IPFS - file
IPFS 기본 - File 계층
IPFS 는 MerkleDAG 의 버전 관리 파일 시스템을 모델링합니다. 이 모델은 Git 과 비슷합니다:
- block: 가변 크기 블록
- list: 블록 또는 다른 목록의 모음
- tree: 블록, 목록 또는 다른 트리 모음
- commit: 버전 히스토리에 있는 트리의 스냅 샷
1. 파일 객체: blob
파일 객체가 저장되면 일반적으로 데이터 분할이 필요하며 각 블록의 크기는 256kb 이지만 작은 파일 (<256kb) 인 경우 분할 할 필요가 없으며 직접 데이터 단위로 저장됩니다. 저장소의 유형은 blob 객체입니다.
각 blob 객체는 다음과 같이 주소 지정 데이터 단위를 포함합니다.
{
"data":"some data here",
// blobs links 없음
}
2. 파일 객체: list
IPFS 에 256kb 보다 큰 파일이 저장되면 데이터 분할이 필요합니다. 목록 객체는 여러 개의 blob 객체로 구성되며 내부에 blob 이 중복 될 수 있습니다. lists 객체는 정렬된 blob 및 list 객체를 포함합니다. 이러한 정렬된 blob 및 list 에는 자체 link 가 있습니다. link 는 데이터 정보에 해당합니다.
{
"data":["blob","list","blob"], // list 데이터 형식 객체 유형
"links":[
{
"hash":"XLYkgq61DYaq8Nhkcqy7LcnSA7dSHQ78x",
"size":189458
},
{
"hash":"XLHBNsgoepUDKL8dkd9Hesa5io9sdxi7n",
"size":19442
},
{
"hash":"XLWVQKJII8v7dggkfdhHSFlkaw9yjs7dj",
"size":5286
} // links 에서 lists 는 이름이 없음
]
}
3. 파일 객체: tree
IPFS 에서 Tree 객체는 디렉토리를 나타내는 Git 트리와 비슷하거나 해시에 이름을 매핑하는 테이블이며 해시 값은 blob, list, tree 또는 commit 을 나타내며 구조는 다음과 같습니다.
{
"data":["blob","list","blob"], // tree 데이터 객체 유형 배열
"links":[
{
"hash":"XLYkgq61DYaq8Nhkcqy7LcnSA7dSHQ78x",
"name":"less",
"size":189458
},
{
"hash":"XLHBNsgoepUDKL8dkd9Hesa5io9sdxi7n",
"name":"script",
"size":19442
},
{
"hash":"XLWVQKJII8v7dggkfdhHSFlkaw9yjs7dj",
"name":"template",
"size":5286
} // trees 는 이름이 없음
]
}
4. 파일 객체: commit
IPFS 에서 commit 객체는 버전 히스토리에 있는 객체의 스냅샷을 나타내며 Git 의 커밋과 매우 비슷하지만 모든 객체 유형을 가리킬 수 있습니다.
{
"data": {
"type": "tree",
"date": "2014-09-20 12:44:06Z",
"message": "This is a commit message."
}, "links": [
{ "hash": "XLa1qMBKiSEEDhojb9FFZ4tEvLf7FEQdhdU",
"name": "parent", "size": 25309 },
{ "hash": "XLGw74KAy9junbh28x7ccWov9inu1Vo7pnX",
"name": "object", "size": 5198 },
{ "hash": "XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm",
"name": "author", "size": 109 }
]
}
$ ipfs file-cat <ccc111-hash> --json
{
"data": {
"type": "tree",
"date": "2014-09-20 12:44:06Z",
"message": "This is a commit message."
}, "links": [
{ "hash": "<ccc000-hash>",
"name": "parent", "size": 25309 },
{ "hash": "<ttt111-hash>",
"name": "object", "size": 5198 },
{ "hash": "<aaa111-hash>",
"name": "author", "size": 109 }
]
}
$ ipfs file-cat <ttt111-hash> --json
{
"data": ["tree", "tree", "blob"],
"links": [
{ "hash": "<ttt222-hash>",
"name": "ttt222-name", "size": 1234 },
{ "hash": "<ttt333-hash>",
"name": "ttt333-name", "size": 3456 },
{ "hash": "<bbb222-hash>",
"name": "bbb222-name", "size": 22 }
]
}
$ ipfs file-cat <bbb222-hash> --json
{ "data": "blob222 data", "links": [] }
5. 버전 관리
IPFS 버전 제어는 Git 위에 구현되며, Git 버전 제어는 이전 장에서 다루었습니다. commit 객체는 기록 버전의 객체 스냅 샷을 나타냅니다. 서로 다른 두 commit 간에 객체 데이터를 비교하면 두 버전의 파일 시스템 간 차이가 나타납니다. IPFS 는 Git 버전 제어 도구의 모든 기능을 구현하며 Git 과도 호환됩니다.
호환성의 이유는 다음과 같습니다.
- Git 도구 버전을 사용하여 마이그레이션된 IPFS
- IPFS 는 FUSE 파일 시스템을 마운트합니다. Git 저장소로 IPFS tree 마운트하고 Git 파일 시스템을 IPFS 형식으로 변환
6. 파일 시스템 경로
MerkleDAG 에서 문자열 경로 API 를 사용하여 IPFS 객체를 순회 할 수 있음을 알 수 있습니다. IPFS 파일 객체는 IPFS 를 UNIX 파일 시스템에 쉽게 마운트 할 수 있도록 고안되었습니다.
7. 파일을 list 와 blob 으로 분할
대용량 파일의 버전 관리 및 배포의 주된 과제는 파일을 별도의 블록으로 분리하는 올바른 방법을 찾는 것입니다. IPFS 가 각기 다른 유형의 파일에 대해 올바른 분리 방법을 제공하기 위해 다음 옵션을 제공합니다.
Rabin Fingerprints 알고리즘을 사용하여 적절한 블록 경계를 정의합니다. rsync 및 rolling-checksum 알고리즘을 사용하여 버전 간 블록 변경을 감지합니다. 사용자가 파일 크기를 설정하고 데이터 블록의 분할 전략을 조정할 수 있습니다.
8. 경로 찾기 성능
경로 기반 액세스는 전체 개체 그래프를 탐색해야하며 각 개체를 검색하려면 DHT 에서 key 값을 찾고 피어에 연결하고 해당 데이터 블록을 검색해야 합니다. 조회되는 경로에 여러 경로가있는 경우 특히 상당한 성능 오버 헤드가 발생합니다. IPFS 는 이것을 고려하여 다음과 같은 방법으로 완화 할 수 있습니다.
- tree chche: 모든 객체는 해시 주소가 지정되므로 무기한으로 캐시 될 수 있으며 tree 는 일반적으로 작기 때문에 blob 과 IPFS 는 tree 를 먼저 캐시합니다.
- flattened trees: 특정 tree 의 경우 모든 오브젝트에 액세스 할 수 있는 링크 된 목록을 작성할 수 있습니다. flat tree 에서 name 은 원래 tree 에서 분리 된 경로로 구분됩니다.
예) 위의 ttt111 에 대한 flat tree 는 다음과 같습니다:
{
"data":["tree","blob","tree","list","blob","blob"],
"links":[
{"hash":"<ttt222-hash>","size":1234,"name":"ttt222-name"},
{"hash":"<bbb111-hash>","size":123,"name":"ttt222-name/bbb111-name"},
{"hash":"<ttt333-hash>","size":3456,"name":"ttt333-name"},
{"hash":"<lll111-hash>","size":578,"name":"ttt333-name/lll111-name"},
{"hash":"<bbb222-hash>","size":22,"name":"ttt333-name/lll111-name/bbb222-name"},
{"hash":"<bbb222-hash>","size":22,"name":"bbb222-name"},
]
}
IPFS - object
IPFS 기본 - Object 계층
IPFS 객체 계층은 저장소 계층입니다. Git 에서 사용하는 저장소 데이터 구조를 기반으로 IPFS 는 MerkleDAG 기술을 사용하여 객체 데이터 (일반적으로 Base58 로 인코딩 된 해시 참조)를 저장하기 위한 DAG 데이터 구조를 구성합니다. 이 데이터 구조의 특성은 다음과 같습니다:
- Content Addressable: 모든 콘텐츠가 다중 해시되고 고유하게 식별
- 변조 방지: 모든 컨텐츠가 해시되며 데이터가 변조되면 IPFS 네트워크가 감지
- 중복 제거: 동일한 내용은 동일한 해시를 가지며 한 번만 저장되므로 인덱싱 객체에 특히 유용
IPFS 객체의 구조는 다음과 같습니다:
type IPFSLink struct {
Name string // 이 링크의 별칭
Hash Multihash // 타겟 해시
Size int // 총 타겟 크기
}
type IPFSObject struct {
links []IPFSLink // 링크 배열
data []byte // 불투명 콘텐츠 데이터
}
ipfs object links <객체 hash> 를 실행하면 그 객체 아래의 모든 IPFSLink 엔트리가 나열됩니다. 즉, IPFSLink 는 객체를 구성합니다.
$ ipfs object links QmZV47ZKbJ1DCLoHWHGhXZ4EMqsyTsZRJUsZuRwEAoiesn
QmUEHn7UnFyFMpJwkvotwuejnMX8XEkqxNsXMeDXJtiJyf 8019571 IZONE_violeta.mp4
QmaFN5uLVBujrsQ6HFzToxUAbtV9z7MfvCtmLrscS9npf3 52173 IZONE_LaViAnRose.jpeg
QmXd18A2gF1rDbNntsDTX48jexiytU7Wi3dT1rWcqNKjeV 71 IZONE
출력의 구조 타입은 <object multihash> <object size> <link name> 으로 표현되는 IPFSLink 의 구조 내용입니다.
1. 경로
IPFS 대상은 하나의 문자열에 대한 경로를 쿼리할 수 있으며 경로는 전통적인 UNIX 파일 시스템에 있는 경로와 마찬가지로 MerkleDAG 의 links 로 로깅을 단순화 합니다.
# 형식
/ipfs/<hash-of-object>/<name-path-to-object>
# 사용예
/ipfs/XLYkgq61DyaQ8Nhkcqyu7rcnSa7dSHQ16x/foo.txt
IPFS 개체는 다중 경로도 지원합니다.
/ipfs/<hash-of-foo>/bar/baz
/ipfs/<hash-of-bar>/baz
/ipfs/<hash-of-baz>
2. 로컬 객체
IPFS 노드에는 하드 디스크 저장소 또는 데이터를 저장하는 블록을 캐시하기 위한 로컬 저장소가 있습니다. 예) 데이터를 업로드 할 때 블록 데이터는 저장소의 하드 디스크 공간에 저장됩니다. 네트워크에서 일부 데이터를 다운로드하는 경우 블록 데이터가 저장소에 캐시됩니다.
3. 객체 잠금
일부 오브젝트의 데이터는 저장소에 캐시됩니다. IPFS 는 pin 옵션으로 로컬에 데이터를 영구 저장하며 관련 파생 오브젝트를 모두 재귀적으로 잠글 수 있습니다. 이것은 특히 완전한 객체 파일을 장기간 저장하는 데 유용합니다.
4. 객체 게시
IPFS 는 전 세계적으로 분산 된 파일 시스템으로 DHT 는 콘텐츠 해싱 기술을 사용하여 게시할 객체를 공정하고 안전하게 분산시킵니다. 누구나 객체를 게시 할 수 있으며 객체의 키를 DHT 에 추가하면 객체가 P2P 전송에 의해 추가 된 다음 다른 사용자의 액세스 경로로 추가됩니다.
5. 객체 레벨 암호화
IPFS 객체를 먼저 암호화하여 새 객체를 만든 다음 새 객체를 저장할 수 있습니다. 암호화 된 객체의 구조는 다음과 같습니다:
type EncryptedObject struct {
Object []bytes // 암호화 된 원시 객체 데이터
Tag []bytes // 선택적 암호화 식별자
type SignedObject struct {
Object []bytes // 서명 된 원시 객체 데이터
Signature []bytes // HMAC 서명
PublicKey []multihash // 다중 해시 식별 키
}
}
이것이 블록 체인 스토리지에 적용되는 이유입니다. 블록 체인은 공개 키로 객체를 암호화하여 새 객체를 얻은 다음 객체를 IPFS 네트워크에 저장하여 IPFS 해시 값을 얻습니다. 블록 체인은 해시 값만 저장합니다. 데이터를 얻을 때 먼저 IPFS 해시 값을 사용하여 암호화 된 객체를 가져온 다음 실제 데이터 객체를 얻기 위해 자체 개인 키로 객체를 해독합니다.
IPFS - exchange
IPFS 기본 - Exchange 계층
IPFS 의 스위칭 레이어는 BitSwap 프로토콜을 통해 피어 노드간에 데이터를 교환합니다. BitTorrent 와 마찬가지로 각 피어 노드는 다운로드하는 동안 다운로드 된 데이터를 다른 피어 노드에 업로드합니다. BitTorrent 프로토콜과 달리 BitSwap 은 시드 파일의 데이터블록에만 국한되지 않습니다.
전체 교환 계층에서 IPFS 의 모든 노드가 마켓을 이루고 있으며 데이터 교환은 Filecoin 이 교환 계층에서 인센티브 계층을 추가합니다. 이 마켓에서 Bitswap 은 두 가지 주요 작업을 수행합니다. 즉, 데이터 블록을 제공하는 피어에 이득 (Filecoin 에서는 코인) 을 주기위한 마켓입니다.
- 네트워크에서 클라이언트 요청 블록을 가져 오기위한 시도
- 소유 블록을 다른 노드로 보냅니다
1. BitSwap 프로토콜
BitSwap 은 IPFS 노드의 블록 교환 정보를 기록합니다. 소스 코드 구조는 다음과 같습니다:
// Additional state kept
type BitSwap struct {
ledgers map[NodeId]Ledger
// Ledgers known to this node, inc inactive
// 노드 명세
active map[NodeId]Peer
// currently open connections to other nodes
// 현재 연결된 피어
need_list []Multihash
// checksums of blocks this node needs
// 노드가 필요한 블록 데이터 검사 목록
have_list []Multihash
// checksums of blocks this node has
// 노드가 가지고 있는 블록 데이터 검사 목록
}
노드가 다른 노드로부터 데이터 블록을 요청하거나 다른 노드에 데이터 블록을 제공 할 필요가 있을 때 다음과 같이 BitSwap 메시지를 보내고 이 메시지는 주로 두 부분으로 구성됩니다. 원하는 데이터 블록 목록 (want_list)과 해당 데이터 블록입니다. 전체 메시지는 Protobuf 를 사용하여 인코딩 됩니다:
message Message {
message Wantlist {
message Entry {
optional string block = 1; // the block key
optional int32 priority = 2; // the priority (normalized). default to 1
// 우선 순위 설정, 기본값 = 1
optional bool cancel = 3; // whether this revokes an entry
// 취소
}
repeated Entry entries = 1; // a list of wantlist entries
optional bool full = 2; // whether this is the full wantlist. default to false
}
optional Wantlist wantlist = 1;
repeated bytes blocks = 2;
}
BitSwap 시스템은 매우 중요한 두 가지 모듈이 있습니다. 요구 사항 관리자 (Want-Manager) 와 의사 결정 엔진 (Decision-Engine) 이 있습니다. Want-Manager 는 노드가 데이터를 요청할 때 로컬로 해당 결과를 리턴하거나 적합한 요청을 발행하고 후자 (Decision-Engine) 는 다른 노드에 자원을 할당하는 방법을 결정합니다. 노드가 want_list 를 포함하는 메시지를 수신하면 메시지는 의사 결정 엔진으로 전달되고 엔진은 노드의 BitSwap 명세서는 요청을 처리하는 방법을 결정합니다. 전체 프로세스는 다음과 같습니다.
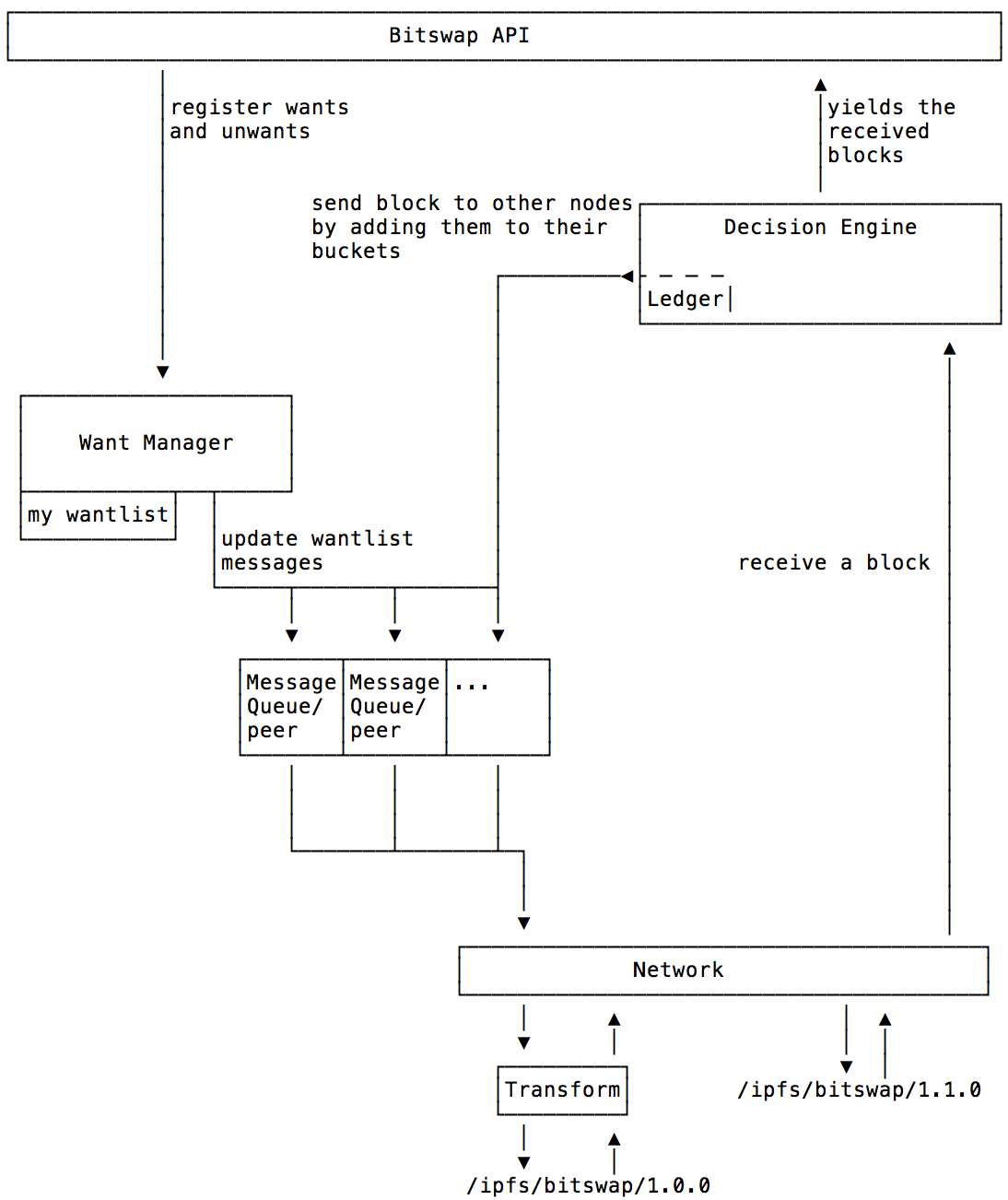
위의 프로토콜 흐름도를 통해 BitSwap 데이터 교환의 전체 과정과 peer-to-peer 연결의 수명주기를 볼 수 있습니다. 이 라이프 사이클에서 피어 노드는 일반적으로 네 가지 상태를 거칩니다:
- Open: 전송할 BitSwap 명세 상태는 연결이 설정 될 때까지 피어 노드간에 열립니다.
- Sending: want_list 및 데이터 블록은 피어 노드간에 전송됩니다.
- Close: 피어 노드는 데이터를 보낸 후에 연결을 끊습니다.
- Ignored: 피어 노드는 타임 아웃, 자동 및 낮은 크레딧과 같은 요인으로 인해 무시됩니다.
피어 노드의 소스 구조를 결합하여 IPFS 노드가 서로를 찾는 방식을 분석합니다:
type Peer struct {
nodeid NodeId
ledger Ledger
// Ledger between the node and this peer
// 노드와 피어 노드 간의 청구 명세서
last_seen Timestamp
// timestamp of last received message
// 마지막으로받은 메시지의 타임 스탬프
want_list []Multihash
// checksums of all blocks wanted by peer
// includes blocks wanted by peer's peers
// 모든 블록 검사 필요
}
// Protocol interface:
interface Peer {
open (nodeid :NodeId, ledger :Ledger);
send_want_list (want_list :WantList);
send_block (block :Block) -> (complete :Bool);
close (final :Bool);
}
1.1 Peer.open(NodeID,Ledger)
노드가 연결을 설정하면 보낸 노드는 BitSwap 명세서를 초기화 합니다. 피어에 대한 명세서를 보관할 수 있습니다. 새 명세서를 새로 만들 수도 있습니다. 이는 노드 청구 일관성 문제에 따라 다릅니다. 송신 노드는 수신 노드에 통지하기 위해 청구서를 담고있는 공개 메시지를 전송할 것입니다. 수신 노드가 Open 메시지를 수신 한 후 이 연결 요청을 수락할지 여부를 선택할 수 있습니다.
수신자는 송신자의 로컬 명세 데이터를 체크하는데 신뢰할 수 없는 노드를 판명합니다. 즉 전송 타임 아웃, 매우 낮은 신용 점수 및 큰 부채 비율에 기초하여 신뢰할 수 없는 노드인 것으로 판명되면 수신기는 ignore_cooldown 을 통해 이 요청을 무시하여 연결을 끊습니다. 이 목적은 부정 행위를 방지하는 것입니다.
연결이 성공하면 수신자는 로컬 명세서를 사용하여 피어 개체를 초기화하고 last_seen 타임 스탬프를 업데이트 한 다음 수신 된 명세서를 자체 명세서와 비교합니다.
두 명세서가 정확히 같으면 연결이 Open 하고 명세가 정확히 동일하지 않은 경우 노드는 새로운 명세서를 생성하고 이 명세서에 동기화를 전송합니다. 이는 앞에서 언급한 송신자 노드와 수신자 노드의 명세 일관성 문제를 보장합니다.
1.2 Peer.send_want_list(WantList)
연결이 이미 Open 상태에 있으면 송신자 노드는 want_list 를 연결된 모든 수신 노드에 브로드캐스트합니다. 동시에 want_list 를 수신 한 후 수신 노드는 수신자가 원하는 데이터 블록이 있는지 여부를 확인한 다음 BitSwap 정책을 사용하여 데이터 블록을 보내고 전송합니다.
1.3 Peer.send_block(Block)
블록을 보내는 방법 로직은 매우 간단합니다. 기본적으로 송신 노드는 데이터 블록만 전송합니다. 모든 데이터를 수신 한 후 수신 노드는 Multihash 를 계산하여 예상되는 것과 일치하는지 확인한 다음 수신 확인을 반환합니다. 블록 전송을 완료 한 후, 수신 노드는 블록 정보를 need_list 에서 have_list 로 이동시키고 수신 노드와 송신 노드 모두 명세서 목록을 동시에 갱신한다. 전송 확인이 실패하면 전송 노드가 오작동하거나 의도적으로 수신 노드의 행동을 공격 할 수 있으며 수신 노드는 추가 거래를 거부 할 수 있습니다.
1.4 Peer.close(Bool)
peer-to-peer 연결은 두 가지 경우에 닫아야 합니다.
- silent_want (시간초과): 상대방으로 부터 메시지를 받지 못했을 때 노드는
Peer.close (false)를 발행 - BitSwap 종료 (노드 종료): 노드는
Peer.close (true)발행
P2P 네트워크의 경우 ‘모든 사람들이 자신의 데이터를 공유하도록 동기를 부여하는 방법’ 및 ‘P2P 소프트웨어의 자체 데이터 공유 전략을 이용하는 방법’ 이 있습니다. IPFS 에서도 마찬가지입니다. 그 중 BitSwap 전략 시스템은 ‘신용’, ‘전략’ 및 ‘명세서’ 의 세 부분으로 구성됩니다.
2. BitSwap 신뢰 시스템
BitSwap 프로토콜은 노드가 데이터를 공유하도록 동기를 부여 할 수 있어야 합니다. IPFS 는 노드 간의 데이터 전송 및 수신을 기반으로 신용 시스템을 구축합니다.
- 다른 노드로 데이터를 보내면 신용도가 증가합니다.
- 다른 노드로부터 데이터를 수신하면 신용도가 낮아집니다.
노드가 데이터만 수신하고 데이터를 업로드하지 않으면 신용도는 다른 노드에 의해 낮추어 집니다. 이것은 사이버 공격을 효과적으로 방지 할 수 있습니다.
3. BitSwap 정책
BitSwap 신용 시스템으로 서로 다른 정책으로 구현할 수 있습니다. 각 정책은 시스템의 전반적인 성능에 다른 영향을줍니다. 정책의 목표는 다음과 같습니다:
- 노드 데이터 교환의 전반적인 성능과 효율성이 가장 높습니다.
- 데이터를 다운로드만 하고 업로드하지 않는 현상을 방지합니다.
- 일부 공격을 효과적으로 방지합니다.
- 신뢰할 수 있는 노드에 대해 느슨한 메커니즘을 설정합니다.
IPFS 는 whitepaper 에서 몇 가지 참조 정책 메커니즘을 제공합니다. 각 노드는 다른 노드가 주고받는 데이터를 기반으로 신용 및 부채 비율 (rb) 을 계산합니다: r = bytes_sent / bytes_recv + 1
데이터 전송 속도 (P):
P (send | r) = 1 - (1 / (1 + exp (6-3r)))
| 위 합의에 따르면 r 이 2 보다 크면 전송률 _P (send | r)_ 가 작아 지므로 다른 노드는 데이터를 계속 보내지 않습니다. |
4. BitSwap 명세
BitSwap 노드는 다른 노드와 통신하는 명세서 (데이터 송수신 레코드) 를 기록합니다. 명세 데이터 구조는 다음과 같습니다.
type Ledger struct {
owner NodeId
partner NodeId
bytes_sent int
bytes_recv int
timestamp Timestamp
}
이를 통해 노드는 변조를 피하기 위해 히스토리를 추적 할 수 있습니다. 두 노드간에 연결이 이루어지면 BitSwap 은 서로 결제 정보를 교환하고 원장이 일치하지 않으면 원장은 지워지고 다시 예약되며 악의적 노드는 이 원장을 잃어 버리고 채무를 청산 할 것으로 예상됩니다. 다른 노드는 이것을 기록 할 것이며 파트너 노드는 위법 행위로 취급하여 거래를 거부 할 수 있습니다.
IPFS - routing
IPFS 기본 - Routing 계층
이 계층에서는 이전에 살짝 이야기 된 분산 해시 테이블인 DHT 를 알아보고자 합니다. 각 노드에는 NodeID 라는 고유 ID 가 있습니다. 네트워크 거리 및 대기 시간을 기반으로 라우팅 테이블을 생성합니다. DHT 분산 해쉬 테이블은 피어 노드가 소유 한 데이터에 따라 생성되고 테이블의 key 는 파일 내용의 해시값이며 value 는 데이터에 해당하는 노드 NodeID 입니다.
노드가 IPFS 네트워크에 참여하면 시드 노드를 통해 다른 많은 피어 노드 정보를 수신하고 호스트는 이러한 노드를 연결하고 ping 시간 및 노드 거리에 따라 라우팅 테이블을 구성합니다. 라우팅 테이블은 여러 개의 k-버킷으로 구성되며 k-버킷은 로컬 노드의 NodeID 수에 따라 분산됩니다. 예) 내 노드가 01011이고 k-버킷의 값이 5 (k = 5) 이면 가까운 버켓과 먼 버킷의 k-버킷 분포는 다음과 같습니다:
- k1 : 01010
- K2 : 01000, 01001
- K3 : 01110, 01111, 01100, 01101
- k4 : 00 으로 시작하는 노드
k-버킷의 노드는 ping 지연 시간에 의해 3 개의 계층으로 더 나누어진다. 3 계층은 각각 20 밀리 초, 60 밀리 초, 그 이상의 지연이다.
노드가 데이터를 저장할 때 데이터는 로컬 노드 IPFS 저장소에 직접 저장됩니다. 설정 데이터의 해시값은 key 이며 key 근처의 다른 노드로 브로드캐스팅되어 key 데이터를 저장했다는 사실을 알려줍니다. 다른 노드는 이 정보를 저장하고 DHT 테이블을 구성하며 내용은 key/value 저장소이고 key 는 데이터 해시값이며 value 는 정보를 저장하는 노드입니다.
노드가 키 데이터를 검색 할 때, 먼저 자신의 blockstore 를 검색합니다. key 에 가장 가까운 k-버킷에 쿼리가 없으면 내부 노드는 자체 DHT 테이블에서 쿼리합니다. key 에 대한 value 가 있으면 피드백이 반환되고 그렇지 않으면 key 에 가장 가까운 노드가 제공됩니다.
IPFS 의 DSHT 구조는 저장된 데이터의 크기에 따라 차별화 됩니다. 작은 값 (1KB 이하) 은 DHT 에 직접 저장되며 큰 값의 경우 DHT 는 인덱스만 저장합니다. 이 인덱스는 피어 노드의 NodeId 이며 피어 노드는 유형값에 대한 특정 서비스를 제공 할 수 있습니다. DSHT 의 인터페이스는 다음의 libp2p 모듈에 있습니다:
type IPFSRouting interface {
FindPeer (node NodeId)
// gets a particular peer’s network address
// 특정 노드 네트워크 주소 가져 오기
SetValue (key[]bytes, value []bytes)
// stores a small meta data value in DHT
// DHT 테이블을 통해 더 작은 메타 파일 저장
GetValue (key[]bytes)
// retrieves small meta data value from DHT
// DHT 테이블에서 메타 파일 검색
ProvideValue (key Multihash)
// announces this node can serve a large value
// 노드를 브로드캐스트하여 메타 파일에 해당하는 데이터 제공
FindValuePeers (key Multihash, min int)
// gets a number of peers serving a large value
// 데이터 제공 노드 정보 얻기
}
IPFS - network
IPFS 기본 - Network 계층
네트워크 계층은 IPFS 의 libp2p 모듈입니다. 모듈에는 다음이 포함됩니다:
- Transports: 전송 계층
- Discovery: 네트워크 검색 레이어
- Peer Routing: 노드 라우팅
- NAT Traversal: NAT 레이어
- Content Routing: 콘텐츠 기반 주소 지정

네트워크 계층의 역할은 IPFS 노드가 다양한 기본 네트워크 프로토콜 (구성 가능) 을 사용하여 다른 노드에 대한 연결을 관리하고 이들이 정기적으로 통신하는지 확인하는 것입니다.
이 계층은 전체 IPFS 에 대한 기본 네트워크 장비 또는 네트워크 기능을 제공할 뿐만 아니라 암호화 전송, 네트워크 침투, 다중 링크 혼합 및 기타 기술을 추가합니다.
IPFS 노드가 다른 노드에 연결 되면 WAN 을 통과하고 IPFS 네트워크 스택의 기능은 다음과 같습니다:
- 전송 : IPFS 는 브라우저에서 사용하는 WebRTC 데이터 채널, LED BLAT (Low Latency UTP) 전송 프로토콜 등에 가장 적합한 기존 주류 전송 프로토콜과 호환됩니다.
- 신뢰성: uTP 및 SCTP를 사용하여 두 프로토콜이 네트워크 상태를 동적으로 조정할 수 있도록 보장 합니다.
- 연결성: ICE 와 같은 NAT 교차 기술을 사용하여 광역 네트워크 연결성을 달성 합니다.
- 무결성: 해시 검사를 사용하여 데이터 무결성을 검사합니다 . IPFS 의 모든 데이터 블록에는 고유 해시가 있습니다.
- 검증 가능성: 데이터 송신자의 공개 키 및 HMAC 메시지 인증 코드를 사용하여 메시지의 신뢰성을 검사합니다.
IPFS 는 모든 네트워크를 사용할 수 있으며 IP 에 의존하지 않습니다. 이를 통해 IPFS 를 사용하여 전체 네트워크를 포괄 할 수 있습니다. IPFS 는 향후 나타날 수 있는 다른 네트워크 프로토콜과 호환 및 확장에 사용되는 대상 주소와 프로토콜을 나타내는 multiaddr 형식을 사용합니다.
# an SCTP/IPv4 connection
/ip4/10.20.30.40/sctp/1234/
# an SCTP/IPv4 connection proxied over
TCP/IPv4/ip4/5.6.7.8/tcp/5678/ip4/1.2.3.4/sctp/1234/
