IPFS - identity
IPFS 기본 - ID 계층
각 IPFS 노드에는 고유 한 ID 가 있으며 ID 는 NodeID 로 표시됩니다. IPFS 네트워크에 가입하기 전에 노드는 먼저 자신의 ID 를 생성해야 합니다. 공개 키는 S/Kademlia 정적 암호화 알고리즘에 의해 생성되며 해시 연산에 의해 NodeID 를 생성 합니다. C ++ 에서 NodeID 의 생성 과정은 다음과 같습니다:
// 난이도 (leading factor)를 0으로 설정
difficulty =< integer parameter >
// 노드 초기화
n= Node{}
// 루프 연산, 조건부 해시 (NodeID) 연산의 값에 대 한 파일럿 0 수가 ≥ 0 자리로 설정 될 때까지
do{
// 공개-개인 키 쌍 생성
n.PubKey, n.PrivKey = PKI.genKeyPair()
// 검증되지 않은 NodeID 를 얻기위해 공개 키에서 해시 작업을 수행
n.NodeId = hash(n.PubKey)
// NodeID 의 적법성 확인, 검증 후 다음 루프 종료
p = count_preceding_zero_bits(hash(n.NodeId))
} while(p<difficulty)
노드는 공개 키의 해시 연산 값이 요구 사항을 충족 할 때까지 계속해서 공개-개인 키 쌍을 생성합니다. 최종 공개 키 해시 작업의 값은 IPFS 노드와 같은 시스템의 NodeID 입니다.
터미널에서 ipfs id 를 실행하면 다음과 같이 시스템의 IPFS 노드 정보가 표시됩니다.
$ ipfs id
{
"ID": "QmXdSpUBx9Ut6q8LF8Wyt1Wi2wxmob6qnnT11uV3SmvUP3",
"PublicKey": "CAASpgIwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCh7fHOV1X0LEsqxxlY+wRRuMGZ+E7sMAWXfMj8NLenv3KpIX8pHy0lk/H6VCCjKB+t4e2Rb+Px9Uwh2YjRlLaaMkBYN27COVBdtL9sH5ZW2BZ6x00Deg+gWoO0xs5rzadtk45vV44RzxYDuGCT0GW79WgTBUi0s1O00LE6p+wOrZdk6UGYjUEzL3nD6CRMPoQbVtV8WGBWFksoyM+bnlyyCcFhw0suN5Yf8OicwGIDznsjniSOrku9QpoFU1B96SKMmfqiXZC+KyzFfKp/U1lFmfp7wlYObUYpMkcWI0/bRzdursQGga7xXyKwQJ5ZGouSANt6cClTMnOUHGLCFzzNAgMBAAE=",
"Addresses": null,
"AgentVersion": "go-ipfs/0.4.18/",
"ProtocolVersion": "ipfs/0.1.0"
}
사용자는 시스템의 IPFS 노드 정보 파일을 삭제 한 다음 초기화 (명령: ipfs init) 하여 새 ID 를 재설정 할 수 있습니다. 하지만 이렇게하면 이전 ID 의 모든 네트워크 혜택을 잃게됩니다.
IPFS 네트워크의 노드가 처음으로 연결될 때 자신의 공개 키를 서로 교환 한 다음 상대방의 공개 키, 즉 해시 (other.PubKey)를 해시하고 얻은 값이 상대방의 NodeID 와 같으면 합법적 노드로 인식하고 연결됩니다. (값이 다르면 ‘fake’ 노드로 인식)
여기에서 해시 함수에 의해 얻어진 값은 QmXdSpubx9Ut6q8LF8Wyt1Wi2wxmob6qnnT11uV3SmvUP3 과 같은 값이며 이 값은 Base58 인코딩 후의 값입니다. (모든 해시가 “Qm” 으로 시작) 이것은 실제로 multihash 이기 때문에 처음 2 바이트는 해시 함수와 해시 길이를 지정하는 데 사용됩니다. 16 진수의 처음 두 바이트는 1220이며 12는 SHA256 해시 함수임을 나타내고 20은 32 바이트 길이 계산을 선택하는 해시 함수를 나타냅니다.
IPFS - architecture
IPFS 기본 아키텍처는 무엇입니까?
IPFS 아키텍처는 아래와 같이 총 8 개의 레이어로 구성됩니다.
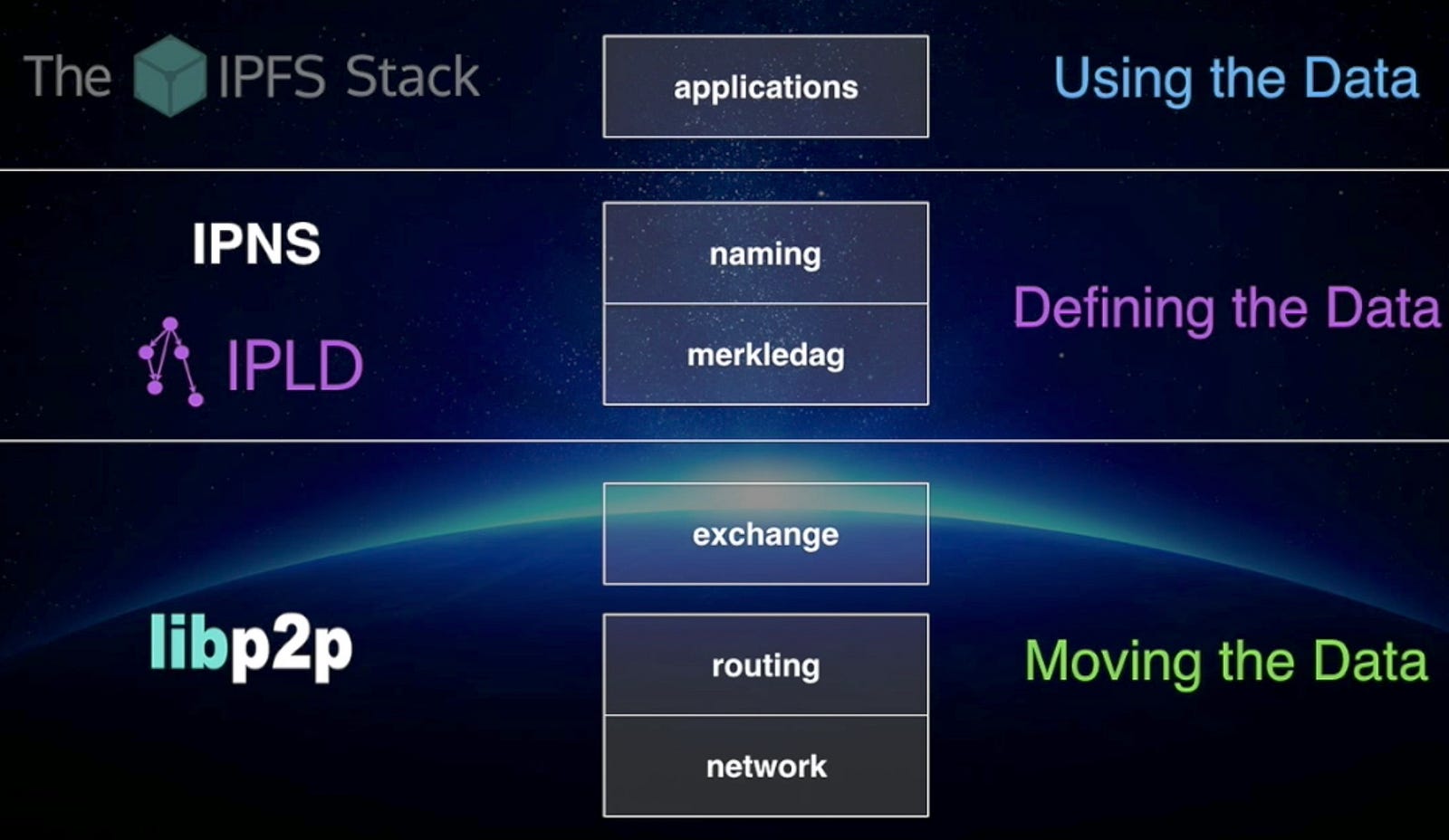
위 로부터 Network (ID, Network), Routing, Exchange, merkleDAG (Object, File), Naming, Application 으로 구성되며 각 프로토콜 스택은 자체 역할을 가지고 있으며 서로 쌍을 이룹니다. 각 계층은 다음 섹션에서 분석 됩니다.
IPFS - storage duplicate
IPFS 데이터 저장소가 중복되면?
IPFS 네트워크에서 데이터 저장소는 중복 될 수 있습니다. 이것은 IPFS 중복 제거와 다소 상반됩니다.
데이터는 IPFS 스토리지에 블록으로 저장됩니다. IPFS 에서 데이터를 분할하는 방법은 여러 가지가 있습니다. 분할 방법은 IPFS 소스 코드 core/commands/add.go 코드에 설명되어 있습니다.
The chunker option, '-s', specifies the chunking strategy that dictates
how to break files into blocks. Blocks with same content can
be deduplicated. The default is a fixed block size of
256 * 1024 bytes, 'size-262144'. Alternatively, you can use the
rabin chunker for content defined chunking by specifying
rabin-[min]-[avg]-[max] (where min/avg/max refer to the resulting
chunk sizes). Using other chunking strategies will produce
different hashes for the same file.
> ipfs add --chunker=size-2048 ipfs-logo.svg
added QmafrLBfzRLV4XSH1XcaMMeaXEUhDJjmtDfsYU95TrWG87 ipfs-logo.svg
> ipfs add --chunker=rabin-512-1024-2048 ipfs-logo.svg
added Qmf1hDN65tR55Ubh2RN1FPxr69xq3giVBz1KApsresY8Gn ipfs-logo.svg
위의 내용은 3 가지 방법으로 분할할 수 있는 것을 설명하고 있습니다.
- 기본 모드에서 블록의 크기는 256kb, 즉 256 * 1024 바이트 크기 = 262144 에 해당 합니다. 이 명령은 매개 변수를 추가할 필요가 없습니다. (예:
ipfs add ipfs-logo.svg) - 블록 크기 모드를 지정합니다. 명령은
ipfs add --chunker = size-1000입니다. 뒤쪽의 1000은 262144 미만의 숫자 일 수 있습니다. - Rabin 가변 블록 크기 분할 모드로 명령은
ipfs add --chunker = rabin-[min]-[avg]-[max] <file>입니다. min, avg 및 max 값은 각각 최소 블록 크기, 평균 블록 크기 및 최대 블록 크기이며 값은 262144 미만으로 설정됩니다. (예:ipfs add --chunker = rabin-512-1024-2048 ipfs-logo.svg)
위의 세 가지 방법은 여러 블록의 크기를 확장 할 수 있습니다. 즉, IPFS 에 동일한 파일이 저장되지만 저장 방법이 달라 반환되는 해시값이 다릅니다.
따라서 IPFS 의 블록 저장소는 중복되지 않습니다. IPFS 블록 파일의 패치 된 데이터가 복제 될 수 있습니다. 즉, 같은 파일을 다른 파일 분할 방법에 따라 IPFS 네트워크에 여러번 반복적으로 저장할 수 있습니다.
IPFS 관리는 IPFS 데이터 저장소가 중복되지 않기 때문에 시스템의 블록 데이터가 복제되지 않으며 블록 파일에 의해 함께 연결된 데이터를 반복 할 수 있습니다.
그러나 모든 사람들이 기본 분할 모드인 blocksize = 256kb 를 사용하는 것을 권고합니다. 따라서 IPFS 의 네트워크에 기존 콘텐츠를 저장할 때 IPFS 는 데이터가 네트워크 이전에 저장되었다는 것을 빠르게 알려줍니다.
같은 데이터가 네트워크에 저장되어 있다고 가정하면 전체 네트워크가 저장할 하드 디스크 저장 공간의 양은 다음과 같이 생각할 수 있다. 매우 인기있는 영화를 가지고 있다면 모든 사람들이 컴퓨터의 디스크나 다른 하드 디스크 저장 장치에 영화를 저장합니다. 1억 명의 전세계 사람들이 영화를 저장하면 이것은 큰 저장 낭비가 될 것 입니다. IPFS 네트워크에서 동영상은 하나의 노드에만 저장되며 사용자가 이를 읽어야 할 때 새로운 백업이 생성됩니다. 누구든지 데이터를 사용하면 데이터가 누구에게 복사됩니다. 이렇게하면 많은 하드 디스크 저장 공간을 절약 할 수 있습니다.
노드가 IPFS 네트워크에 연결되면 노드는 전체 네트워크에서 사용할 하드 디스크 공간 (기본값 10G) 을 제공 합니다. 정상적인 상황에서 파일을 저장할 때 하드 디스크 공간의 이 부분은 네트워크를 통과할 필요가 없으므로 가장 빠릅니다. 저장소가 완료되면 네트워크의 모든 노드가 파일에 액세스할 수 있습니다. 다른 노드가 액세스 하는 경우 해당 노드는 종종 데이터 복사본을 자신의 캐시 공간에 복사 합니다. 이러한 방식으로 전체 네트워크에 두 개의 복사본이 있습니다. 이 파일에 관심이 많은 사람들이 있을 때, 네트워크에 있는 사본의 수는 늘어날 것 입니다.
복사본은 일반적으로 캐시에 저장됩니다. 즉, 임시로 저장되며 오랜 시간이 지나면 자동으로 삭제됩니다. 인기 데이터일 수록 복사본이 많아 지지만 인기도가 떨어질 수록 복사본 수가 줄어들어 자연스럽게 공간 활용도와 액세스 효율성이 균형을 이루게 됩니다.
IPFS - data location
IPFS 데이터는 어디에 있습니까?
IPFS 데이터 저장소는 Filecoin 과 약간 다릅니다. 바로 데이터 하드 디스크에 저장되는 위치 입니다.
1. IPFS 데이터 저장소
IPFS 의 데이터 저장소는 데이터가 자체 하드 디스크, 즉 로컬 하드 디스크에 저장 되는 곳입니다. 저장 후 그것은 IPFS 네트워크에 “해시를 Qm …으로 저장합니다.” 라고 브로드캐스팅 됩니다. 해시의 고유성 때문에 데이터가 특정 한 방식으로 분할 되는 경우 동일한 데이터는 네트워크 저장소에 하나의 복사본만, 즉, 로컬 노드에만 저장됩니다. 사용자가 데이터를 검색 하면 검색 된 데이터의 해시값이 키가 되고 노드는 키에 대한 DHT 테이블 (key/value 저장소) 에서 먼저 쿼리되며 값이 없는 경우, 가장 키에 대한 XOR 거리가 가까운 K-버킷 노드에 키에 해당하는 값이 있으면 반환하고 그렇지 않으면 값이 있다고 생각되는 가장 가능성이 큰 노드를 반환하고 키에 해당하는 값을 재귀적으로 찾습니다. 그런 다음 요청 노드는 값 (즉, 노드 ID) 에 대한 연결을 설정하고 자체 DHT 테이블에 key/value 쌍을 저장 하는 동안 데이터를 요청 합니다. 요청 노드는 수신 된 데이터를 IPFS 캐시에 저장하고 데이터 검색이 완료됩니다. 요청 노드는 또한 IPFS 네트워크 뿐만 아니라 캐시 데이터 유효 기간 동안 원래 데이터의 백업으로 데이터를 제공 할 수 있습니다.
IPFS - file chunk
IPFS 파일 조각화란 무엇이며 파일 저장 후 반환 된 해시 값은 어떻게 생성됩니까?
IPFS 네트워크의 데이터는 나뉘어져 블록 (파일 조각) 에 저장됩니다. IPFS 가 ipfs add 명령을 사용하여 데이터를 저장하는 경우 기본값은 256Kb 로 데이터를 분할하는 것입니다. 물론 원하는대로 데이터를 분할 할 수도 있습니다. 예를 들어 ipfs add -r --chunker = size-10000 또는 ipfs add -r --chunker = rabin-512-1024-2048 은 지정된 크기로 데이터를 저장합니다. 다음으로는 기본 데이터 세분화로 분석합니다.
IPFS 가 특정 데이터를 추가하면 로컬은 데이터를 256kb 로 나눕니다. 256kb 보다 작은 데이터는 분할되지 않습니다. 분할 된 블록은 2진 형태로 순서대로 저장됩니다. IPFS 는 콘텐츠를 기반으로 주소를 지정하기 때문에 블록 파일에는 해시값인 고유한 ID 가 필요합니다.
블록 파일의 해시 프로세스는 다음과 같습니다:
- sha2-256 을 사용하여 블록 파일 (바이너리 파일) 을 해시하고 블록 파일의 다이제스트 값을 가져옵니다.
- 블록 파일의 기본 값을 base58 로 처리하여 블록 파일의 해시 값 CID 를 얻습니다.
이러한 블록 파일은 sha2-256 해싱, base58 처리 및 전체 파일의 인덱스와 함께 그룹화 됩니다. 데이터를 추가하면 파일의 인덱스 값인 ‘Qm’ 으로 시작하는 해시값을 반환합니다. ipfs get Qm … 이 검색되면 해당 파일이 현재 디렉토리에 다운로드 됩니다.
아래 그림은 데이터 분할 프로세스를 보여줍니다.

