니다. 외부 소프트웨어는 서버 요구에 따라 사용자를 인증하는 프로토콜을 설계 할 수 있습니다.
클라이언트 측에서는 에이전트가 사용자 인증을 담당합니다. 사용자가 처음 SFS 파일 시스템에 액세스하면 클라이언트는 액세스를 로드하고 에이전트에 이벤트를 알립니다. 그런 다음 에이전트는 원격 서버에 대한 사용자를 인증합니다. 서버 측면에서 이 기능 부분은 서버에서 외부 인증 채널로 이동했습니다. 에이전트와 인증 서버는 SFS 를 통해 정보를 전달합니다. 검증자가 검증 요청을 거절하면 에이전트는 인증 프로토콜을 변경하여 다시 요청할 수 있습니다. 이 방법으로 실제 실제 파일 시스템을 수정하지 않고 새로운 사용자 인증 정보를 추가 할 수 있습니다. 사용자가 파일 서버에 등록되어 있지 않으면 에이전트는 일정 횟수 시도한 후 사용자의 인증을 거부하고 사용자에게 파일 시스템에 대한 익명 액세스 권한을 부여합니다. 또한 에이전트는 여러 프로토콜을 통해 특정 서버에 쉽게 연결할 수 있으며 매우 편리하고 유연합니다.
5. 키 폐기 메커니즘
때때로 서버의 개인 키가 유출 될 수 있으며 원래의 자체 인증 파일 경로가 악의적인 공격자가 설정 한 서버에 잘못 위치 할 수 있습니다. 이를 피하기 위해 SFS 는 키 해지 명령어와 HostID 차단과 같은 두 가지 메커니즘을 제어합니다. 키 해지 명령은 파일 서버 소유자 만 보낼 수 있으며 대상은 모든 사용자입니다. 호스트 ID 차단은 다른 노드에서 보내고 파일 서버 소유자와 충돌 할 수 있습니다. 인증된 각 에이전트는 HostID 차단 명령을 따르거나 준수 할 수 있습니다. 준수하도록 선택하면 해당 HostID 에 액세스 하지 않습니다.
키 해지 명령의 형식: Revoke message = { “PathRevok e”, Location, K, NULL} K^-1 여기서 “PathRevoke” 필드는 상수이고 Location 은 키를 해지해야하는 자체 확인 경로의 이름이고 NULL 은 전달 포인터 명령어의 일관성을 유지하기 위해 전달 포인터로서 여기서 빈 경로를 가리키며 이는 원래 포인터가 유효하지 않음을 의미합니다. 여기서 K 는 실패 이전의 공개 키이고 K^-1 은 개인 키입니다. 이 정보는 해지 지시가 서버 소유자에 의해 발행되도록 합니다.
SFS 클라이언트 소프트웨어가 해지 인증서를 볼 때 해지 주소에 대한 액세스 요청은 모두 금지됩니다. 서버는 다음 두 가지 방법으로 키 해지 명령을받습니다. 1) SFS가 서버에 연결되면 해지 된 주소 또는 경로에 액세스하면 서버에서 반환 한 키 해지 명령을 받게됩니다. 2) 사용자가 처음으로 자체 인증 경로 이름을 수행하면 클라이언트는 에이전트에게 해지되었는지 확인하도록 요청한 다음 에이전트가 해당 결과를 반환합니다. 해지 명령은 자체 유효성 검사이므로 해지 명령을 배포하는 것은 그리 중요하지 않으며 다른 소스에서 보낸 해지 명령을 쉽게 요청할 수 있습니다.
더 자세한 SFS 는 다음을 참조하기 바랍니다. https://pdos.csail.mit.edu/papers/sfs:mazieres-phd.ps.gz
IPFS - Version Control
IPFS 버전 관리 시스템
IPFS 의 파일 버전 제어 시스템은 Git 을 기반으로합니다. 먼저 Git 을 분석해 봅시다.
1. 버전 제어 시스템 (Git)
git 학습의 개념:
- 작업 공간: 현재 파일을 편집하는 영역이 작업 영역입니다. 예를 들어 디렉토리가 ./gitworkshop 인 경우 이 디렉토리의 내용이 작업 영역입니다.
- 저장소: 프로젝트 제출의 전체 상태 및 내용을 기록하십시오. 이는 데이터가 손실되지 않음을 의미합니다.
- 스테이징 영역: 스테이징 영역이 저장소에 있고 git add 후 데이터가 여기에 저장됩니다. git commit 후에 데이터는 브랜치로 이동되고 스테이징 영역이 지워집니다.
- 네 가지 주요 객체, 즉 blob, tree, commit 및 refs (또는 태그)를 가지고 있다.
4.1. blob 은 파일의 내용을 보존합니다. git 이 파일을 추가하면 그림 61과 같이 데이터가 저장소의 오브젝트에 저장된다. 이 파일은 방금 추가 한 파일 다음에 생성된 BLOB 이다.
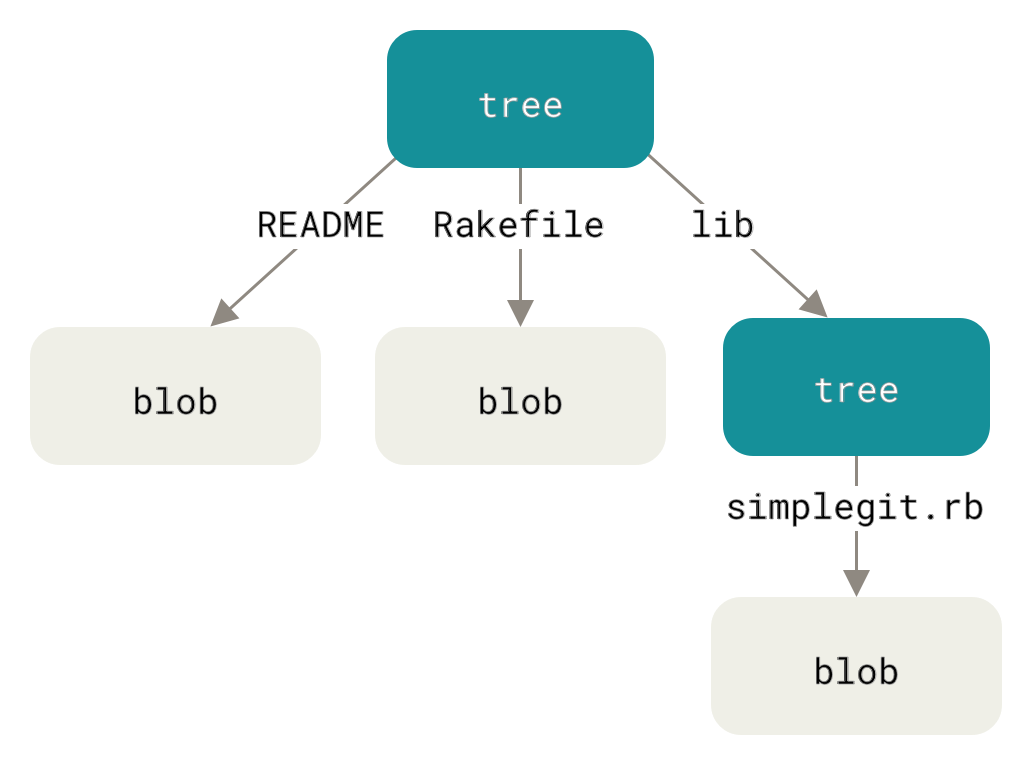
 4.2. tree git 의 데이터 저장소는 트리 형식으로 저장됩니다. 아래 그림 참조:
4.2. tree git 의 데이터 저장소는 트리 형식으로 저장됩니다. 아래 그림 참조:
 4.3. commit 이 실행되면 준비 영역의 내용이 git 저장소에 제출되고 최신 버전이 만들어지고 스냅샷이 만들어집니다. 아래 그림과 같이 최종 단계의 데이터는 마스터 지점에 제출됩니다.
4.3. commit 이 실행되면 준비 영역의 내용이 git 저장소에 제출되고 최신 버전이 만들어지고 스냅샷이 만들어집니다. 아래 그림과 같이 최종 단계의 데이터는 마스터 지점에 제출됩니다.
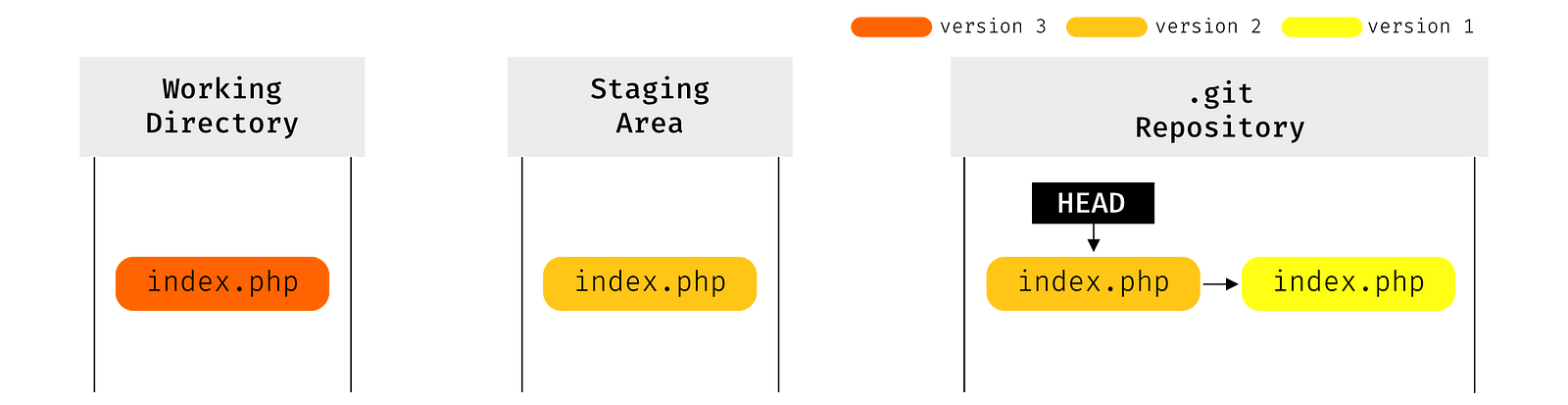 4.4. refs 는 References 의 약자입니다. 참조는 변수 이름이며 값은 코드 변경을 추적하는 데 유용한 커밋 객체를 가리 킵니다. 다음 그림에서 볼 수 있듯이 각 버전마다 고유 한 루트 해시가 있으며 ref 는 HEAD 에 해당하는 루트 해시의 내용입니다.
4.4. refs 는 References 의 약자입니다. 참조는 변수 이름이며 값은 코드 변경을 추적하는 데 유용한 커밋 객체를 가리 킵니다. 다음 그림에서 볼 수 있듯이 각 버전마다 고유 한 루트 해시가 있으며 ref 는 HEAD 에 해당하는 루트 해시의 내용입니다.
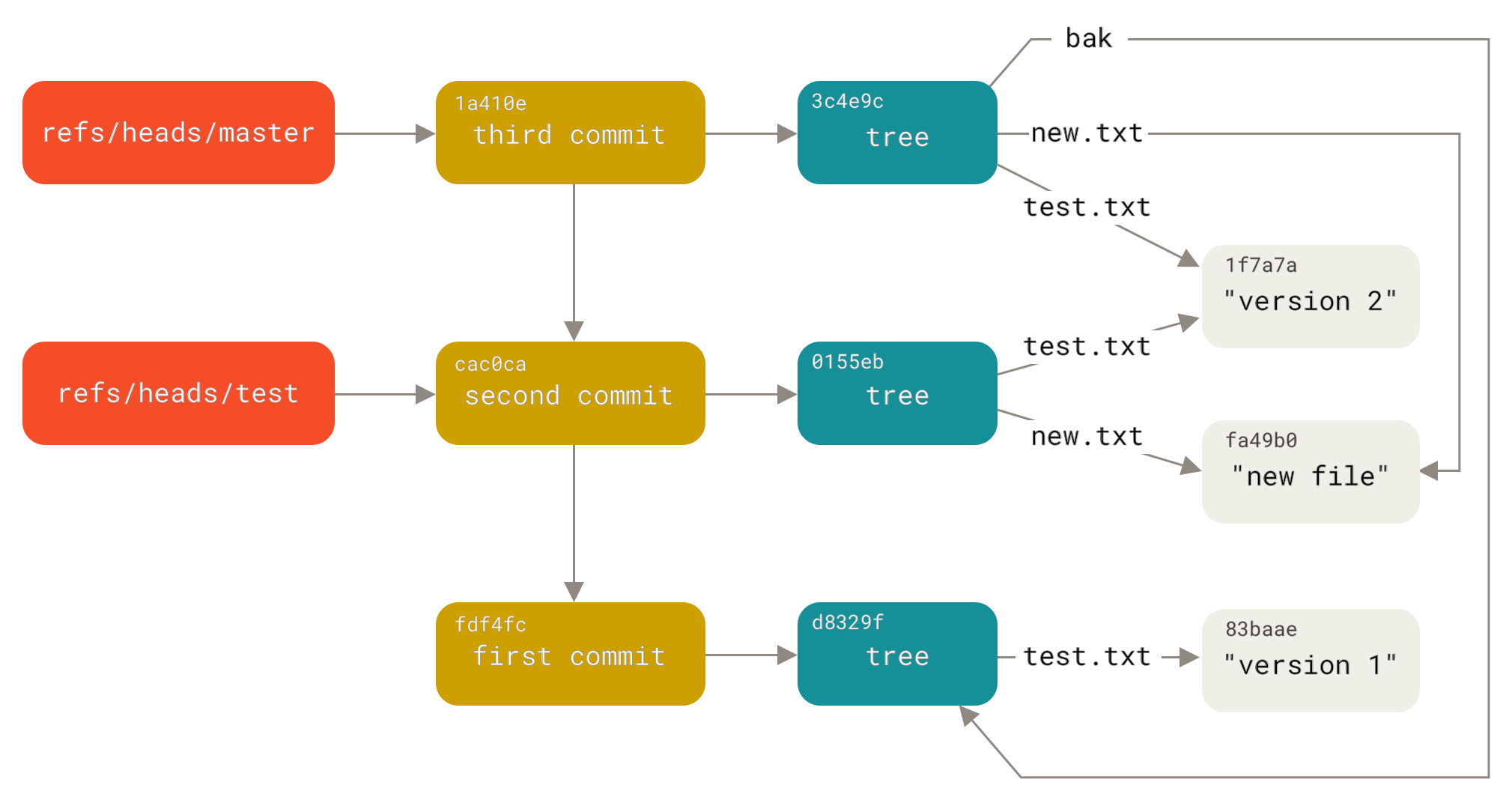
Git 은 변경된 내용으로만 데이터를 다시 저장하며 변경되지 않은 데이터는 처리되지 않습니다. 아래 그림 참조
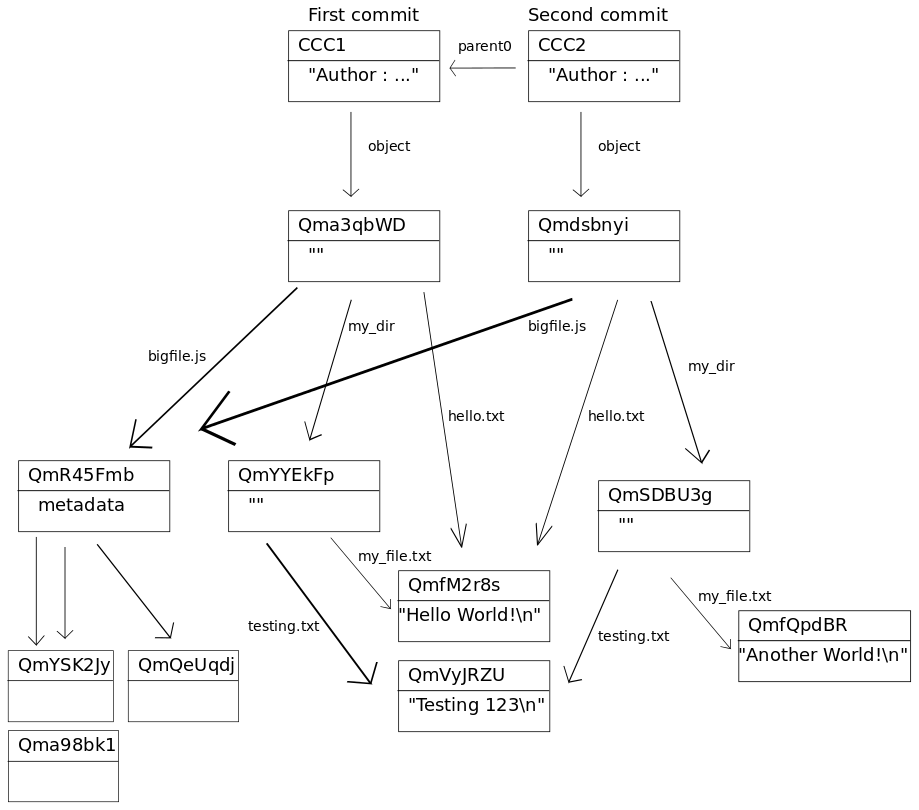
파일에는 총 3 개가 포함되며 그 중 my_dir 아래의 my_file.txt 는 hello.txt 와 동일하므로 하나의 사본만 저장됩니다. 다음으로 my_dir 폴더에서 my_file.txt 파일을 수정했습니다. 내용이 변경되어 커밋이 이루어지면 새로운 버전의 내용인 새로운 루트 해시가 생성됩니다.
2. IPFS 버전 제어 시스템
IPFS 버전 제어는 git 과 거의 같습니다. 아래 그림은 저장소의 내용입니다.
ipfs init 을 실행할 때 ./ipfs 숨김 파일을 생성합니다. 그 내용은 위 그림과 같습니다. 새 파일 내용을 추가 할 때 트리 구조의 저장소가 변경되는 버전, ldb 와 같이 데이터 저장소의 일부 내용이 변경되고 새 데이터 내용이 조각으로 블록에 저장됩니다. 블록의 데이터는 복제되지 않습니다.
각 블록 데이터는 고유 한 해시 값에 해당합니다.
여러 개의 파일과 다른 디렉토리 파일을 포함 할 수있는 디렉토리 파일. 제출 된 후 많은 해시 값을 반환하며, 마지막은 전체 디렉토리 파일의 해시 값, 즉 루트 해시입니다.이 루트 해시는 트리 해시 및 리프 해시를 포함합니다.
IPFS 는 git 처럼 데이터를 수정하거나 데이터를 검색합니다.
IPFS - DHT
IPFS 기술 배경: 분산 해시 테이블 DHT
1. Kademlia DHT
Kademlia DHT 는 KAD 라고도 하며 향상된 DHT 입니다. 간단한 분석은 다음과 같습니다: 새로 추가 된 노드는 먼저 노드의 IP 주소에 따라 노드 ID 를 임의로 생성하고 시드 노드를 통해 자신의 ID 와 유사하거나 다른 거리의 노드를 가져 와서 160K 버킷을 생성합니다. K 버킷 노드 정보에는 IP 주소, UDP 포트 및 NodeID 가 있습니다. 또한 <key, value> 유형의 파일 저장 정보 DHT 테이블이 있는데 key 는 저장된 파일의 해시값, value 는 저장된 파일의 노드 ID 입니다. 네트워크의 각 노드는 노드 ID 와 거리가 작은 파일을 우선적으로 저장합니다. (XOR 결과)
2. Coral DSHT
Coral 은 DSHT 라는 개념을 제공합니다. DSHT 는 서로 다른 값이 동일한 키를 가질 수있는 key/value 기반 저장 메커니즘을 제공합니다. CoralCDN 은 이 구조를 통해 다양한 CoralCDN 노드에 다양한 키를 매핑합니다. 특히 이 메커니즘을 통해 CoralCDN 은 클라이언트에 더 가까운 DNS 서버를 찾을 수 있으며 클라이언트에 더 가까운 웹 데이터가 있는 HTTP 프록시는 작은 지연으로 Coral 노드를 찾을 수 있습니다.
일반 오버레이 네트워크와 달리 모든 Coral 노드는 여러 독립적인 DSHT (클러스터라고 함) 에 속합니다. 각 클러스터는 최대 RTT 에 따라 분할됩니다. 이 시스템은 서로 다른 RTT 표준에 따라 여러 레이어로 나뉩니다. 모든 노드는 특정 계층의 노드 입니다. Coral 에서 DSHT 는 다음과 같이 세 가지 레이어로 나뉩니다:
- Level-2 는 두 쌍 모두 20 밀리 초 미만의 지연에 해당하며 범위에 빠르게 응답하는 클러스터 입니다. (regional coverage; 지역 범위)
- Level-1 은 두 쌍의 지연 시간 범위가 60 밀리 초 미만의 지연을 보이는 클러스터 입니다. (continental coverage; 대륙 범위)
- Level-0 는 다른 모든 노드에 해당하며 지연 시간 무한대이며 지연 적용 범위가 없는 클러스터 입니다. (planet-wide)
Coral 은 상위 수준의 빠른 노드를 요청한 다음 하위 수준의 느린 노드를 요청합니다. 이를 통해 응답 시간을 효과적으로 줄이고 거리가 가까운 노드를 찾을 수 있습니다.
Coral 은 응용 프로그램에 대해 다음 인터페이스를 제공합니다:
Put(key, val, ttl, [levels]): 값 매핑에 키를 삽입하고 시간을 지정합니다. 인터페이스 호출자는 작업 계층 수를 지정할 수도 있습니다.Get(key, [levels]): 키에 해당하는 값을 가져오고 마찬가지로 가져올 레이어를 지정할 수 있습니다.nodes(level, count, [target], [services]): 계층화 된 인접 노드 수를 반환합니다. 대상이 지정되면 대상에 가까운 노드가 반환되고 Coral 은 대상을 검색 한 다음 요구 사항을 충족하는 노드를 반환합니다. 서비스가 설정된 경우 Coral 은 지정된 서비스를 실행하는 노드 (예: HTTP 프록시 또는 DNS 서버) 만 반환합니다.levels(): 레이어 수와 해당 RTT 경계를 반환합니다.
3. S/Kademlia DHT
Kademlia 프로토콜은 완전히 열린 P2P 네트워크에 적용되며 보안 대책을 제공하지 않기 때문에 악의적인 노드 공격에 취약합니다. Kademlia 를 기반으로하는 S/Kademlia 프로토콜은 노드 ID, 브로드캐스트 및 분리 된 경로 쿼리 알고리즘을 무작위로 생성하도록 노드를 제한하는 것을 포함하여 공격에 대한 저항 전략을 확장합니다.
3.1 Kademlia 문제점
주로 두 가지 범주로 나뉘어 지는데 하나는 라우팅 테이블이 네트워크의 일부 노드를 제어하기 위한 것이고 다른 유형은 점유된 노드를 악의적으로 사용하는 리소스 입니다.
-
Sybil attack Sybil attack 은 P2P 네트워크에서 발생합니다. 노드가 언제든지 조인하고 나가기 때문에 네트워크 안정성을 유지하기 위해 일반적으로 같은 데이터를 여러 분산 노드에 백업 (데이터 중복 메커니즘) 해야 합니다. Sybil attack 은 데이터 중복 메커니즘을 공격하는 효과적인 수단입니다. 네트워크에 악성 노드가있는 경우 동일한 악성 노드가 여러 개의 ID를 가질 수 있습니다. 여러 노드에 백업해야 하는 데이터는 동일한 악의적인 노드로 스푸핑되어 악의적인 노드가 Sybil attack 을 위한 다중 ID로 가장합니다.
-
Eclipse attack Eclipse attack 은 주로 단일 노드를 공격하며, 공격의 주요 대상은 노드의 K-버킷 입니다. 공격자는 자신의 ID 를 자유롭게 선택할 수 있습니다. 공격자의 K-버킷이 가득 차거나 내부 노드가 ping 되면 악의적 노드가 K-버킷에 들어갈 수 있습니다. 악의적 노드가 K-버킷을 제어하고 정보가 악의적 노드를 통해 전송되므로 공격자는 전체 네트워크에 영향을 미칠 수 있습니다.
-
Churn attack 공격자는 많은 노드를 제어하고 즉시 네트워크에서 노드를 소모하므로 네트워크 안정성이 저하됩니다.
-
Adversarial routing 질의 명령을 수신한 후 악의적 노드는 KAD 의 요구 사항에 따라 키에 가장 가까운 네트워크 노드를 반환하지 않고 파트너 노드로 전달하여 쿼리 효과를 발생시킵니다. 이러한 적대적인 라우팅 공격을 피하기 위해 병렬 쿼리 (각 쿼리 경로는 교차하지 않음) 를 수행하고 병렬 쿼리 경로 중 하나가 도착하면 성공적인 쿼리를 나타냅니다.
3.2 S/Kademlia 보안 정책
[1] 제어 노드 ID 생성은 노드 ID 가 임의로 선택 될 수 없으며 노드 ID 가 대량으로 생성 될 수 없으며 노드 ID 를 도용 또는 위장 할 수 없도록 합니다. 이런 식으로 Sybil attack 과 Eclipse attack 이 해결됩니다.
S/Kademlia 는 각 노드가 네트워크에 액세스하기 전에 두 가지 암호화 문제를 해결해야한다고 요구합니다.
정적 문제: 한 쌍의 공개 키와 개인 키가 생성되고 공개 키가 두 번 해시 된 후 C1 키가 0으로 설정됩니다. 공개 키의 해시는 노드의 NodeID 입니다.
동적 문제: 끊임없이 난수 X 를 생성하고 X 및 노드 ID 를 XOR 하여 해시 값을 요청하면 해시 값에 C2 선행 제로가 필요합니다.
다음 그림은 이 두 가지 수학적 문제를 푸는 과정을 설명합니다.

이러한 방식으로 첫 번째 정적 문제는 노드가 더 이상 자유롭게 노드 ID 를 선택할 수 없도록하고 후자의 동적 문제는 많은 수의 ID 를 생성하는 비용을 증가 시킵니다. Sybil attack 과 Eclipse attack 은 어려울 것입니다.
[2] 분리된 경로 질의 알고리즘
Kademlia 프로토콜에서 α K-Buckets 의 노드에 액세스 한 다음 정렬하면 첫 번째 α 연속 반복 요청이 선택됩니다. 단점은 분명합니다. 악성 노드가 있으면 쿼리가 실패 할 수 있습니다.
S/Kademlia 는 쿼리 당 k 개의 노드를 선택하고이를 서로 다른 버켓에 넣을 것을 제안합니다. d 버킷이 검색되고 d 쿼리 경로가 연결되지 않고 단일 버킷에 오류가 발생할 수 있지만 d 버킷 중 하나에 필요한 정보가 있으면 작업이 완료됩니다. 적대적인 라우팅 공격은 분리 된 경로 쿼리로 해결됩니다.
IPFS - IPFS and Web?
IPFS 그리고 HTTP
HTTP 는 전체 네트워크에 서비스를 제공하기 위해 중앙 서버를 실행하는 중앙 집중식 하이퍼 텍스트 전송 프로토콜 입니다. 그러나 인터넷과 성장하는 데이터의 발전으로 인해 그 단점이 더욱 두드러졌습니다:
- [네트워크 지연]: 모든 사용자 액세스 데이터가 중앙 서버에 연결되며 사용자가 많으면 네트워크 정체가 발생할 수 있습니다. 네트워크 전송을 사용하면 네트워크 요청이 서버에 더 빨리 도달 할 수 있지만 서버가 모든 요청을 처리하여야 합니다. 네트워크 요청이 폭발적으로 증가하면 서버가 정상 속도로 데이터를 처리 할 수 없으며 사용자가 보낸 요청에 대한 응답이 지연됩니다.
- [높은 서버 비용]: 중앙 집중식 서버의 유지 관리 비용은 매우 높습니다. 서버의 운영 환경 및 유지 보수는 굉장히 까다로우며 네트워크의 안정성과 보안을 유지하기 위해 많은 기업들이 여러 원격 컴퓨터와 서버를 백업으로 사용합니다.
- [보장되지 않는 데이터 보안]: 데이터는 중앙 서비스 제공 업체에 저장됩니다. 여러 백업 서버가 있지만 서버에 문제가 있으면 전체 네트워크에 영향을 미칩니다. 네트워크에 정상적으로 액세스 할 수 없으면 치명적인 결과를 얻습니다. 동시에 데이터는 중앙 서버에 저장됩니다. 중앙 서버가 해킹되거나 서버가 악의적인 행동을 하는 경우 데이터가 크게 위협 받게됩니다.
- [네트워크 리소스 낭비]: 모든 사람들이 중앙 서버에서 데이터를 가져 오도록 요청하기 때문에 중앙 집중식 서버의 트래픽이 늘어나 많은 비용을 소비하게 됩니다. 특히 일부 중복 파일의 전송, 예를 들어 싸이의 ‘강남스타일’ 뮤직비디오가 30억 view 인데 이 파일의 크기가 100MB 라고 가정하면 네트워크 트래픽이 300P (1P = 1,000,000GB) 낭비되고 0.01USD/GB 에 따라 CDN 비용이 계산됩니다.
- [느려진 네트워크]: HTTP 프로토콜을 사용하면 매번 중앙 서버에서 전체 파일 (웹 페이지, 비디오, 그림 등) 을 다운로드하기 때문에 속도가 느리고 비효율적입니다.
위의 문제를 잘 해결하기 위해 IPFS 가 등장했습니다. IPFS 데이터 분산 스토리지는 물론 내결함성 메커니즘을 통해 각 노드가 생태적 안정성과 보안을 동시에 유지 관리 할 수 있습니다. 다음은 IPFS 가 어떻게 이러한 문제를 해결하고 그 효과가 무엇인지 분석합니다.
- 네트워크 복잡성 해소: IPFS 는 분산 스토리지 리던던시 메커니즘을 채택하고 있습니다. 네트워크에 데이터가 저장되면 256kb 크기에 따라 여러 조각으로 나뉘며 여러 복사본이 백업됩니다. 그런 다음 데이터 조각이 수요에 따라 해당 노드에 업로드 됩니다. 데이터가 검색되면 데이터 조각을 처음 저장하는 노드는 시드와 같으며 다른 노드가 데이터를 얻은 후 다운로드 완료된 데이터를 네트워크에 제공합니다. 즉, 네트워크에서 데이터를 보유한 사람은 데이터를 네트워크에 제공합니다.
- 저렴한 시스템 운영 비용: 중앙 서버의 유지 관리 비용이 없습니다.
- 강화된 데이터 보안: 데이터는 n 개 (256kb) 로 나뉘어 네트워크의 여러 노드의 백업 노드 스토리지에 저장됩니다. 이런 방식은 누군가에 의해 가로 챈 데이터는 불완전하고 단편이기 때문에 파일을 결합할 수 없음을 보장합니다. 또한 데이터를 더욱 안전하게 유지하기 위해 스토리지 노드는 여러 백업을 설정할 수 있습니다.
- 네트워크 리소스 해소: 네트워크 전송은 분산 노드를 사용하므로 에지 트래픽을 효과적으로 활용하고 트래픽 낭비를 효과적으로 해결합니다.
- 빠른 다운로드: IPFS 시스템은 분산 파일 저장 시스템이며 관련 데이터를 다운로드 할 때 중앙 서버 방식의 HTTP 와 비교하여 여러 노드에서 동시에 파일 조각이 다운로드되기 때문에 속도가 매우 빠릅니다. (BitTorrent 를 사용하는 방식과 비슷함)
IPFS 기술은 아직 개념 단계에 있으며 아직은 응용 프로그램이 거의 없기 때문에 다양한 테스트를 거쳐야하며 현재 http 를 곧 대체 할 것으로 예상됩니다. 물론 이것은 IPFS 의 디자인 비전이기도 합니다.
